 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChupa: Carving 3D Clothed Humans from Skinned Shape Priors using 2D Diffusion Probabilistic Models
May 19, 2023



We propose a 3D generation pipeline that uses diffusion models to generate realistic human digital avatars. Due to the wide variety of human identities, poses, and stochastic details, the generation of 3D human meshes has been a challenging problem. To address this, we decompose the problem into 2D normal map generation and normal map-based 3D reconstruction. Specifically, we first simultaneously generate realistic normal maps for the front and backside of a clothed human, dubbed dual normal maps, using a pose-conditional diffusion model. For 3D reconstruction, we ``carve'' the prior SMPL-X mesh to a detailed 3D mesh according to the normal maps through mesh optimization. To further enhance the high-frequency details, we present a diffusion resampling scheme on both body and facial regions, thus encouraging the generation of realistic digital avatars. We also seamlessly incorporate a recent text-to-image diffusion model to support text-based human identity control. Our method, namely, Chupa, is capable of generating realistic 3D clothed humans with better perceptual quality and identity variety.
Few-Shot Object Detection by Attending to Per-Sample-Prototype
Sep 16, 2021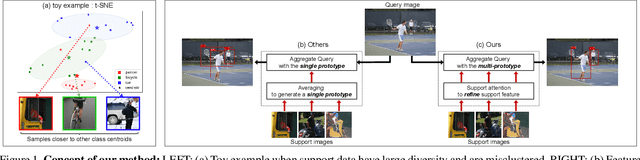

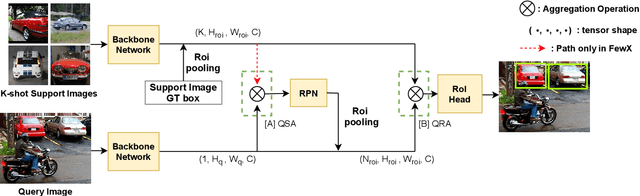

Few-shot object detection aims to detect instances of specific categories in a query image with only a handful of support samples. Although this takes less effort than obtaining enough annotated images for supervised object detection, it results in a far inferior performance compared to the conventional object detection methods. In this paper, we propose a meta-learning-based approach that considers the unique characteristics of each support sample. Rather than simply averaging the information of the support samples to generate a single prototype per category, our method can better utilize the information of each support sample by treating each support sample as an individual prototype. Specifically, we introduce two types of attention mechanisms for aggregating the query and support feature maps. The first is to refine the information of few-shot samples by extracting shared information between the support samples through attention. Second, each support sample is used as a class code to leverage the information by comparing similarities between each support feature and query features. Our proposed method is complementary to the previous methods, making it easy to plug and play for further improvement. We have evaluated our method on PASCAL VOC and COCO benchmarks, and the results verify the effectiveness of our method. In particular, the advantages of our method are maximized when there is more diversity among support data.
StyleUV: Diverse and High-fidelity UV Map Generative Model
Nov 25, 2020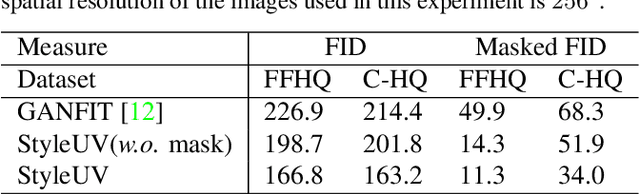
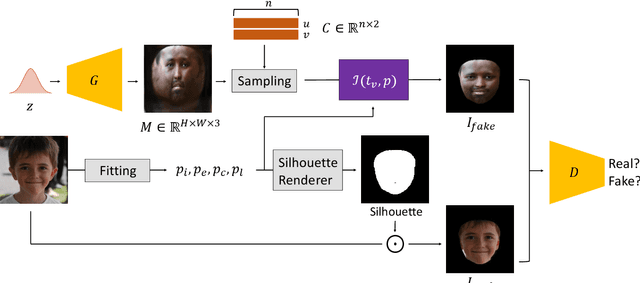


