 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMi:dm 2.0 Korea-centric Bilingual Language Models
Jan 14, 2026We introduce Mi:dm 2.0, a bilingual large language model (LLM) specifically engineered to advance Korea-centric AI. This model goes beyond Korean text processing by integrating the values, reasoning patterns, and commonsense knowledge inherent to Korean society, enabling nuanced understanding of cultural contexts, emotional subtleties, and real-world scenarios to generate reliable and culturally appropriate responses. To address limitations of existing LLMs, often caused by insufficient or low-quality Korean data and lack of cultural alignment, Mi:dm 2.0 emphasizes robust data quality through a comprehensive pipeline that includes proprietary data cleansing, high-quality synthetic data generation, strategic data mixing with curriculum learning, and a custom Korean-optimized tokenizer to improve efficiency and coverage. To realize this vision, we offer two complementary configurations: Mi:dm 2.0 Base (11.5B parameters), built with a depth-up scaling strategy for general-purpose use, and Mi:dm 2.0 Mini (2.3B parameters), optimized for resource-constrained environments and specialized tasks. Mi:dm 2.0 achieves state-of-the-art performance on Korean-specific benchmarks, with top-tier zero-shot results on KMMLU and strong internal evaluation results across language, humanities, and social science tasks. The Mi:dm 2.0 lineup is released under the MIT license to support extensive research and commercial use. By offering accessible and high-performance Korea-centric LLMs, KT aims to accelerate AI adoption across Korean industries, public services, and education, strengthen the Korean AI developer community, and lay the groundwork for the broader vision of K-intelligence. Our models are available at https://huggingface.co/K-intelligence. For technical inquiries, please contact midm-llm@kt.com.
Localization Meets Uncertainty: Uncertainty-Aware Multi-Modal Localization
Apr 10, 2025Reliable localization is critical for robot navigation in complex indoor environments. In this paper, we propose an uncertainty-aware localization method that enhances the reliability of localization outputs without modifying the prediction model itself. This study introduces a percentile-based rejection strategy that filters out unreliable 3-DoF pose predictions based on aleatoric and epistemic uncertainties the network estimates. We apply this approach to a multi-modal end-to-end localization that fuses RGB images and 2D LiDAR data, and we evaluate it across three real-world datasets collected using a commercialized serving robot. Experimental results show that applying stricter uncertainty thresholds consistently improves pose accuracy. Specifically, the mean position error is reduced by 41.0%, 56.7%, and 69.4%, and the mean orientation error by 55.6%, 65.7%, and 73.3%, when applying 90%, 80%, and 70% thresholds, respectively. Furthermore, the rejection strategy effectively removes extreme outliers, resulting in better alignment with ground truth trajectories. To the best of our knowledge, this is the first study to quantitatively demonstrate the benefits of percentile-based uncertainty rejection in multi-modal end-to-end localization tasks. Our approach provides a practical means to enhance the reliability and accuracy of localization systems in real-world deployments.
