 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflectCAP: Detailed Image Captioning with Reflective Memory
Apr 14, 2026Detailed image captioning demands both factual grounding and fine-grained coverage, yet existing methods have struggled to achieve them simultaneously. We address this tension with Reflective Note-Guided Captioning (ReflectCAP), where a multi-agent pipeline analyzes what the target large vision-language model (LVLM) consistently hallucinates and what it systematically overlooks, distilling these patterns into reusable guidelines called Structured Reflection Notes. At inference time, these notes steer the captioning model along both axes -- what to avoid and what to attend to -- yielding detailed captions that jointly improve factuality and coverage. Applying this method to 8 LVLMs spanning the GPT-4.1 family, Qwen series, and InternVL variants, ReflectCAP reaches the Pareto frontier of the trade-off between factuality and coverage, and delivers substantial gains on CapArena-Auto, where generated captions are judged head-to-head against strong reference models. Moreover, ReflectCAP offers a more favorable trade-off between caption quality and compute cost than model scaling or existing multi-agent pipelines, which incur 21--36\% greater overhead. This makes high-quality detailed captioning viable under real-world cost and latency constraints.
Reliability-Aware Adaptive Self-Consistency for Efficient Sampling in LLM Reasoning
Jan 06, 2026Self-Consistency improves reasoning reliability through multi-sample aggregation, but incurs substantial inference cost. Adaptive self-consistency methods mitigate this issue by adjusting the sampling budget; however, they rely on count-based stopping rules that treat all responses equally, often leading to unnecessary sampling. We propose Reliability-Aware Adaptive Self-Consistency (ReASC), which addresses this limitation by reframing adaptive sampling from response counting to evidence sufficiency, leveraging response-level confidence for principled information aggregation. ReASC operates in two stages: a single-sample decision stage that resolves instances confidently answerable from a single response, and a reliability-aware accumulation stage that aggregates responses by jointly leveraging their frequency and confidence. Across five models and four datasets, ReASC consistently achieves the best accuracy-cost trade-off compared to existing baselines, yielding improved inference efficiency across model scales from 3B to 27B parameters. As a concrete example, ReASC reduces inference cost by up to 70\% relative to self-consistency while preserving accuracy on GSM8K using Gemma-3-4B-it.
Black-Box Hallucination Detection via Consistency Under the Uncertain Expression
Sep 26, 2025Despite the great advancement of Language modeling in recent days, Large Language Models (LLMs) such as GPT3 are notorious for generating non-factual responses, so-called "hallucination" problems. Existing methods for detecting and alleviating this hallucination problem require external resources or the internal state of LLMs, such as the output probability of each token. Given the LLM's restricted external API availability and the limited scope of external resources, there is an urgent demand to establish the Black-Box approach as the cornerstone for effective hallucination detection. In this work, we propose a simple black-box hallucination detection metric after the investigation of the behavior of LLMs under expression of uncertainty. Our comprehensive analysis reveals that LLMs generate consistent responses when they present factual responses while non-consistent responses vice versa. Based on the analysis, we propose an efficient black-box hallucination detection metric with the expression of uncertainty. The experiment demonstrates that our metric is more predictive of the factuality in model responses than baselines that use internal knowledge of LLMs.
Fooling the LVLM Judges: Visual Biases in LVLM-Based Evaluation
May 21, 2025



Recently, large vision-language models (LVLMs) have emerged as the preferred tools for judging text-image alignment, yet their robustness along the visual modality remains underexplored. This work is the first study to address a key research question: Can adversarial visual manipulations systematically fool LVLM judges into assigning unfairly inflated scores? We define potential image induced biases within the context of T2I evaluation and examine how these biases affect the evaluations of LVLM judges. Moreover, we introduce a novel, fine-grained, multi-domain meta-evaluation benchmark named FRAME, which is deliberately constructed to exhibit diverse score distributions. By introducing the defined biases into the benchmark, we reveal that all tested LVLM judges exhibit vulnerability across all domains, consistently inflating scores for manipulated images. Further analysis reveals that combining multiple biases amplifies their effects, and pairwise evaluations are similarly susceptible. Moreover, we observe that visual biases persist under prompt-based mitigation strategies, highlighting the vulnerability of current LVLM evaluation systems and underscoring the urgent need for more robust LVLM judges.