Reconstructing 3D human faces in the wild with the 3D Morphable Model (3DMM) has become popular in recent years. While most prior work focuses on estimating more robust and accurate geometry, relatively little attention has been paid to improving the quality of the texture model. Meanwhile, with the advent of Generative Adversarial Networks (GANs), there has been great progress in reconstructing realistic 2D images. Recent work demonstrates that GANs trained with abundant high-quality UV maps can produce high-fidelity textures superior to those produced by existing methods. However, acquiring such high-quality UV maps is difficult because they are expensive to acquire, requiring laborious processes to refine. In this work, we present a novel UV map generative model that learns to generate diverse and realistic synthetic UV maps without requiring high-quality UV maps for training. Our proposed framework can be trained solely with in-the-wild images (i.e., UV maps are not required) by leveraging a combination of GANs and a differentiable renderer. Both quantitative and qualitative evaluations demonstrate that our proposed texture model produces more diverse and higher fidelity textures compared to existing methods.
Motion Feature Network: Fixed Motion Filter for Action Recognition
Aug 01, 2018
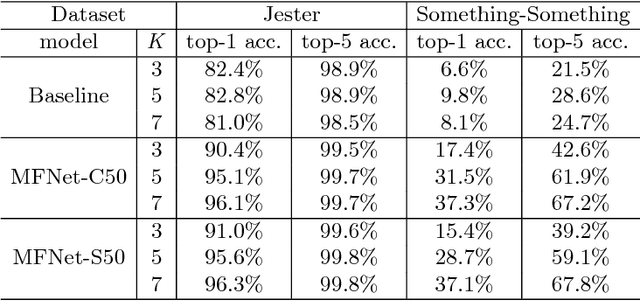
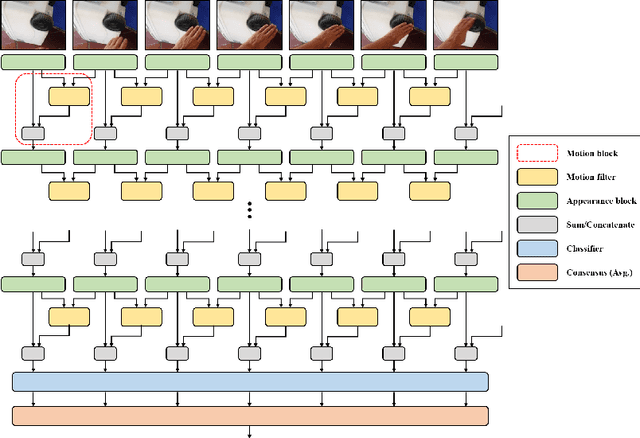
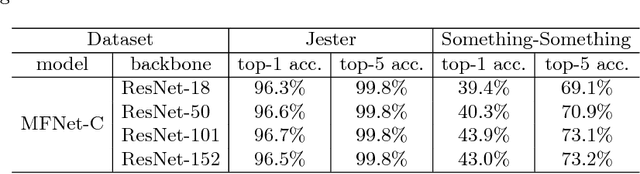
Spatio-temporal representations in frame sequences play an important role in the task of action recognition. Previously, a method of using optical flow as a temporal information in combination with a set of RGB images that contain spatial information has shown great performance enhancement in the action recognition tasks. However, it has an expensive computational cost and requires two-stream (RGB and optical flow) framework. In this paper, we propose MFNet (Motion Feature Network) containing motion blocks which make it possible to encode spatio-temporal information between adjacent frames in a unified network that can be trained end-to-end. The motion block can be attached to any existing CNN-based action recognition frameworks with only a small additional cost. We evaluated our network on two of the action recognition datasets (Jester and Something-Something) and achieved competitive performances for both datasets by training the networks from scratch.
Where to Play: Retrieval of Video Segments using Natural-Language Queries
Jul 02, 2017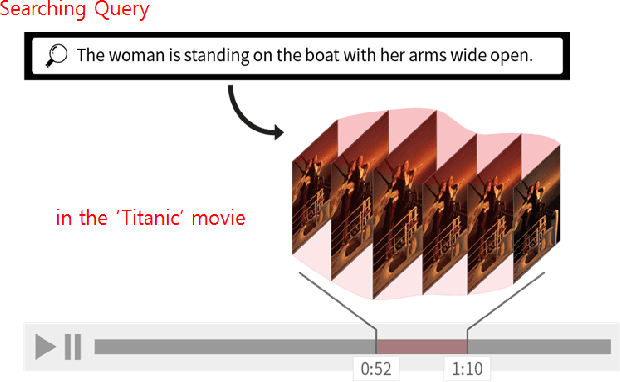
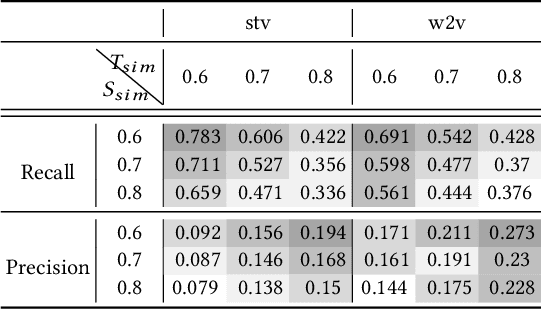
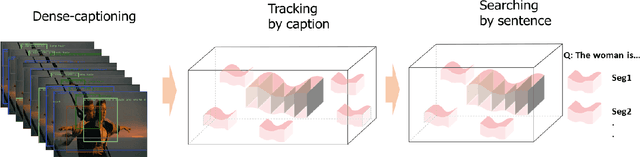
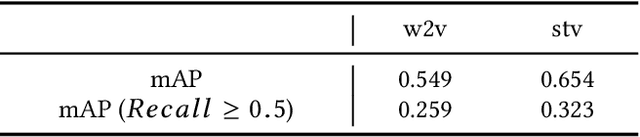
In this paper, we propose a new approach for retrieval of video segments using natural language queries. Unlike most previous approaches such as concept-based methods or rule-based structured models, the proposed method uses image captioning model to construct sentential queries for visual information. In detail, our approach exploits multiple captions generated by visual features in each image with `Densecap'. Then, the similarities between captions of adjacent images are calculated, which is used to track semantically similar captions over multiple frames. Besides introducing this novel idea of 'tracking by captioning', the proposed method is one of the first approaches that uses a language generation model learned by neural networks to construct semantic query describing the relations and properties of visual information. To evaluate the effectiveness of our approach, we have created a new evaluation dataset, which contains about 348 segments of scenes in 20 movie-trailers. Through quantitative and qualitative evaluation, we show that our method is effective for retrieval of video segments using natural language queries.