Advancing 3D Gaussian Splatting Editing with Complementary and Consensus Information
Mar 14, 2025



We present a novel framework for enhancing the visual fidelity and consistency of text-guided 3D Gaussian Splatting (3DGS) editing. Existing editing approaches face two critical challenges: inconsistent geometric reconstructions across multiple viewpoints, particularly in challenging camera positions, and ineffective utilization of depth information during image manipulation, resulting in over-texture artifacts and degraded object boundaries. To address these limitations, we introduce: 1) A complementary information mutual learning network that enhances depth map estimation from 3DGS, enabling precise depth-conditioned 3D editing while preserving geometric structures. 2) A wavelet consensus attention mechanism that effectively aligns latent codes during the diffusion denoising process, ensuring multi-view consistency in the edited results. Through extensive experimentation, our method demonstrates superior performance in rendering quality and view consistency compared to state-of-the-art approaches. The results validate our framework as an effective solution for text-guided editing of 3D scenes.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Transferring Ultrahigh-Field Representations for Intensity-Guided Brain Segmentation of Low-Field Magnetic Resonance Imaging
Feb 13, 2024



Ultrahigh-field (UHF) magnetic resonance imaging (MRI), i.e., 7T MRI, provides superior anatomical details of internal brain structures owing to its enhanced signal-to-noise ratio and susceptibility-induced contrast. However, the widespread use of 7T MRI is limited by its high cost and lower accessibility compared to low-field (LF) MRI. This study proposes a deep-learning framework that systematically fuses the input LF magnetic resonance feature representations with the inferred 7T-like feature representations for brain image segmentation tasks in a 7T-absent environment. Specifically, our adaptive fusion module aggregates 7T-like features derived from the LF image by a pre-trained network and then refines them to be effectively assimilable UHF guidance into LF image features. Using intensity-guided features