 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersona Switch: Mixing Distinct Perspectives in Decoding Time
Jan 22, 2026Role-play prompting is known to steer the behavior of language models by injecting a persona into the prompt, improving their zero-shot reasoning capabilities. However, such improvements are inconsistent across different tasks or instances. This inconsistency suggests that zero-shot and role-play prompting may offer complementary strengths rather than one being universally superior. Building on this insight, we propose Persona Switch, a novel decoding method that dynamically combines the benefits of both prompting strategies. Our method proceeds step-by-step, selecting the better output between zero-shot and role-play prompting at each step by comparing their output confidence, as measured by the logit gap. Experiments with widely-used LLMs demonstrate that Persona Switch consistently outperforms competitive baselines, achieving up to 5.13% accuracy improvement. Furthermore, we show that output confidence serves as an informative measure for selecting the more reliable output.
Reliability-Aware Adaptive Self-Consistency for Efficient Sampling in LLM Reasoning
Jan 06, 2026Self-Consistency improves reasoning reliability through multi-sample aggregation, but incurs substantial inference cost. Adaptive self-consistency methods mitigate this issue by adjusting the sampling budget; however, they rely on count-based stopping rules that treat all responses equally, often leading to unnecessary sampling. We propose Reliability-Aware Adaptive Self-Consistency (ReASC), which addresses this limitation by reframing adaptive sampling from response counting to evidence sufficiency, leveraging response-level confidence for principled information aggregation. ReASC operates in two stages: a single-sample decision stage that resolves instances confidently answerable from a single response, and a reliability-aware accumulation stage that aggregates responses by jointly leveraging their frequency and confidence. Across five models and four datasets, ReASC consistently achieves the best accuracy-cost trade-off compared to existing baselines, yielding improved inference efficiency across model scales from 3B to 27B parameters. As a concrete example, ReASC reduces inference cost by up to 70\% relative to self-consistency while preserving accuracy on GSM8K using Gemma-3-4B-it.
Confidence-Guided Stepwise Model Routing for Cost-Efficient Reasoning
Nov 09, 2025Recent advances in Large Language Models (LLMs) - particularly model scaling and test-time techniques - have greatly enhanced the reasoning capabilities of language models at the expense of higher inference costs. To lower inference costs, prior works train router models or deferral mechanisms that allocate easy queries to a small, efficient model, while forwarding harder queries to larger, more expensive models. However, these trained router models often lack robustness under domain shifts and require expensive data synthesis techniques such as Monte Carlo rollouts to obtain sufficient ground-truth routing labels for training. In this work, we propose Confidence-Guided Stepwise Model Routing for Cost-Efficient Reasoning (STEER), a domain-agnostic framework that performs fine-grained, step-level routing between smaller and larger LLMs without utilizing external models. STEER leverages confidence scores from the smaller model's logits prior to generating a reasoning step, so that the large model is invoked only when necessary. Extensive evaluations using different LLMs on a diverse set of challenging benchmarks across multiple domains such as Mathematical Reasoning, Multi-Hop QA, and Planning tasks indicate that STEER achieves competitive or enhanced accuracy while reducing inference costs (up to +20% accuracy with 48% less FLOPs compared to solely using the larger model on AIME), outperforming baselines that rely on trained external modules. Our results establish model-internal confidence as a robust, domain-agnostic signal for model routing, offering a scalable pathway for efficient LLM deployment.
Bilinear relational structure fixes reversal curse and enables consistent model editing
Sep 26, 2025The reversal curse -- a language model's (LM) inability to infer an unseen fact ``B is A'' from a learned fact ``A is B'' -- is widely considered a fundamental limitation. We show that this is not an inherent failure but an artifact of how models encode knowledge. By training LMs from scratch on a synthetic dataset of relational knowledge graphs, we demonstrate that bilinear relational structure emerges in their hidden representations. This structure substantially alleviates the reversal curse, enabling LMs to infer unseen reverse facts. Crucially, we also find that this bilinear structure plays a key role in consistent model editing. When a fact is updated in a LM with this structure, the edit correctly propagates to its reverse and other logically dependent facts. In contrast, models lacking this representation not only suffer from the reversal curse but also fail to generalize edits, further introducing logical inconsistencies. Our results establish that training on a relational knowledge dataset induces the emergence of bilinear internal representations, which in turn enable LMs to behave in a logically consistent manner after editing. This implies that the success of model editing depends critically not just on editing algorithms but on the underlying representational geometry of the knowledge being modified.