Return of EM: Entity-driven Answer Set Expansion for QA Evaluation
Apr 24, 2024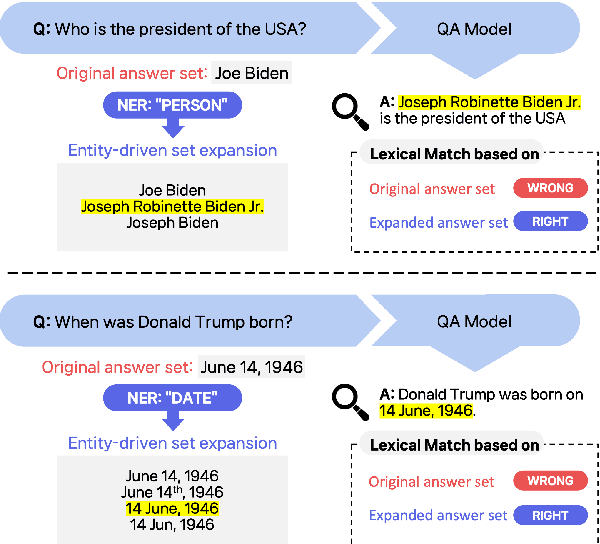
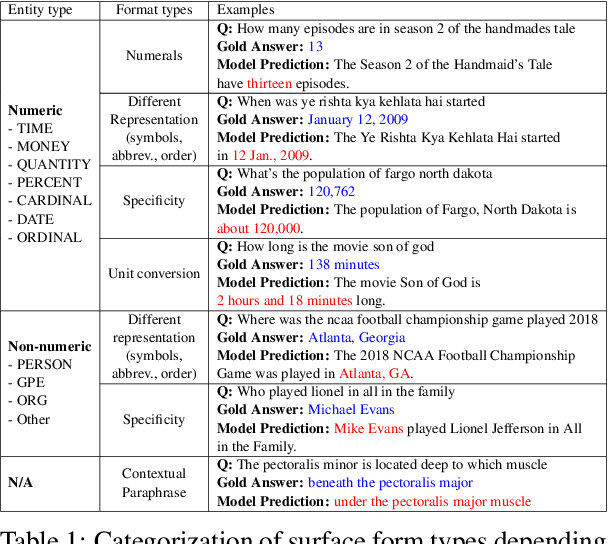
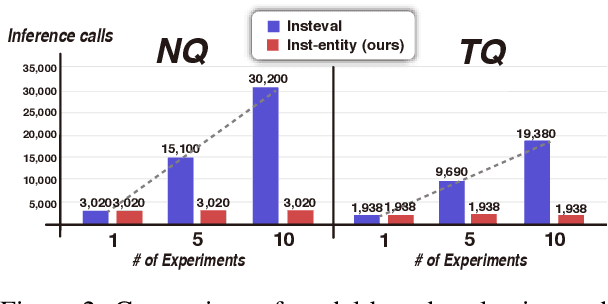
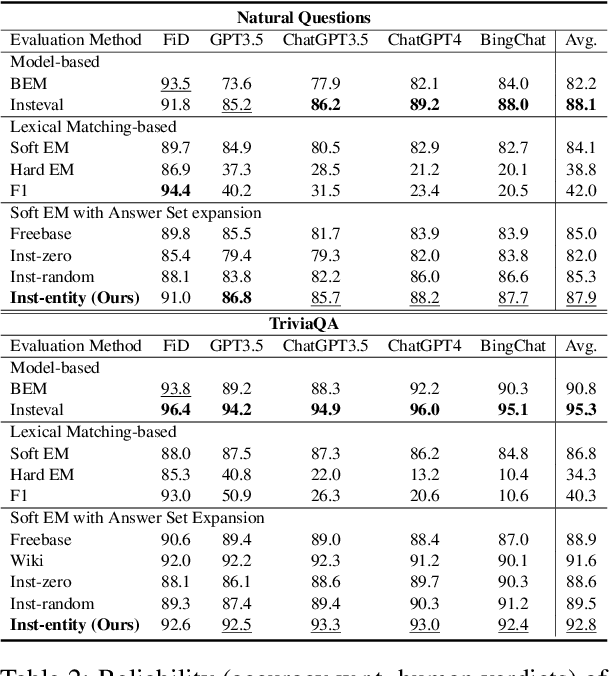
Recently, directly using large language models (LLMs) has been shown to be the most reliable method to evaluate QA models. However, it suffers from limited interpretability, high cost, and environmental harm. To address these, we propose to use soft EM with entity-driven answer set expansion. Our approach expands the gold answer set to include diverse surface forms, based on the observation that the surface forms often follow particular patterns depending on the entity type. The experimental results show that our method outperforms traditional evaluation methods by a large margin. Moreover, the reliability of our evaluation method is comparable to that of LLM-based ones, while offering the benefits of high interpretability and reduced environmental harm.