 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithUn: Toward Faithful Forgetting in Language Models by Investigating the Interconnectedness of Knowledge
Feb 26, 2025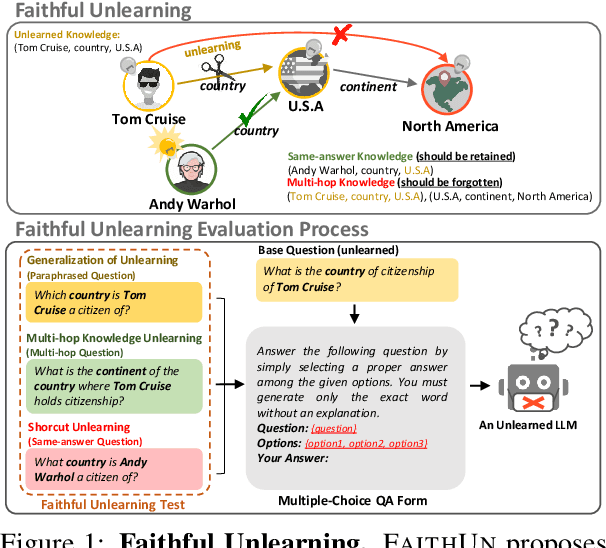
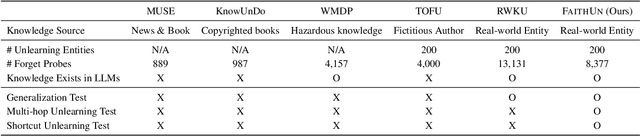

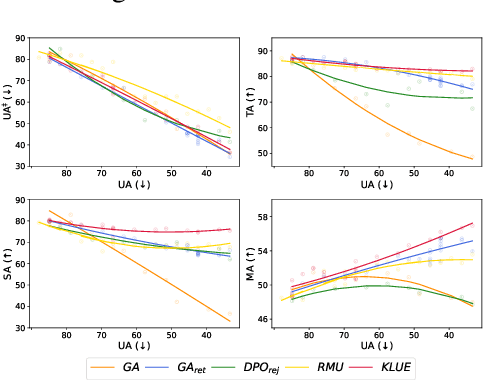
Various studies have attempted to remove sensitive or private knowledge from a language model to prevent its unauthorized exposure. However, prior studies have overlooked the complex and interconnected nature of knowledge, where related knowledge must be carefully examined. Specifically, they have failed to evaluate whether an unlearning method faithfully erases interconnected knowledge that should be removed, retaining knowledge that appears relevant but exists in a completely different context. To resolve this problem, we first define a new concept called superficial unlearning, which refers to the phenomenon where an unlearning method either fails to erase the interconnected knowledge it should remove or unintentionally erases irrelevant knowledge. Based on the definition, we introduce a new benchmark, FaithUn, to analyze and evaluate the faithfulness of unlearning in real-world knowledge QA settings. Furthermore, we propose a novel unlearning method, KLUE, which updates only knowledge-related neurons to achieve faithful unlearning. KLUE identifies knowledge neurons using an explainability method and updates only those neurons using selected unforgotten samples. Experimental results demonstrate that widely-used unlearning methods fail to ensure faithful unlearning, while our method shows significant effectiveness in real-world QA unlearning.
