 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere to Play: Retrieval of Video Segments using Natural-Language Queries
Paper and Code
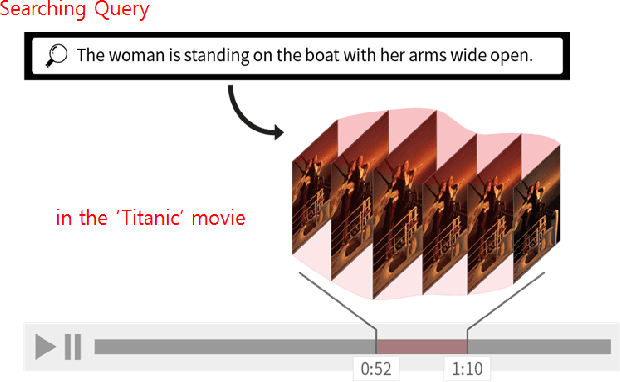
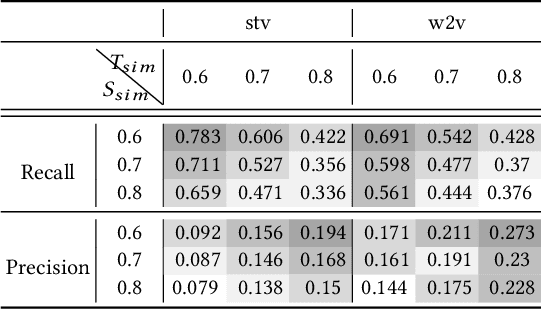
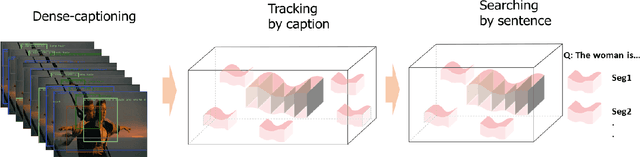
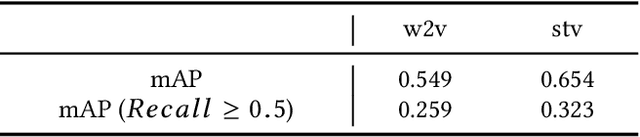
In this paper, we propose a new approach for retrieval of video segments using natural language queries. Unlike most previous approaches such as concept-based methods or rule-based structured models, the proposed method uses image captioning model to construct sentential queries for visual information. In detail, our approach exploits multiple captions generated by visual features in each image with `Densecap'. Then, the similarities between captions of adjacent images are calculated, which is used to track semantically similar captions over multiple frames. Besides introducing this novel idea of 'tracking by captioning', the proposed method is one of the first approaches that uses a language generation model learned by neural networks to construct semantic query describing the relations and properties of visual information. To evaluate the effectiveness of our approach, we have created a new evaluation dataset, which contains about 348 segments of scenes in 20 movie-trailers. Through quantitative and qualitative evaluation, we show that our method is effective for retrieval of video segments using natural language queries.