 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDPose: Real-Time Multi-Person Pose Estimation via Mixture Density Model
Feb 17, 2023One of the major challenges in multi-person pose estimation is instance-aware keypoint estimation. Previous methods address this problem by leveraging an off-the-shelf detector, heuristic post-grouping process or explicit instance identification process, hindering further improvements in the inference speed which is an important factor for practical applications. From the statistical point of view, those additional processes for identifying instances are necessary to bypass learning the high-dimensional joint distribution of human keypoints, which is a critical factor for another major challenge, the occlusion scenario. In this work, we propose a novel framework of single-stage instance-aware pose estimation by modeling the joint distribution of human keypoints with a mixture density model, termed as MDPose. Our MDPose estimates the distribution of human keypoints' coordinates using a mixture density model with an instance-aware keypoint head consisting simply of 8 convolutional layers. It is trained by minimizing the negative log-likelihood of the ground truth keypoints. Also, we propose a simple yet effective training strategy, Random Keypoint Grouping (RKG), which significantly alleviates the underflow problem leading to successful learning of relations between keypoints. On OCHuman dataset, which consists of images with highly occluded people, our MDPose achieves state-of-the-art performance by successfully learning the high-dimensional joint distribution of human keypoints. Furthermore, our MDPose shows significant improvement in inference speed with a competitive accuracy on MS COCO, a widely-used human keypoint dataset, thanks to the proposed much simpler single-stage pipeline.
Pose estimator and tracker using temporal flow maps for limbs
May 23, 2019
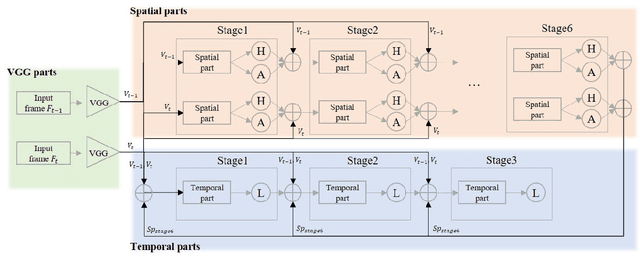

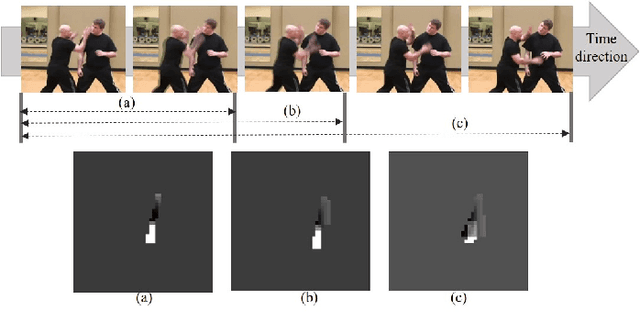
For human pose estimation in videos, it is significant how to use temporal information between frames. In this paper, we propose temporal flow maps for limbs (TML) and a multi-stride method to estimate and track human poses. The proposed temporal flow maps are unit vectors describing the limbs' movements. We constructed a network to learn both spatial information and temporal information end-to-end. Spatial information such as joint heatmaps and part affinity fields is regressed in the spatial network part, and the TML is regressed in the temporal network part. We also propose a data augmentation method to learn various types of TML better. The proposed multi-stride method expands the data by randomly selecting two frames within a defined range. We demonstrate that the proposed method efficiently estimates and tracks human poses on the PoseTrack 2017 and 2018 datasets.
Where to Play: Retrieval of Video Segments using Natural-Language Queries
Jul 02, 2017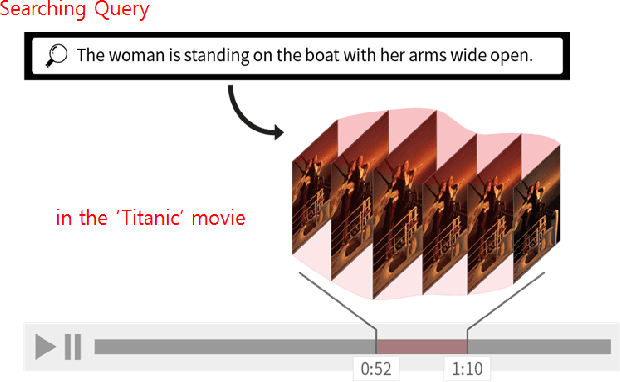
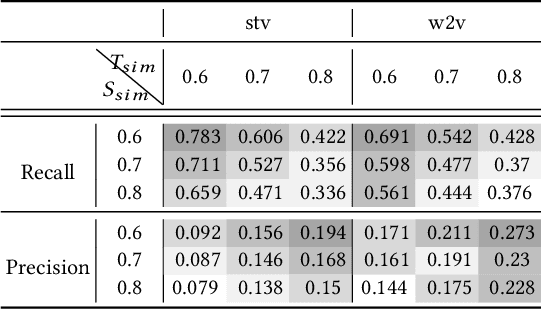
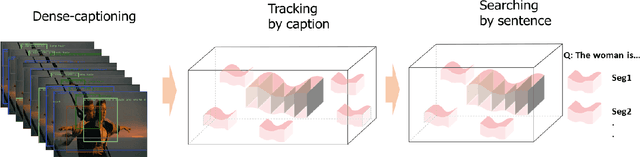
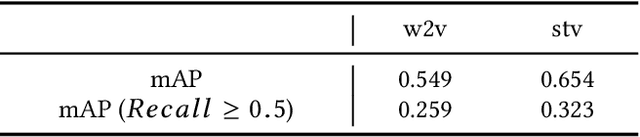
In this paper, we propose a new approach for retrieval of video segments using natural language queries. Unlike most previous approaches such as concept-based methods or rule-based structured models, the proposed method uses image captioning model to construct sentential queries for visual information. In detail, our approach exploits multiple captions generated by visual features in each image with `Densecap'. Then, the similarities between captions of adjacent images are calculated, which is used to track semantically similar captions over multiple frames. Besides introducing this novel idea of 'tracking by captioning', the proposed method is one of the first approaches that uses a language generation model learned by neural networks to construct semantic query describing the relations and properties of visual information. To evaluate the effectiveness of our approach, we have created a new evaluation dataset, which contains about 348 segments of scenes in 20 movie-trailers. Through quantitative and qualitative evaluation, we show that our method is effective for retrieval of video segments using natural language queries.
3D Human Pose Estimation Using Convolutional Neural Networks with 2D Pose Information
Sep 08, 2016



While there has been a success in 2D human pose estimation with convolutional neural networks (CNNs), 3D human pose estimation has not been thoroughly studied. In this paper, we tackle the 3D human pose estimation task with end-to-end learning using CNNs. Relative 3D positions between one joint and the other joints are learned via CNNs. The proposed method improves the performance of CNN with two novel ideas. First, we added 2D pose information to estimate a 3D pose from an image by concatenating 2D pose estimation result with the features from an image. Second, we have found that more accurate 3D poses are obtained by combining information on relative positions with respect to multiple joints, instead of just one root joint. Experimental results show that the proposed method achieves comparable performance to the state-of-the-art methods on Human 3.6m dataset.