Erase or Hide? Suppressing Spurious Unlearning Neurons for Robust Unlearning
Sep 26, 2025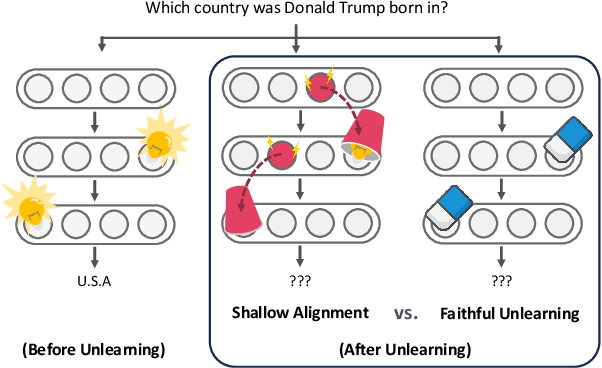


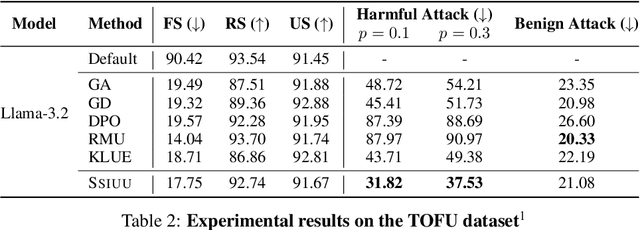
Large language models trained on web-scale data can memorize private or sensitive knowledge, raising significant privacy risks. Although some unlearning methods mitigate these risks, they remain vulnerable to "relearning" during subsequent training, allowing a substantial portion of forgotten knowledge to resurface. In this paper, we show that widely used unlearning methods cause shallow alignment: instead of faithfully erasing target knowledge, they generate spurious unlearning neurons that amplify negative influence to hide it. To overcome this limitation, we introduce Ssiuu, a new class of unlearning methods that employs attribution-guided regularization to prevent spurious negative influence and faithfully remove target knowledge. Experimental results confirm that our method reliably erases target knowledge and outperforms strong baselines across two practical retraining scenarios: (1) adversarial injection of private data, and (2) benign attack using an instruction-following benchmark. Our findings highlight the necessity of robust and faithful unlearning methods for safe deployment of language models.
FaithUn: Toward Faithful Forgetting in Language Models by Investigating the Interconnectedness of Knowledge
Feb 26, 2025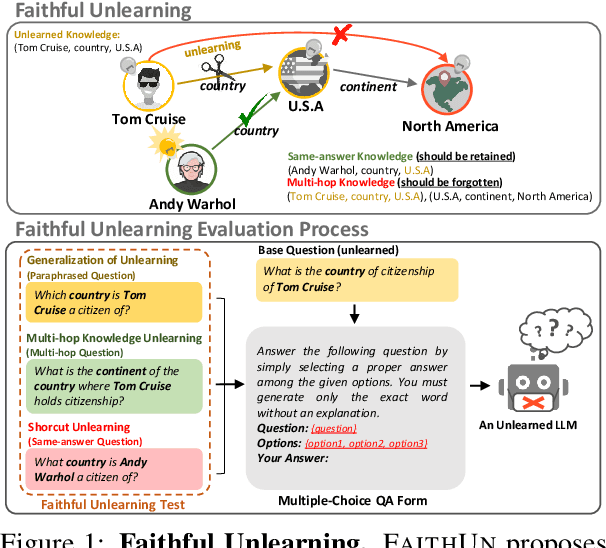
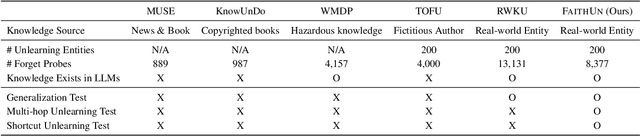

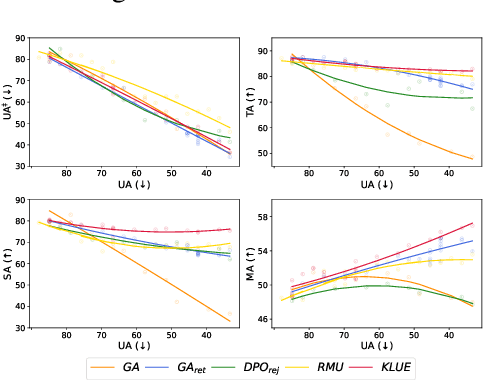
Various studies have attempted to remove sensitive or private knowledge from a language model to prevent its unauthorized exposure. However, prior studies have overlooked the complex and interconnected nature of knowledge, where related knowledge must be carefully examined. Specifically, they have failed to evaluate whether an unlearning method faithfully erases interconnected knowledge that should be removed, retaining knowledge that appears relevant but exists in a completely different context. To resolve this problem, we first define a new concept called superficial unlearning, which refers to the phenomenon where an unlearning method either fails to erase the interconnected knowledge it should remove or unintentionally erases irrelevant knowledge. Based on the definition, we introduce a new benchmark, FaithUn, to analyze and evaluate the faithfulness of unlearning in real-world knowledge QA settings. Furthermore, we propose a novel unlearning method, KLUE, which updates only knowledge-related neurons to achieve faithful unlearning. KLUE identifies knowledge neurons using an explainability method and updates only those neurons using selected unforgotten samples. Experimental results demonstrate that widely-used unlearning methods fail to ensure faithful unlearning, while our method shows significant effectiveness in real-world QA unlearning.
