 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-Box Hallucination Detection via Consistency Under the Uncertain Expression
Sep 26, 2025Despite the great advancement of Language modeling in recent days, Large Language Models (LLMs) such as GPT3 are notorious for generating non-factual responses, so-called "hallucination" problems. Existing methods for detecting and alleviating this hallucination problem require external resources or the internal state of LLMs, such as the output probability of each token. Given the LLM's restricted external API availability and the limited scope of external resources, there is an urgent demand to establish the Black-Box approach as the cornerstone for effective hallucination detection. In this work, we propose a simple black-box hallucination detection metric after the investigation of the behavior of LLMs under expression of uncertainty. Our comprehensive analysis reveals that LLMs generate consistent responses when they present factual responses while non-consistent responses vice versa. Based on the analysis, we propose an efficient black-box hallucination detection metric with the expression of uncertainty. The experiment demonstrates that our metric is more predictive of the factuality in model responses than baselines that use internal knowledge of LLMs.
MultiActor-Audiobook: Zero-Shot Audiobook Generation with Faces and Voices of Multiple Speakers
May 19, 2025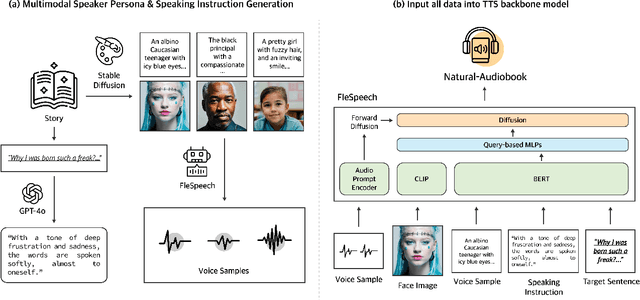


We introduce MultiActor-Audiobook, a zero-shot approach for generating audiobooks that automatically produces consistent, expressive, and speaker-appropriate prosody, including intonation and emotion. Previous audiobook systems have several limitations: they require users to manually configure the speaker's prosody, read each sentence with a monotonic tone compared to voice actors, or rely on costly training. However, our MultiActor-Audiobook addresses these issues by introducing two novel processes: (1) MSP (**Multimodal Speaker Persona Generation**) and (2) LSI (**LLM-based Script Instruction Generation**). With these two processes, MultiActor-Audiobook can generate more emotionally expressive audiobooks with a consistent speaker prosody without additional training. We compare our system with commercial products, through human and MLLM evaluations, achieving competitive results. Furthermore, we demonstrate the effectiveness of MSP and LSI through ablation studies.
Drift: Decoding-time Personalized Alignments with Implicit User Preferences
Feb 21, 2025Personalized alignments for individual users have been a long-standing goal in large language models (LLMs). We introduce Drift, a novel framework that personalizes LLMs at decoding time with implicit user preferences. Traditional Reinforcement Learning from Human Feedback (RLHF) requires thousands of annotated examples and expensive gradient updates. In contrast, Drift personalizes LLMs in a training-free manner, using only a few dozen examples to steer a frozen model through efficient preference modeling. Our approach models user preferences as a composition of predefined, interpretable attributes and aligns them at decoding time to enable personalized generation. Experiments on both a synthetic persona dataset (Perspective) and a real human-annotated dataset (PRISM) demonstrate that Drift significantly outperforms RLHF baselines while using only 50-100 examples. Our results and analysis show that Drift is both computationally efficient and interpretable.
DPP-TTS: Diversifying prosodic features of speech via determinantal point processes
Oct 23, 2023With the rapid advancement in deep generative models, recent neural Text-To-Speech(TTS) models have succeeded in synthesizing human-like speech. There have been some efforts to generate speech with various prosody beyond monotonous prosody patterns. However, previous works have several limitations. First, typical TTS models depend on the scaled sampling temperature for boosting the diversity of prosody. Speech samples generated at high sampling temperatures often lack perceptual prosodic diversity, which can adversely affect the naturalness of the speech. Second, the diversity among samples is neglected since the sampling procedure often focuses on a single speech sample rather than multiple ones. In this paper, we propose DPP-TTS: a text-to-speech model based on Determinantal Point Processes (DPPs) with a prosody diversifying module. Our TTS model is capable of generating speech samples that simultaneously consider perceptual diversity in each sample and among multiple samples. We demonstrate that DPP-TTS generates speech samples with more diversified prosody than baselines in the side-by-side comparison test considering the naturalness of speech at the same time.