 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCasual as an Anchor: Resolving Supervision Misalignment in Formality Transfer Dataset
May 28, 2026Formality transfer is commonly framed as a symmetric bidirectional task between informal and formal registers. We argue that this framing conceals a supervision design flaw in existing benchmarks such as GYAFC: binary human rewrites encode relative stylistic shifts rather than absolute human notions of formality. Consequently, models learn to generate pseudo-formal outputs that satisfy benchmark labels while failing to produce genuinely formal language. We quantify this misalignment by re-evaluating benchmark formal labels under a human-aligned definition of formality, revealing substantial discrepancies that propagate to consistent informal-to-formal failures across model families. To address this issue, we reconceptualize formality transfer as a graded dimension rather than a binary attribute. We introduce a three-level spectrum: informal, casual, and formal, where casual serves as an explicit intermediate state that clarifies supervision signals. Based on this framework, we introduce 3LF, a dataset providing parallel supervision across all three levels. Training on 3LF substantially reduces informal-to-formal failures and improves alignment with human perception. For example, GPT-4.1-nano improves from 0.06 to 0.88 F1 in the informal-to- formal direction despite 3LF being significantly smaller than GYAFC. We further demonstrate that these gains cannot be reproduced through in-context learning alone and provide qualitative analyses of ambiguity-driven errors and meaning distortions. Overall, our findings demonstrate how supervision design shapes stylistic alignment and highlight the importance of alignment-aware benchmark construction in controllable text generation.
Confidence-Guided Stepwise Model Routing for Cost-Efficient Reasoning
Nov 09, 2025Recent advances in Large Language Models (LLMs) - particularly model scaling and test-time techniques - have greatly enhanced the reasoning capabilities of language models at the expense of higher inference costs. To lower inference costs, prior works train router models or deferral mechanisms that allocate easy queries to a small, efficient model, while forwarding harder queries to larger, more expensive models. However, these trained router models often lack robustness under domain shifts and require expensive data synthesis techniques such as Monte Carlo rollouts to obtain sufficient ground-truth routing labels for training. In this work, we propose Confidence-Guided Stepwise Model Routing for Cost-Efficient Reasoning (STEER), a domain-agnostic framework that performs fine-grained, step-level routing between smaller and larger LLMs without utilizing external models. STEER leverages confidence scores from the smaller model's logits prior to generating a reasoning step, so that the large model is invoked only when necessary. Extensive evaluations using different LLMs on a diverse set of challenging benchmarks across multiple domains such as Mathematical Reasoning, Multi-Hop QA, and Planning tasks indicate that STEER achieves competitive or enhanced accuracy while reducing inference costs (up to +20% accuracy with 48% less FLOPs compared to solely using the larger model on AIME), outperforming baselines that rely on trained external modules. Our results establish model-internal confidence as a robust, domain-agnostic signal for model routing, offering a scalable pathway for efficient LLM deployment.
Generating Diverse Hypotheses for Inductive Reasoning
Dec 18, 2024Inductive reasoning - the process of inferring general rules from a small number of observations - is a fundamental aspect of human intelligence. Recent works suggest that large language models (LLMs) can engage in inductive reasoning by sampling multiple hypotheses about the rules and selecting the one that best explains the observations. However, due to the IID sampling, semantically redundant hypotheses are frequently generated, leading to significant wastage of compute. In this paper, we 1) demonstrate that increasing the temperature to enhance the diversity is limited due to text degeneration issue, and 2) propose a novel method to improve the diversity while maintaining text quality. We first analyze the effect of increasing the temperature parameter, which is regarded as the LLM's diversity control, on IID hypotheses. Our analysis shows that as temperature rises, diversity and accuracy of hypotheses increase up to a certain point, but this trend saturates due to text degeneration. To generate hypotheses that are more semantically diverse and of higher quality, we propose a novel approach inspired by human inductive reasoning, which we call Mixture of Concepts (MoC). When applied to several inductive reasoning benchmarks, MoC demonstrated significant performance improvements compared to standard IID sampling and other approaches.