obtained from such aggregation and assimilation, segmentation models can recognize subtle structural representations that are usually difficult to recognize when relying only on LF features. Beyond such advantages, this strategy can seamlessly be utilized by modulating the contrast of LF features in alignment with UHF guidance, even when employing arbitrary segmentation models. Exhaustive experiments demonstrated that the proposed method significantly outperformed all baseline models on both brain tissue and whole-brain segmentation tasks; further, it exhibited remarkable adaptability and scalability by successfully integrating diverse segmentation models and tasks. These improvements were not only quantifiable but also visible in the superlative visual quality of segmentation masks.
FusionLoc: Camera-2D LiDAR Fusion Using Multi-Head Self-Attention for End-to-End Serving Robot Relocalization
Mar 13, 2023With the recent development of autonomous driving technology, as the pursuit of efficiency for repetitive tasks and the value of non-face-to-face services increase, mobile service robots such as delivery robots and serving robots attract attention, and their demands are increasing day by day. However, when something goes wrong, most commercial serving robots need to return to their starting position and orientation to operate normally again. In this paper, we focus on end-to-end relocalization of serving robots to address the problem. It is to predict robot pose directly from only the onboard sensor data using neural networks. In particular, we propose a deep neural network architecture for the relocalization based on camera-2D LiDAR sensor fusion. We call the proposed method FusionLoc. In the proposed method, the multi-head self-attention complements different types of information captured by the two sensors. Our experiments on a dataset collected by a commercial serving robot demonstrate that FusionLoc can provide better performances than previous relocalization methods taking only a single image or a 2D LiDAR point cloud as well as a straightforward fusion method concatenating their features.
Deep Reinforcement Learning Designed RF Pulse: $DeepRF_{SLR}$
Dec 19, 2019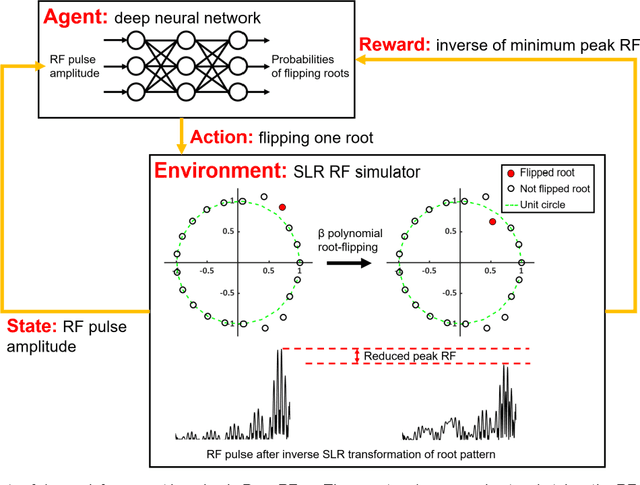
