 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Feature Network: Fixed Motion Filter for Action Recognition
Aug 01, 2018
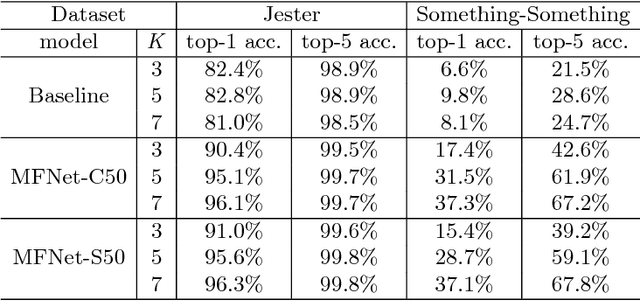
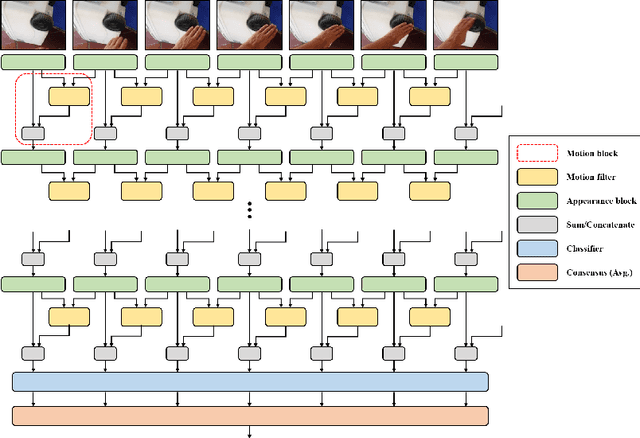
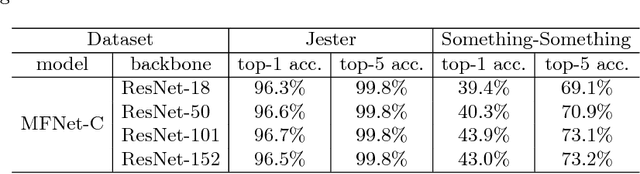
Spatio-temporal representations in frame sequences play an important role in the task of action recognition. Previously, a method of using optical flow as a temporal information in combination with a set of RGB images that contain spatial information has shown great performance enhancement in the action recognition tasks. However, it has an expensive computational cost and requires two-stream (RGB and optical flow) framework. In this paper, we propose MFNet (Motion Feature Network) containing motion blocks which make it possible to encode spatio-temporal information between adjacent frames in a unified network that can be trained end-to-end. The motion block can be attached to any existing CNN-based action recognition frameworks with only a small additional cost. We evaluated our network on two of the action recognition datasets (Jester and Something-Something) and achieved competitive performances for both datasets by training the networks from scratch.