PLM-Based Discrete Diffusion Language Models with Entropy-Adaptive Gibbs Sampling
Nov 10, 2024


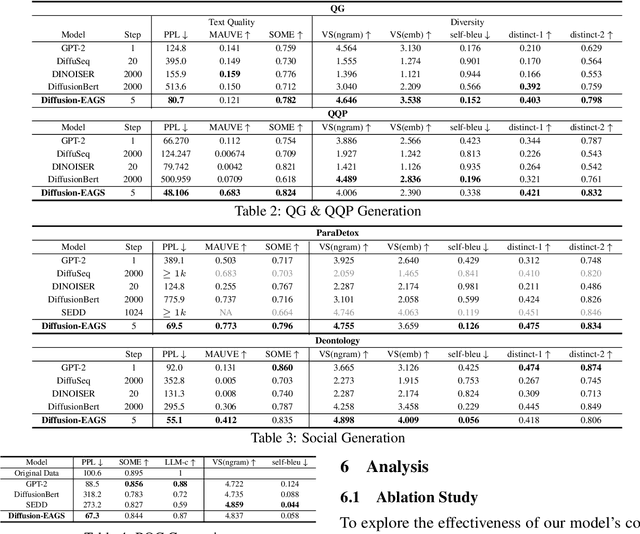
Recently, discrete diffusion language models have demonstrated promising results in NLP. However, there has been limited research on integrating Pretrained Language Models (PLMs) into discrete diffusion models, resulting in underwhelming performance in downstream NLP generation tasks. This integration is particularly challenging because of the discrepancy between step-wise denoising strategy of diffusion models and single-step mask prediction approach of MLM-based PLMs. In this paper, we introduce Diffusion-EAGS, a novel approach that effectively integrates PLMs with the diffusion models. Furthermore, as it is challenging for PLMs to determine where to apply denoising during the diffusion process, we integrate an entropy tracking module to assist them. Finally, we propose entropy-based noise scheduling in the forward process to improve the effectiveness of entropy-adaptive sampling throughout the generation phase. Experimental results show that Diffusion-EAGS outperforms existing diffusion baselines in downstream generation tasks, achieving high text quality and diversity with precise token-level control. We also show that our model is capable of adapting to bilingual and low-resource settings, which are common in real-world applications.
Fine-grained Gender Control in Machine Translation with Large Language Models
Jul 21, 2024
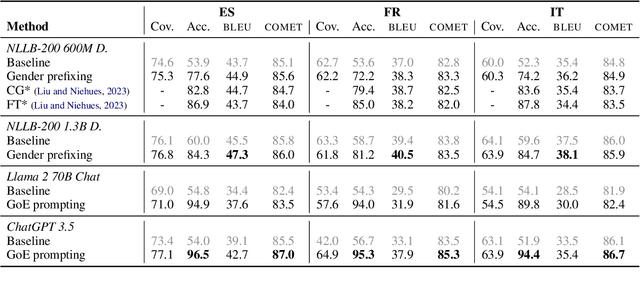
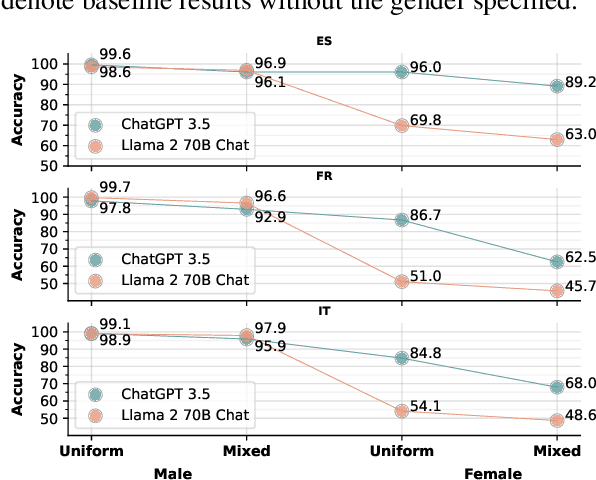
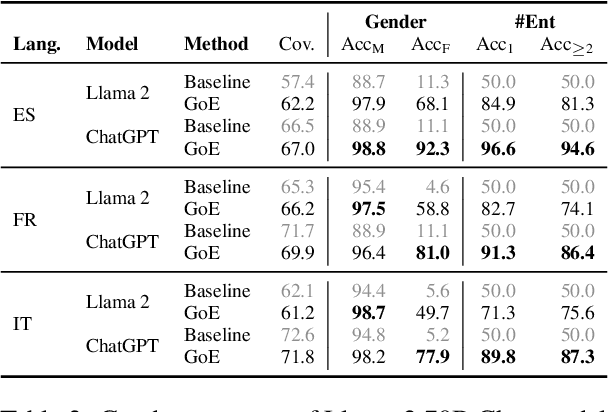
In machine translation, the problem of ambiguously gendered input has been pointed out, where the gender of an entity is not available in the source sentence. To address this ambiguity issue, the task of controlled translation that takes the gender of the ambiguous entity as additional input have been proposed. However, most existing works have only considered a simplified setup of one target gender for input. In this paper, we tackle controlled translation in a more realistic setting of inputs with multiple entities and propose Gender-of-Entity (GoE) prompting method for LLMs. Our proposed method instructs the model with fine-grained entity-level gender information to translate with correct gender inflections. By utilizing four evaluation benchmarks, we investigate the controlled translation capability of LLMs in multiple dimensions and find that LLMs reach state-of-the-art performance in controlled translation. Furthermore, we discover an emergence of gender interference phenomenon when controlling the gender of multiple entities. Finally, we address the limitations of existing gender accuracy evaluation metrics and propose leveraging LLMs as an evaluator for gender inflection in machine translation.