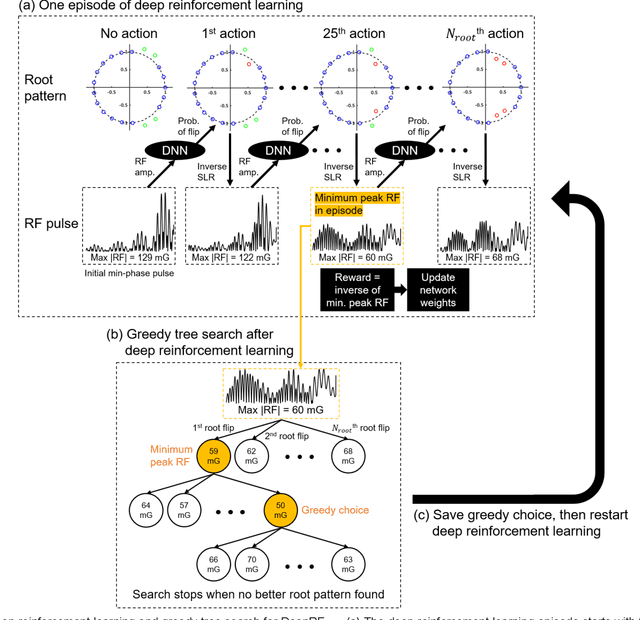
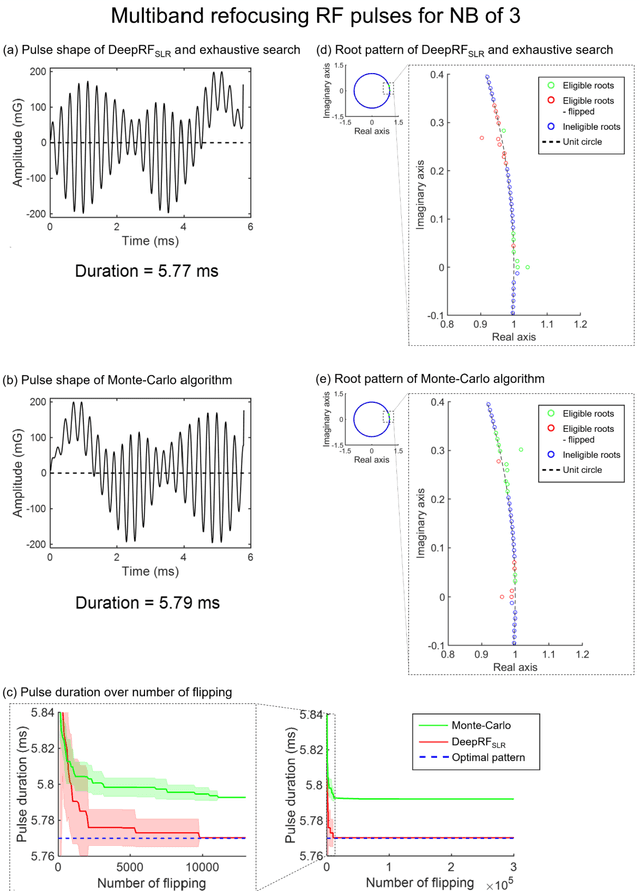
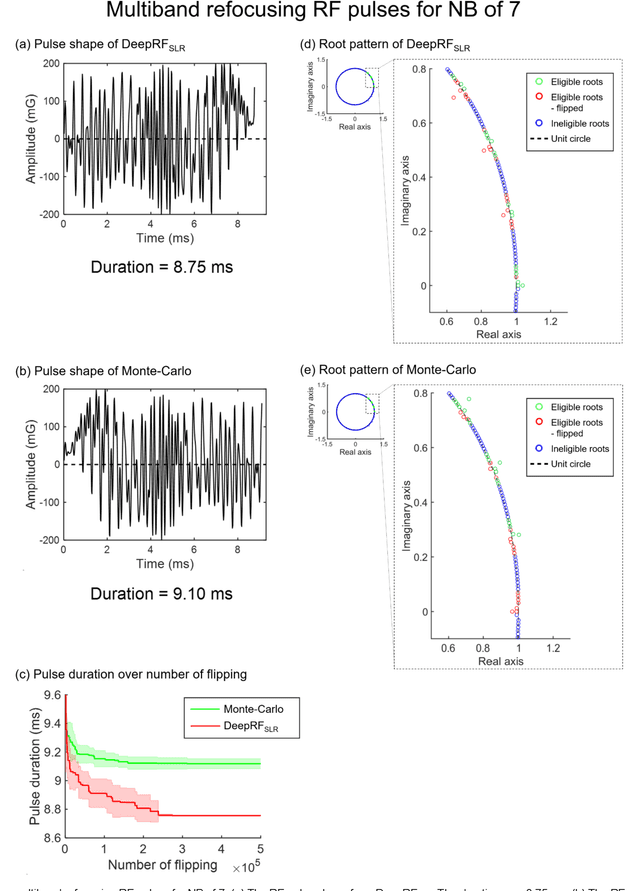
A novel approach of applying deep reinforcement learning to an RF pulse design is introduced. This method, which is referred to as $DeepRF_{SLR}$, is designed to minimize the peak amplitude or, equivalently, minimize the pulse duration of a multiband refocusing pulse generated by the Shinar Le-Roux (SLR) algorithm. In the method, the root pattern of SLR polynomial, which determines the RF pulse shape, is optimized by iterative applications of deep reinforcement learning and greedy tree search. When tested for the designs of the multiband factors of three and seven RFs, $DeepRF_{SLR}$ demonstrated improved performance compared to conventional methods, generating shorter duration RF pulses in shorter computational time. In the experiments, the RF pulse from $DeepRF_{SLR}$ produced a slice profile similar to the minimum-phase SLR RF pulse and the profiles matched to that of the computer simulation. Our approach suggests a new way of designing an RF by applying a machine learning algorithm, demonstrating a machine-designed MRI sequence.
Pose estimator and tracker using temporal flow maps for limbs
May 23, 2019
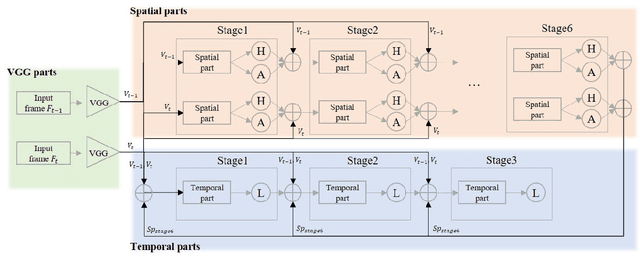

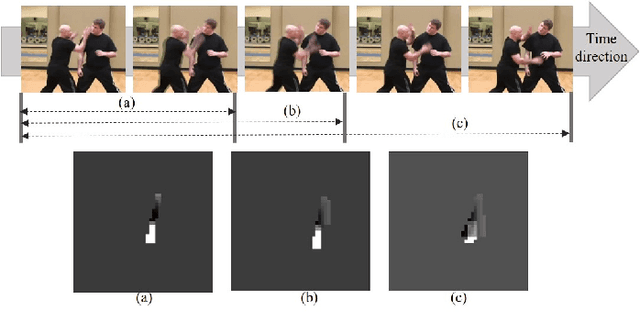
For human pose estimation in videos, it is significant how to use temporal information between frames. In this paper, we propose temporal flow maps for limbs (TML) and a multi-stride method to estimate and track human poses. The proposed temporal flow maps are unit vectors describing the limbs' movements. We constructed a network to learn both spatial information and temporal information end-to-end. Spatial information such as joint heatmaps and part affinity fields is regressed in the spatial network part, and the TML is regressed in the temporal network part. We also propose a data augmentation method to learn various types of TML better. The proposed multi-stride method expands the data by randomly selecting two frames within a defined range. We demonstrate that the proposed method efficiently estimates and tracks human poses on the PoseTrack 2017 and 2018 datasets.