 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow You Ask Matters! Adaptive RAG Robustness to Query Variations
Apr 12, 2026Adaptive Retrieval-Augmented Generation (RAG) promises accuracy and efficiency by dynamically triggering retrieval only when needed and is widely used in practice. However, real-world queries vary in surface form even with the same intent, and their impact on Adaptive RAG remains under-explored. We introduce the first large-scale benchmark of diverse yet semantically identical query variations, combining human-written and model-generated rewrites. Our benchmark facilitates a systematic evaluation of Adaptive RAG robustness by examining its key components across three dimensions: answer quality, computational cost, and retrieval decisions. We discover a critical robustness gap, where small surface-level changes in queries dramatically alter retrieval behavior and accuracy. Although larger models show better performance, robustness does not improve accordingly. These findings reveal that Adaptive RAG methods are highly vulnerable to query variations that preserve identical semantics, exposing a critical robustness challenge.
SKIP: Skill-Localized Prompt Tuning for Inference Speed Boost-Up
Apr 18, 2024Prompt-tuning methods have shown comparable performance as parameter-efficient fine-tuning (PEFT) methods in various natural language understanding tasks. However, existing prompt tuning methods still utilize the entire model architecture; thus, they fail to accelerate inference speed in the application. In this paper, we propose a novel approach called SKIll-localized Prompt tuning (SKIP), which is extremely efficient in inference time. Our method significantly enhances inference efficiency by investigating and utilizing a skill-localized subnetwork in a language model. Surprisingly, our method improves the inference speed up to 160% while pruning 52% of the parameters. Furthermore, we demonstrate that our method is applicable across various transformer-based architectures, thereby confirming its practicality and scalability.
MP2D: An Automated Topic Shift Dialogue Generation Framework Leveraging Knowledge Graphs
Mar 09, 2024



Despite advancements in on-topic dialogue systems, effectively managing topic shifts within dialogues remains a persistent challenge, largely attributed to the limited availability of training datasets. To address this issue, we propose Multi-Passage to Dialogue (MP2D), a data generation framework that automatically creates conversational question-answering datasets with natural topic transitions. By leveraging the relationships between entities in a knowledge graph, MP2D maps the flow of topics within a dialogue, effectively mirroring the dynamics of human conversation. It retrieves relevant passages corresponding to the topics and transforms them into dialogues through the passage-to-dialogue method. Through quantitative and qualitative experiments, we demonstrate MP2D's efficacy in generating dialogue with natural topic shifts. Furthermore, this study introduces a novel benchmark for topic shift dialogues, TS-WikiDialog. Utilizing the dataset, we demonstrate that even Large Language Models (LLMs) struggle to handle topic shifts in dialogue effectively, and we showcase the performance improvements of models trained on datasets generated by MP2D across diverse topic shift dialogue tasks.
IterCQR: Iterative Conversational Query Reformulation without Human Supervision
Nov 16, 2023



In conversational search, which aims to retrieve passages containing essential information, queries suffer from high dependency on the preceding dialogue context. Therefore, reformulating conversational queries into standalone forms is essential for the effective utilization of off-the-shelf retrievers. Previous methodologies for conversational query search frequently depend on human-annotated gold labels. However, these manually crafted queries often result in sub-optimal retrieval performance and require high collection costs. In response to these challenges, we propose Iterative Conversational Query Reformulation (IterCQR), a methodology that conducts query reformulation without relying on human oracles. IterCQR iteratively trains the QR model by directly leveraging signal from information retrieval (IR) as a reward. Our proposed IterCQR method shows state-of-the-art performance on two datasets, demonstrating its effectiveness on both sparse and dense retrievers. Notably, IterCQR exhibits robustness in domain-shift, low-resource, and topic-shift scenarios.
Attribution-based Task-specific Pruning for Multi-task Language Models
May 09, 2022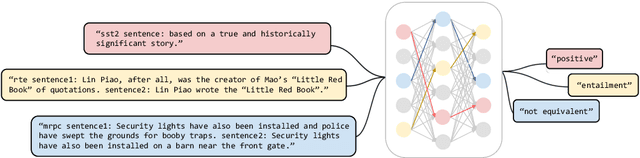
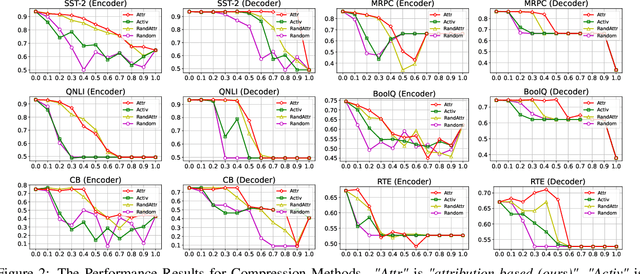
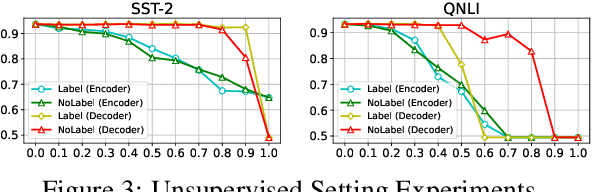
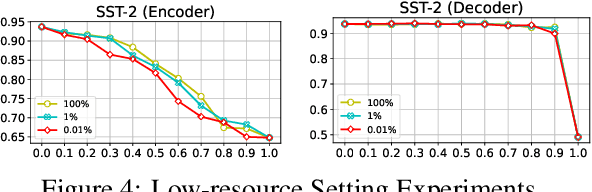
Multi-task language models show outstanding performance for various natural language understanding tasks with only a single model. However, these language models inevitably utilize unnecessary large-scale model parameters, even when they are used for only a specific task. In this paper, we propose a novel training-free task-specific pruning method for multi-task language models. Specifically, we utilize an attribution method to compute the importance of each neuron for performing a specific task. Then, we prune task-specifically unimportant neurons using this computed importance. Experimental results on the six widely-used datasets show that our proposed pruning method significantly outperforms baseline compression methods. Also, we extend our method to be applicable in a low-resource setting, where the number of labeled datasets is insufficient.