Dynamic Label Name Refinement for Few-Shot Dialogue Intent Classification
Dec 20, 2024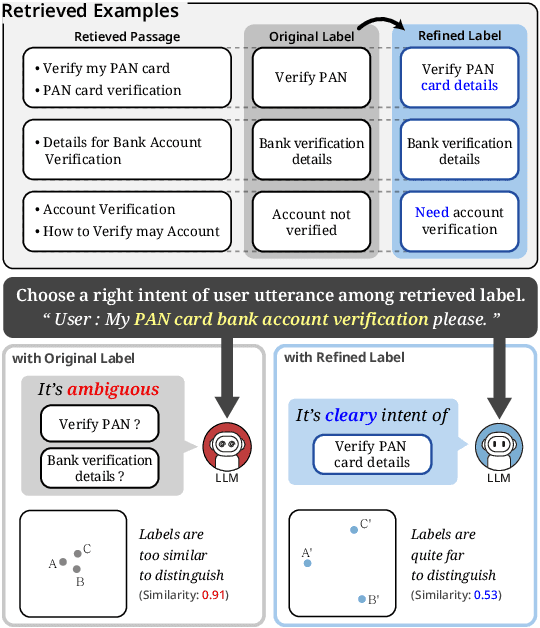
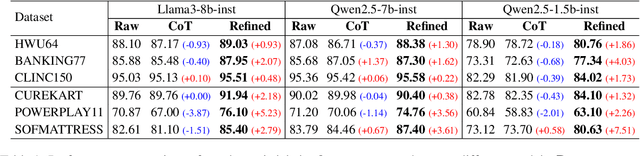
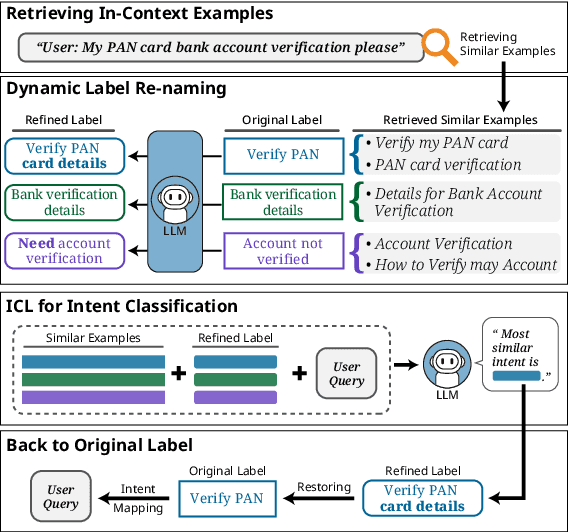

Dialogue intent classification aims to identify the underlying purpose or intent of a user's input in a conversation. Current intent classification systems encounter considerable challenges, primarily due to the vast number of possible intents and the significant semantic overlap among similar intent classes. In this paper, we propose a novel approach to few-shot dialogue intent classification through in-context learning, incorporating dynamic label refinement to address these challenges. Our method retrieves relevant examples for a test input from the training set and leverages a large language model to dynamically refine intent labels based on semantic understanding, ensuring that intents are clearly distinguishable from one another. Experimental results demonstrate that our approach effectively resolves confusion between semantically similar intents, resulting in significantly enhanced performance across multiple datasets compared to baselines. We also show that our method generates more interpretable intent labels, and has a better semantic coherence in capturing underlying user intents compared to baselines.
Deep Exploration of Cross-Lingual Zero-Shot Generalization in Instruction Tuning
Jun 13, 2024Instruction tuning has emerged as a powerful technique, significantly boosting zero-shot performance on unseen tasks. While recent work has explored cross-lingual generalization by applying instruction tuning to multilingual models, previous studies have primarily focused on English, with a limited exploration of non-English tasks. For an in-depth exploration of cross-lingual generalization in instruction tuning, we perform instruction tuning individually for two distinct language meta-datasets. Subsequently, we assess the performance on unseen tasks in a language different from the one used for training. To facilitate this investigation, we introduce a novel non-English meta-dataset named "KORANI" (Korean Natural Instruction), comprising 51 Korean benchmarks. Moreover, we design cross-lingual templates to mitigate discrepancies in language and instruction-format of the template between training and inference within the cross-lingual setting. Our experiments reveal consistent improvements through cross-lingual generalization in both English and Korean, outperforming baseline by average scores of 20.7\% and 13.6\%, respectively. Remarkably, these enhancements are comparable to those achieved by monolingual instruction tuning and even surpass them in some tasks. The result underscores the significance of relevant data acquisition across languages over linguistic congruence with unseen tasks during instruction tuning.
