 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEER: A Comprehensive and Reliable Benchmark for Deep-Research Expert Reports
Dec 19, 2025As large language models (LLMs) advance, deep research systems can generate expert-level reports via multi-step reasoning and evidence-based synthesis, but evaluating such reports remains challenging. Existing benchmarks often lack systematic criteria for expert reporting, evaluations that rely heavily on LLM judges can fail to capture issues that require expert judgment, and source verification typically covers only a limited subset of explicitly cited statements rather than report-wide factual reliability. We introduce DEER, a benchmark for evaluating expert-level deep research reports. DEER comprises 50 report-writing tasks spanning 13 domains and an expert-grounded evaluation taxonomy (7 dimensions, 25 sub-dimension) operationalized into 130 fine-grained rubric items. DEER further provides task-specific expert guidance to help LLM judges assess expert-level report quality more consistently. Complementing rubric-based assessment, we propose a document-level fact-checking architecture that extracts and verifies all claims across the entire report, including both cited and uncited ones, and quantifies external-evidence quality. DEER correlates closely with human expert judgments and yields interpretable diagnostics of system strengths and weaknesses.
Deep Exploration of Cross-Lingual Zero-Shot Generalization in Instruction Tuning
Jun 13, 2024Instruction tuning has emerged as a powerful technique, significantly boosting zero-shot performance on unseen tasks. While recent work has explored cross-lingual generalization by applying instruction tuning to multilingual models, previous studies have primarily focused on English, with a limited exploration of non-English tasks. For an in-depth exploration of cross-lingual generalization in instruction tuning, we perform instruction tuning individually for two distinct language meta-datasets. Subsequently, we assess the performance on unseen tasks in a language different from the one used for training. To facilitate this investigation, we introduce a novel non-English meta-dataset named "KORANI" (Korean Natural Instruction), comprising 51 Korean benchmarks. Moreover, we design cross-lingual templates to mitigate discrepancies in language and instruction-format of the template between training and inference within the cross-lingual setting. Our experiments reveal consistent improvements through cross-lingual generalization in both English and Korean, outperforming baseline by average scores of 20.7\% and 13.6\%, respectively. Remarkably, these enhancements are comparable to those achieved by monolingual instruction tuning and even surpass them in some tasks. The result underscores the significance of relevant data acquisition across languages over linguistic congruence with unseen tasks during instruction tuning.
Instruction Matters, a Simple yet Effective Task Selection Approach in Instruction Tuning for Specific Tasks
Apr 25, 2024

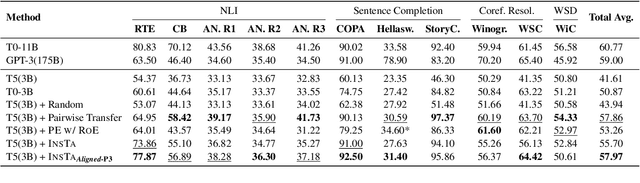

Instruction tuning has shown its ability to not only enhance zero-shot generalization across various tasks but also its effectiveness in improving the performance of specific tasks. A crucial aspect in instruction tuning for a particular task is a strategic selection of related tasks that offer meaningful supervision, thereby enhancing efficiency and preventing performance degradation from irrelevant tasks. Our research reveals that leveraging instruction information \textit{alone} enables the identification of pertinent tasks for instruction tuning. This approach is notably simpler compared to traditional methods that necessitate complex measurements of pairwise transferability between tasks or the creation of data samples for the target task. Furthermore, by additionally learning the unique instructional template style of the meta-dataset, we observe an improvement in task selection accuracy, which contributes to enhanced overall performance. Experimental results demonstrate that training on a small set of tasks, chosen solely based on the instructions, leads to substantial performance improvements on benchmarks like P3, Big-Bench, NIV2, and Big-Bench Hard. Significantly, these improvements exceed those achieved by prior task selection methods, highlighting the efficacy of our approach.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
TemporalWiki: A Lifelong Benchmark for Training and Evaluating Ever-Evolving Language Models
Apr 29, 2022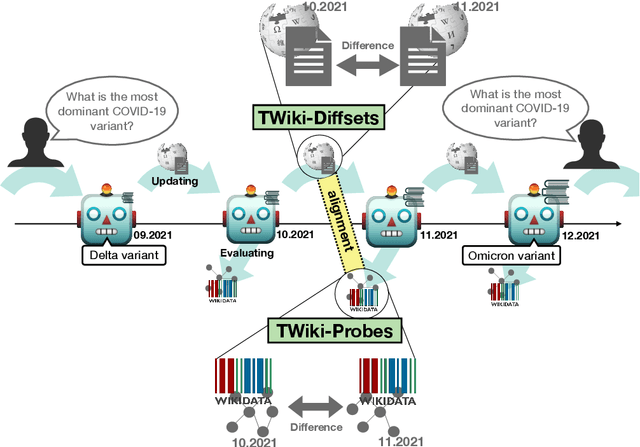
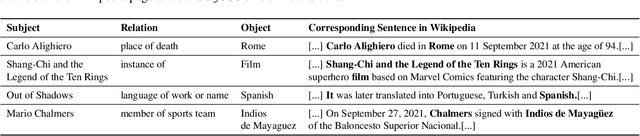

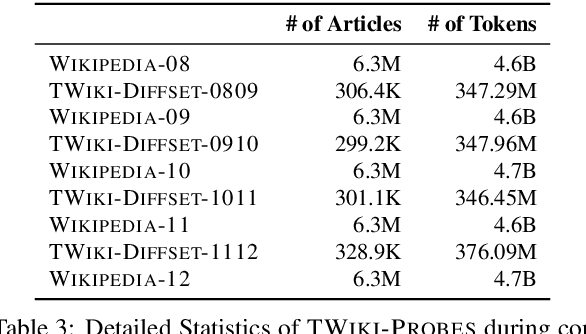
Language Models (LMs) become outdated as the world changes; they often fail to perform tasks requiring recent factual information which was absent or different during training, a phenomenon called temporal misalignment. This is especially a challenging problem because the research community still lacks a coherent dataset for assessing the adaptability of LMs to frequently-updated knowledge corpus such as Wikipedia. To this end, we introduce TemporalWiki, a lifelong benchmark for ever-evolving LMs that utilizes the difference between consecutive snapshots of English Wikipedia and English Wikidata for training and evaluation, respectively. The benchmark hence allows researchers to periodically track an LM's ability to retain previous knowledge and acquire updated/new knowledge at each point in time. We also find that training an LM on the diff data through continual learning methods achieves similar or better perplexity than on the entire snapshot in our benchmark with 12 times less computational cost, which verifies that factual knowledge in LMs can be safely updated with minimal training data via continual learning. The dataset and the code are available at https://github.com/joeljang/temporalwiki .