Persona is a Double-edged Sword: Enhancing the Zero-shot Reasoning by Ensembling the Role-playing and Neutral Prompts
Aug 16, 2024Recent studies demonstrate that prompting an appropriate role-playing persona to an LLM improves its reasoning capability. However, assigning a proper persona is difficult since an LLM's performance is extremely sensitive to assigned prompts; therefore, personas sometimes hinder LLMs and degrade their reasoning capabilities. In this paper, we propose a novel framework, Jekyll \& Hyde, which ensembles the results of role-playing and neutral prompts to eradicate performance degradation via unilateral use of role-playing prompted LLM and enhance the robustness of an LLM's reasoning ability. Specifically, Jekyll \& Hyde collects two potential solutions from both role-playing and neutral prompts and selects a better solution after cross-checking via an LLM evaluator. However, LLM-based evaluators tend to be affected by the order of those potential solutions within the prompt when selecting the proper solution; thus, we also propose a robust LLM evaluator to mitigate the position bias. The experimental analysis demonstrates that role-playing prompts distract LLMs and degrade their reasoning abilities in 4 out of 12 datasets, even when using GPT-4. In addition, we reveal that Jekyll \& Hyde improves reasoning capabilities by selecting better choices among the potential solutions on twelve widely-used reasoning datasets. We further show that our proposed LLM evaluator outperforms other baselines, proving the LLMs' position bias is successfully mitigated.
SKIP: Skill-Localized Prompt Tuning for Inference Speed Boost-Up
Apr 18, 2024Prompt-tuning methods have shown comparable performance as parameter-efficient fine-tuning (PEFT) methods in various natural language understanding tasks. However, existing prompt tuning methods still utilize the entire model architecture; thus, they fail to accelerate inference speed in the application. In this paper, we propose a novel approach called SKIll-localized Prompt tuning (SKIP), which is extremely efficient in inference time. Our method significantly enhances inference efficiency by investigating and utilizing a skill-localized subnetwork in a language model. Surprisingly, our method improves the inference speed up to 160% while pruning 52% of the parameters. Furthermore, we demonstrate that our method is applicable across various transformer-based architectures, thereby confirming its practicality and scalability.
LongStory: Coherent, Complete and Length Controlled Long story Generation
Nov 26, 2023



A human author can write any length of story without losing coherence. Also, they always bring the story to a proper ending, an ability that current language models lack. In this work, we present the LongStory for coherent, complete, and length-controlled long story generation. LongStory introduces two novel methodologies: (1) the long and short-term contexts weight calibrator (CWC) and (2) long story structural positions (LSP). The CWC adjusts weights for long-term context Memory and short-term context Cheating, acknowledging their distinct roles. The LSP employs discourse tokens to convey the structural positions of a long story. Trained on three datasets with varied average story lengths, LongStory outperforms other baselines, including the strong story generator Plotmachine, in coherence, completeness, relevance, and repetitiveness. We also perform zero-shot tests on each dataset to assess the model's ability to predict outcomes beyond its training data and validate our methodology by comparing its performance with variants of our model.
CRISPR: Eliminating Bias Neurons from an Instruction-following Language Model
Nov 16, 2023



Large language models (LLMs) executing tasks through instruction-based prompts often face challenges stemming from distribution differences between user instructions and training instructions. This leads to distractions and biases, especially when dealing with inconsistent dynamic labels. In this paper, we introduces a novel bias mitigation method, CRISPR, designed to alleviate instruction-label biases in LLMs. CRISPR utilizes attribution methods to identify bias neurons influencing biased outputs and employs pruning to eliminate the bias neurons. Experimental results demonstrate the method's effectiveness in mitigating biases in instruction-based prompting, enhancing language model performance on social bias benchmarks without compromising pre-existing knowledge. CRISPR proves highly practical, model-agnostic, offering flexibility in adapting to evolving social biases.