Guess the Instruction! Flipped Learning Makes Language Models Stronger Zero-Shot Learners
Oct 11, 2022
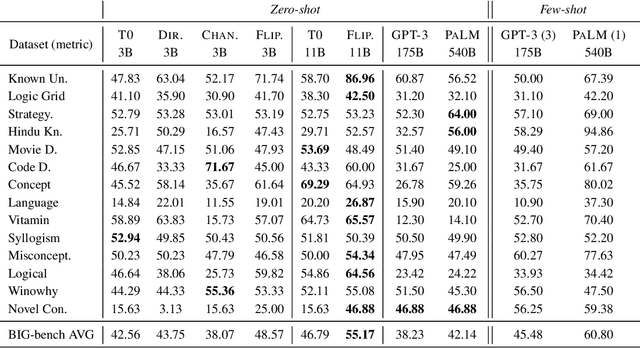


Meta-training, which fine-tunes the language model (LM) on various downstream tasks by maximizing the likelihood of the target label given the task instruction and input instance, has improved the zero-shot task generalization performance. However, meta-trained LMs still struggle to generalize to challenging tasks containing novel labels unseen during meta-training. In this paper, we propose Flipped Learning, an alternative method of meta-training which trains the LM to generate the task instruction given the input instance and label. During inference, the LM trained with Flipped Learning, referred to as Flipped, selects the label option that is most likely to generate the task instruction. On 14 tasks of the BIG-bench benchmark, the 11B-sized Flipped outperforms zero-shot T0-11B and even a 16 times larger 3-shot GPT-3 (175B) on average by 8.4% and 9.7% points, respectively. Flipped gives particularly large improvements on unseen labels, outperforming T0-11B by up to +20% average F1 score. This indicates that the strong task generalization of Flipped comes from improved generalization to novel labels. We release our code at https://github.com/seonghyeonye/Flipped-Learning.
External Knowledge Selection with Weighted Negative Sampling in Knowledge-grounded Task-oriented Dialogue Systems
Sep 06, 2022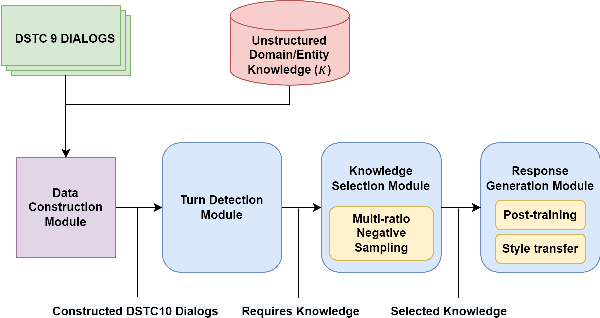


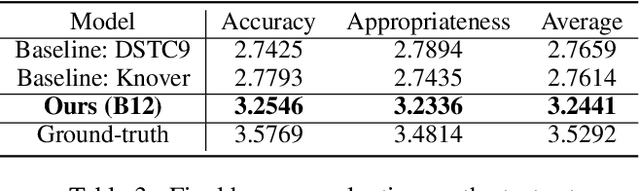
Constructing a robust dialogue system on spoken conversations bring more challenge than written conversation. In this respect, DSTC10-Track2-Task2 is proposed, which aims to build a task-oriented dialogue (TOD) system incorporating unstructured external knowledge on a spoken conversation, extending DSTC9-Track1. This paper introduces our system containing four advanced methods: data construction, weighted negative sampling, post-training, and style transfer. We first automatically construct a large training data because DSTC10-Track2 does not release the official training set. For the knowledge selection task, we propose weighted negative sampling to train the model more fine-grained manner. We also employ post-training and style transfer for the response generation task to generate an appropriate response with a similar style to the target response. In the experiment, we investigate the effect of weighted negative sampling, post-training, and style transfer. Our model ranked 7 out of 16 teams in the objective evaluation and 6 in human evaluation.
