 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Cognitive Inertia in Large Reasoning Models via Latent Spike Steering
Jan 30, 2026While Large Reasoning Models (LRMs) have achieved remarkable performance by scaling test-time compute, they frequently suffer from Cognitive Inertia, a failure pattern manifesting as either overthinking (inertia of motion) or reasoning rigidity (inertia of direction). Existing detection methods, typically relying on superficial textual heuristics like self-correction tokens, often fail to capture the model's unvoiced internal conflicts. To address this, we propose STARS (Spike-Triggered Adaptive Reasoning Steering), a training-free framework designed to rectify cognitive inertia by monitoring latent dynamics. STARS identifies Cognitive Pivots-critical moments of reasoning transition-by detecting distinct L2 distance spikes in the hidden states. Upon detection, the framework employs geometric trajectory analysis to diagnose the structural nature of the transition and injects state-aware language cues to steer the model in real-time. Our experiments across diverse benchmarks confirm that STARS efficiently curtails redundant loops while improving accuracy through the adaptive correction of erroneous trajectories. STARS offers a robust, unsupervised mechanism to optimize the reasoning process of LRMs without requiring additional fine-tuning.
Dynamic Label Name Refinement for Few-Shot Dialogue Intent Classification
Dec 20, 2024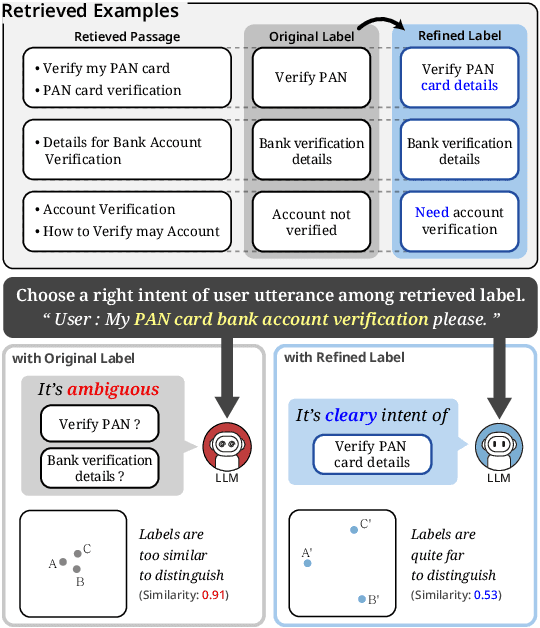
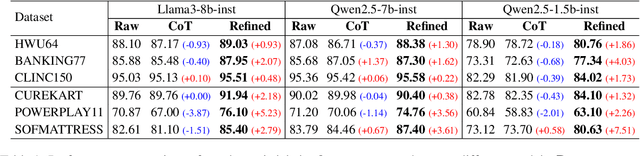
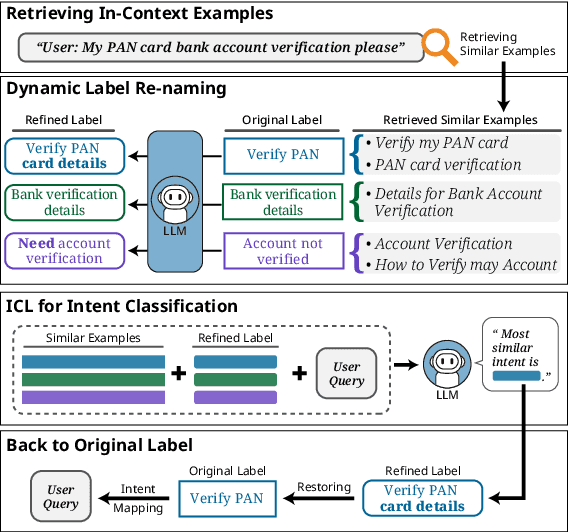

Dialogue intent classification aims to identify the underlying purpose or intent of a user's input in a conversation. Current intent classification systems encounter considerable challenges, primarily due to the vast number of possible intents and the significant semantic overlap among similar intent classes. In this paper, we propose a novel approach to few-shot dialogue intent classification through in-context learning, incorporating dynamic label refinement to address these challenges. Our method retrieves relevant examples for a test input from the training set and leverages a large language model to dynamically refine intent labels based on semantic understanding, ensuring that intents are clearly distinguishable from one another. Experimental results demonstrate that our approach effectively resolves confusion between semantically similar intents, resulting in significantly enhanced performance across multiple datasets compared to baselines. We also show that our method generates more interpretable intent labels, and has a better semantic coherence in capturing underlying user intents compared to baselines.