 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Label Name Refinement for Few-Shot Dialogue Intent Classification
Dec 20, 2024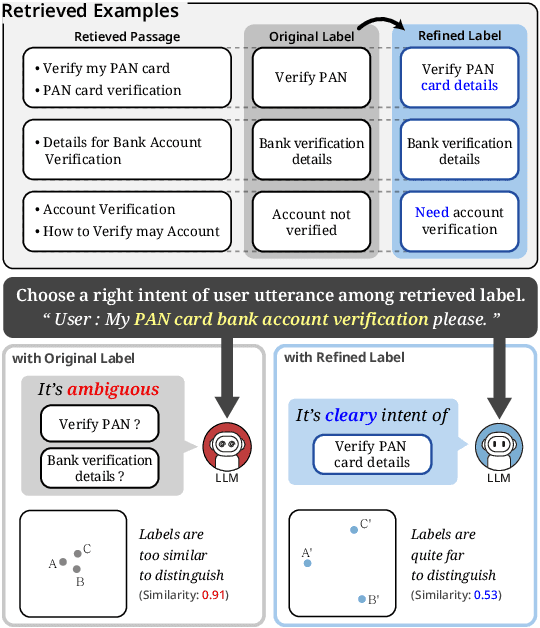
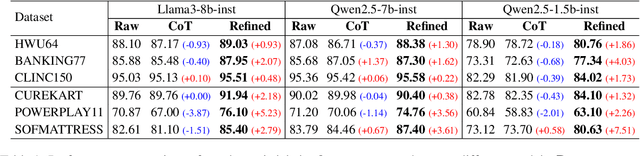
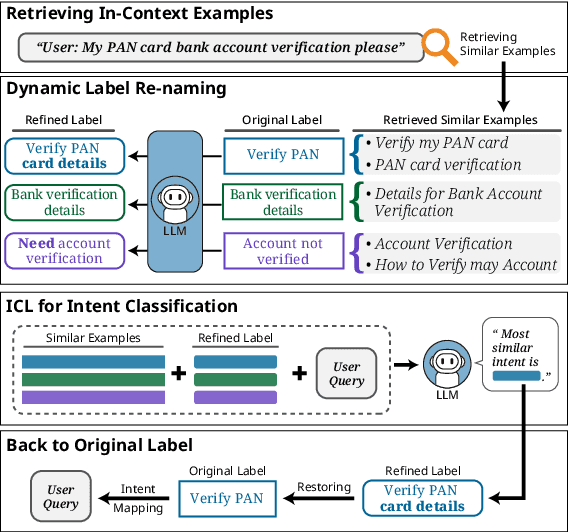

Dialogue intent classification aims to identify the underlying purpose or intent of a user's input in a conversation. Current intent classification systems encounter considerable challenges, primarily due to the vast number of possible intents and the significant semantic overlap among similar intent classes. In this paper, we propose a novel approach to few-shot dialogue intent classification through in-context learning, incorporating dynamic label refinement to address these challenges. Our method retrieves relevant examples for a test input from the training set and leverages a large language model to dynamically refine intent labels based on semantic understanding, ensuring that intents are clearly distinguishable from one another. Experimental results demonstrate that our approach effectively resolves confusion between semantically similar intents, resulting in significantly enhanced performance across multiple datasets compared to baselines. We also show that our method generates more interpretable intent labels, and has a better semantic coherence in capturing underlying user intents compared to baselines.
Low-Resource Cross-Lingual Summarization through Few-Shot Learning with Large Language Models
Jun 07, 2024Cross-lingual summarization (XLS) aims to generate a summary in a target language different from the source language document. While large language models (LLMs) have shown promising zero-shot XLS performance, their few-shot capabilities on this task remain unexplored, especially for low-resource languages with limited parallel data. In this paper, we investigate the few-shot XLS performance of various models, including Mistral-7B-Instruct-v0.2, GPT-3.5, and GPT-4. Our experiments demonstrate that few-shot learning significantly improves the XLS performance of LLMs, particularly GPT-3.5 and GPT-4, in low-resource settings. However, the open-source model Mistral-7B-Instruct-v0.2 struggles to adapt effectively to the XLS task with limited examples. Our findings highlight the potential of few-shot learning for improving XLS performance and the need for further research in designing LLM architectures and pre-training objectives tailored for this task. We provide a future work direction to explore more effective few-shot learning strategies and to investigate the transfer learning capabilities of LLMs for cross-lingual summarization.
Motion Feature Network: Fixed Motion Filter for Action Recognition
Aug 01, 2018
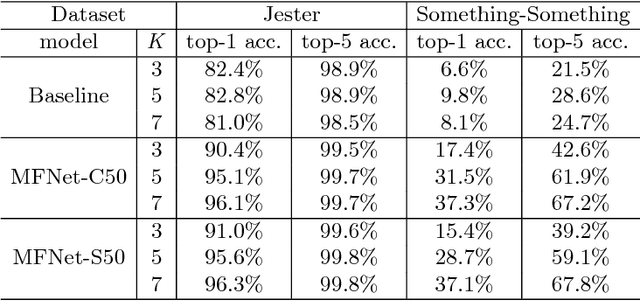
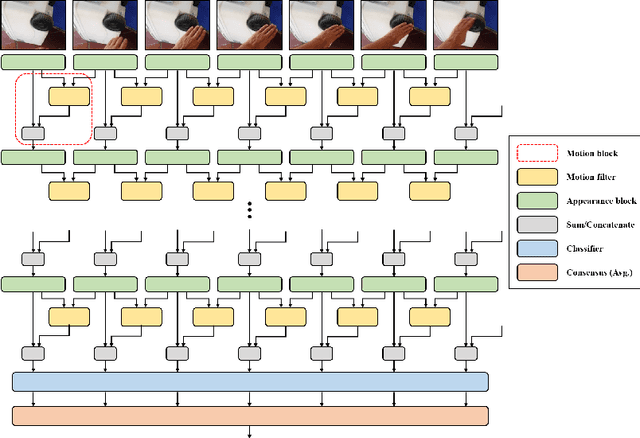
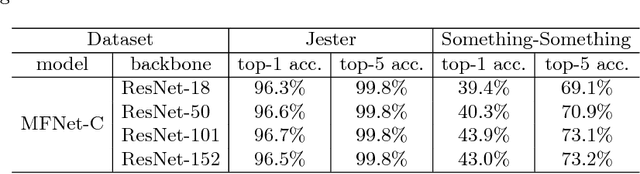
Spatio-temporal representations in frame sequences play an important role in the task of action recognition. Previously, a method of using optical flow as a temporal information in combination with a set of RGB images that contain spatial information has shown great performance enhancement in the action recognition tasks. However, it has an expensive computational cost and requires two-stream (RGB and optical flow) framework. In this paper, we propose MFNet (Motion Feature Network) containing motion blocks which make it possible to encode spatio-temporal information between adjacent frames in a unified network that can be trained end-to-end. The motion block can be attached to any existing CNN-based action recognition frameworks with only a small additional cost. We evaluated our network on two of the action recognition datasets (Jester and Something-Something) and achieved competitive performances for both datasets by training the networks from scratch.