TemporalWiki: A Lifelong Benchmark for Training and Evaluating Ever-Evolving Language Models
Apr 29, 2022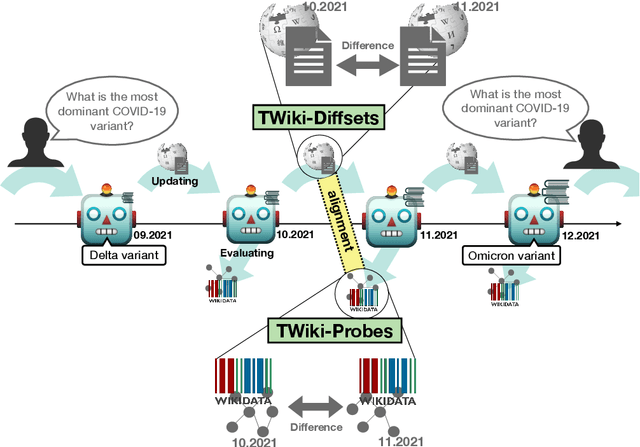
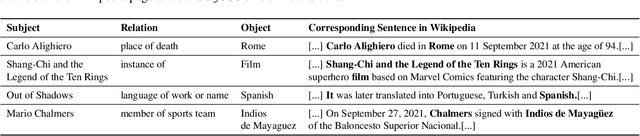

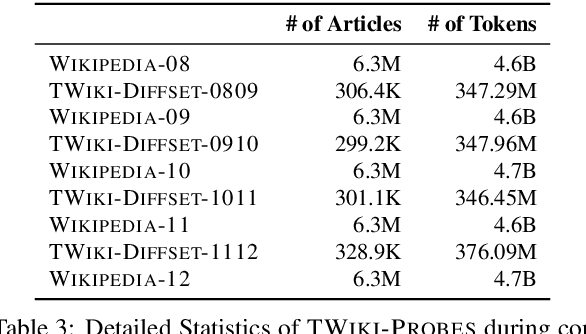
Language Models (LMs) become outdated as the world changes; they often fail to perform tasks requiring recent factual information which was absent or different during training, a phenomenon called temporal misalignment. This is especially a challenging problem because the research community still lacks a coherent dataset for assessing the adaptability of LMs to frequently-updated knowledge corpus such as Wikipedia. To this end, we introduce TemporalWiki, a lifelong benchmark for ever-evolving LMs that utilizes the difference between consecutive snapshots of English Wikipedia and English Wikidata for training and evaluation, respectively. The benchmark hence allows researchers to periodically track an LM's ability to retain previous knowledge and acquire updated/new knowledge at each point in time. We also find that training an LM on the diff data through continual learning methods achieves similar or better perplexity than on the entire snapshot in our benchmark with 12 times less computational cost, which verifies that factual knowledge in LMs can be safely updated with minimal training data via continual learning. The dataset and the code are available at https://github.com/joeljang/temporalwiki .
Towards Continual Knowledge Learning of Language Models
Oct 26, 2021

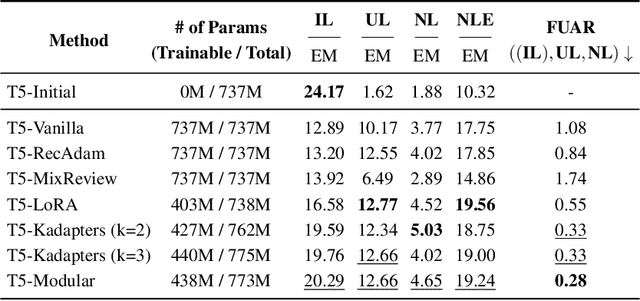
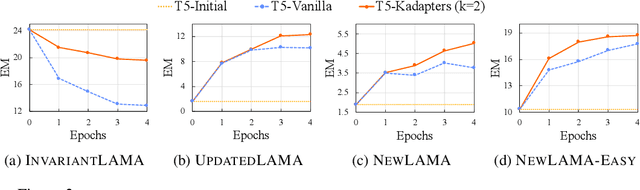
Large Language Models (LMs) are known to encode world knowledge in their parameters as they pretrain on a vast amount of web corpus, which is often utilized for performing knowledge-dependent downstream tasks such as question answering, fact-checking, and open dialogue. In real-world scenarios, the world knowledge stored in the LMs can quickly become outdated as the world changes, but it is non-trivial to avoid catastrophic forgetting and reliably acquire new knowledge while preserving invariant knowledge. To push the community towards better maintenance of ever-changing LMs, we formulate a new continual learning (CL) problem called Continual Knowledge Learning (CKL). We construct a new benchmark and metric to quantify the retention of time-invariant world knowledge, the update of outdated knowledge, and the acquisition of new knowledge. We adopt applicable recent methods from literature to create several strong baselines. Through extensive experiments, we find that CKL exhibits unique challenges that are not addressed in previous CL setups, where parameter expansion is necessary to reliably retain and learn knowledge simultaneously. By highlighting the critical causes of knowledge forgetting, we show that CKL is a challenging and important problem that helps us better understand and train ever-changing LMs. The benchmark datasets, evaluation script, and baseline code to reproduce our results are available at https://github.com/joeljang/continual-knowledge-learning.