VLind-Bench: Measuring Language Priors in Large Vision-Language Models
Jun 17, 2024Large Vision-Language Models (LVLMs) have demonstrated outstanding performance across various multimodal tasks. However, they suffer from a problem known as language prior, where responses are generated based solely on textual patterns while disregarding image information. Addressing the issue of language prior is crucial, as it can lead to undesirable biases or hallucinations when dealing with images that are out of training distribution. Despite its importance, current methods for accurately measuring language priors in LVLMs are poorly studied. Although existing benchmarks based on counterfactual or out-of-distribution images can partially be used to measure language priors, they fail to disentangle language priors from other confounding factors. To this end, we propose a new benchmark called VLind-Bench, which is the first benchmark specifically designed to measure the language priors, or blindness, of LVLMs. It not only includes tests on counterfactual images to assess language priors but also involves a series of tests to evaluate more basic capabilities such as commonsense knowledge, visual perception, and commonsense biases. For each instance in our benchmark, we ensure that all these basic tests are passed before evaluating the language priors, thereby minimizing the influence of other factors on the assessment. The evaluation and analysis of recent LVLMs in our benchmark reveal that almost all models exhibit a significant reliance on language priors, presenting a strong challenge in the field.
Can LLMs Recognize Toxicity? Structured Toxicity Investigation Framework and Semantic-Based Metric
Feb 16, 2024In the pursuit of developing Large Language Models (LLMs) that adhere to societal standards, it is imperative to discern the existence of toxicity in the generated text. The majority of existing toxicity metrics rely on encoder models trained on specific toxicity datasets. However, these encoders are susceptible to out-of-distribution (OOD) problems and depend on the definition of toxicity assumed in a dataset. In this paper, we introduce an automatic robust metric grounded on LLMs to distinguish whether model responses are toxic. We start by analyzing the toxicity factors, followed by examining the intrinsic toxic attributes of LLMs to ascertain their suitability as evaluators. Subsequently, we evaluate our metric, LLMs As ToxiciTy Evaluators (LATTE), on evaluation datasets.The empirical results indicate outstanding performance in measuring toxicity, improving upon state-of-the-art metrics by 12 points in F1 score without training procedure. We also show that upstream toxicity has an influence on downstream metrics.
DPP-TTS: Diversifying prosodic features of speech via determinantal point processes
Oct 23, 2023With the rapid advancement in deep generative models, recent neural Text-To-Speech(TTS) models have succeeded in synthesizing human-like speech. There have been some efforts to generate speech with various prosody beyond monotonous prosody patterns. However, previous works have several limitations. First, typical TTS models depend on the scaled sampling temperature for boosting the diversity of prosody. Speech samples generated at high sampling temperatures often lack perceptual prosodic diversity, which can adversely affect the naturalness of the speech. Second, the diversity among samples is neglected since the sampling procedure often focuses on a single speech sample rather than multiple ones. In this paper, we propose DPP-TTS: a text-to-speech model based on Determinantal Point Processes (DPPs) with a prosody diversifying module. Our TTS model is capable of generating speech samples that simultaneously consider perceptual diversity in each sample and among multiple samples. We demonstrate that DPP-TTS generates speech samples with more diversified prosody than baselines in the side-by-side comparison test considering the naturalness of speech at the same time.
Target-Agnostic Gender-Aware Contrastive Learning for Mitigating Bias in Multilingual Machine Translation
May 23, 2023



Gender bias is a significant issue in machine translation, leading to ongoing research efforts in developing bias mitigation techniques. However, most works focus on debiasing of bilingual models without consideration for multilingual systems. In this paper, we specifically target the unambiguous gender bias issue of multilingual machine translation models and propose a new mitigation method based on a novel perspective on the problem. We hypothesize that the gender bias in unambiguous settings is due to the lack of gender information encoded into the non-explicit gender words and devise a scheme to encode correct gender information into their latent embeddings. Specifically, we employ Gender-Aware Contrastive Learning, GACL, based on gender pseudo-labels to encode gender information on the encoder embeddings. Our method is target-language-agnostic and applicable to already trained multilingual machine translation models through post-fine-tuning. Through multilingual evaluation, we show that our approach improves gender accuracy by a wide margin without hampering translation performance. We also observe that incorporated gender information transfers and benefits other target languages regarding gender accuracy. Finally, we demonstrate that our method is applicable and beneficial to models of various sizes.
Multi-View Zero-Shot Open Intent Induction from Dialogues: Multi Domain Batch and Proxy Gradient Transfer
Mar 23, 2023In Task Oriented Dialogue (TOD) system, detecting and inducing new intents are two main challenges to apply the system in the real world. In this paper, we suggest the semantic multi-view model to resolve these two challenges: (1) SBERT for General Embedding (GE), (2) Multi Domain Batch (MDB) for dialogue domain knowledge, and (3) Proxy Gradient Transfer (PGT) for cluster-specialized semantic. MDB feeds diverse dialogue datasets to the model at once to tackle the multi-domain problem by learning the multiple domain knowledge. We introduce a novel method PGT, which employs the Siamese network to fine-tune the model with a clustering method directly.Our model can learn how to cluster dialogue utterances by using PGT. Experimental results demonstrate that our multi-view model with MDB and PGT significantly improves the Open Intent Induction performance compared to baseline systems.