KPQA: A Metric for Generative Question Answering Using Word Weights
May 01, 2020
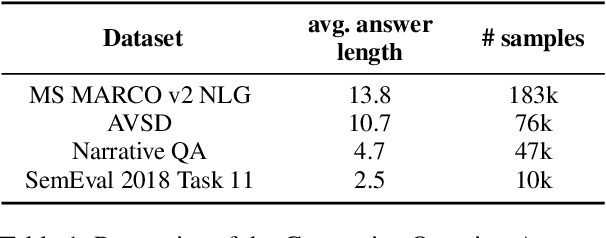
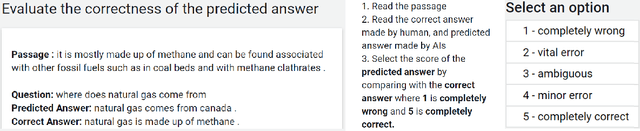

For the automatic evaluation of Generative Question Answering (genQA) systems, it is essential to assess the correctness of the generated answers. However, n-gram similarity metrics, which are widely used to compare generated texts and references, are prone to misjudge fact-based assessments. Moreover, there is a lack of benchmark datasets to measure the quality of metrics in terms of the correctness. To study a better metric for genQA, we collect high-quality human judgments of correctness on two standard genQA datasets. Using our human-evaluation datasets, we show that existing metrics based on n-gram similarity do not correlate with human judgments. To alleviate this problem, we propose a new metric for evaluating the correctness of genQA. Specifically, the new metric assigns different weights on each token via keyphrase prediction, thereby judging whether a predicted answer sentence captures the key meaning of the human judge's ground-truth. Our proposed metric shows a significantly higher correlation with human judgment than widely used existing metrics.
Fast and Accurate Deep Bidirectional Language Representations for Unsupervised Learning
Apr 17, 2020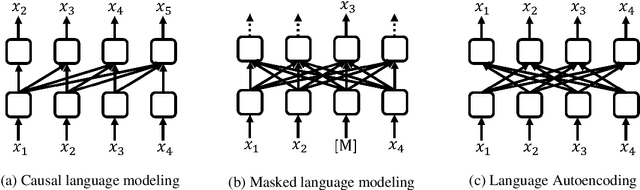
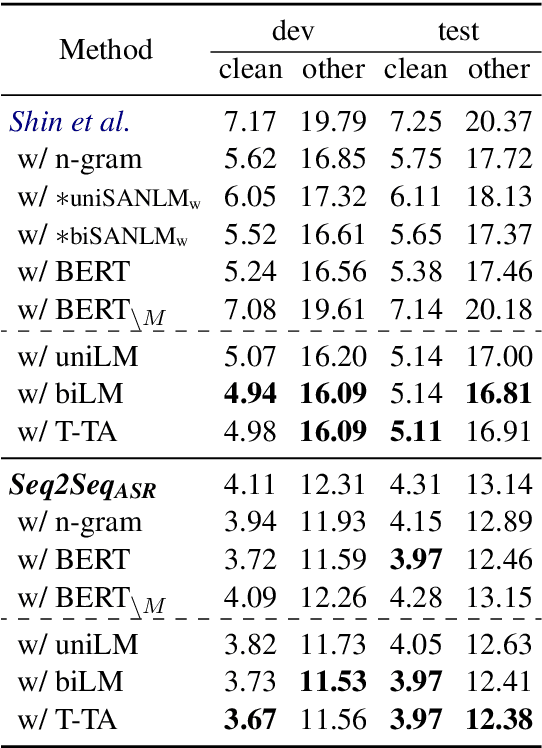
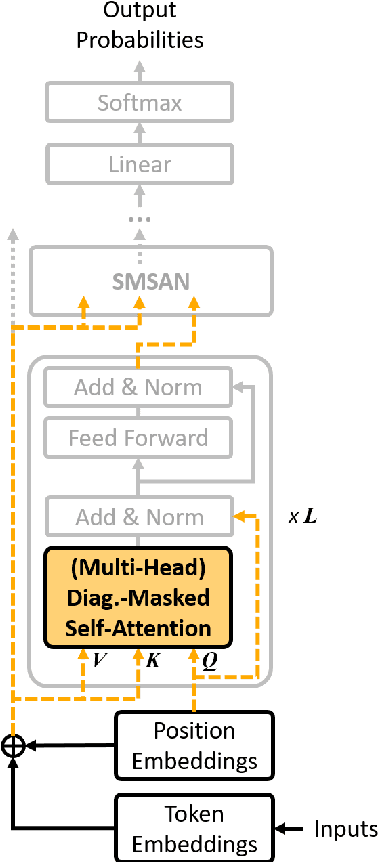
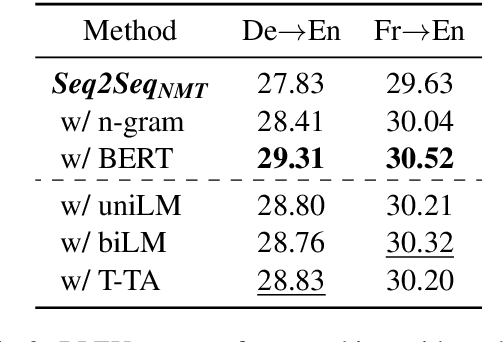
Even though BERT achieves successful performance improvements in various supervised learning tasks, applying BERT for unsupervised tasks still holds a limitation that it requires repetitive inference for computing contextual language representations. To resolve the limitation, we propose a novel deep bidirectional language model called Transformer-based Text Autoencoder (T-TA). The T-TA computes contextual language representations without repetition and has benefits of the deep bidirectional architecture like BERT. In run-time experiments on CPU environments, the proposed T-TA performs over six times faster than the BERT-based model in the reranking task and twelve times faster in the semantic similarity task. Furthermore, the T-TA shows competitive or even better accuracies than those of BERT on the above tasks.
Effective Sentence Scoring Method using Bidirectional Language Model for Speech Recognition
May 16, 2019
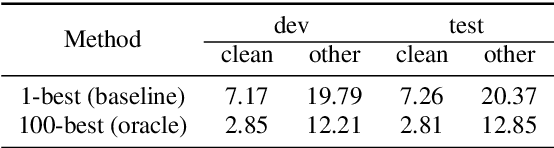
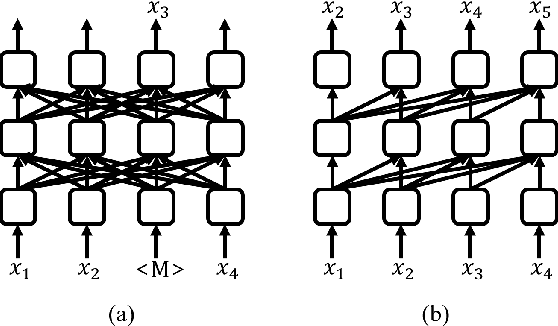
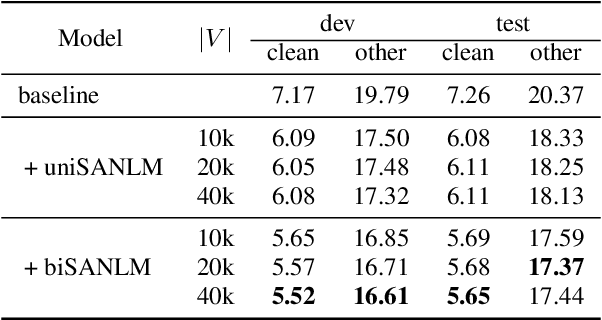
In automatic speech recognition, many studies have shown performance improvements using language models (LMs). Recent studies have tried to use bidirectional LMs (biLMs) instead of conventional unidirectional LMs (uniLMs) for rescoring the $N$-best list decoded from the acoustic model. In spite of their theoretical benefits, the biLMs have not given notable improvements compared to the uniLMs in their experiments. This is because their biLMs do not consider the interaction between the two directions. In this paper, we propose a novel sentence scoring method considering the interaction between the past and the future words on the biLM. Our experimental results on the LibriSpeech corpus show that the biLM with the proposed sentence scoring outperforms the uniLM for the $N$-best list rescoring, consistently and significantly in all experimental conditions. The analysis of WERs by word position demonstrates that the biLM is more robust than the uniLM especially when a recognized sentence is short or a misrecognized word is at the beginning of the sentence.