 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretraining Vision-Language Model for Difference Visual Question Answering in Longitudinal Chest X-rays
Feb 14, 2024



Difference visual question answering (diff-VQA) is a challenging task that requires answering complex questions based on differences between a pair of images. This task is particularly important in reading chest X-ray images because radiologists often compare multiple images of the same patient taken at different times to track disease progression and changes in its severity in their clinical practice. However, previous works focused on designing specific network architectures for the diff-VQA task, missing opportunities to enhance the model's performance using a pretrained vision-language model (VLM). Here, we introduce a novel VLM called PLURAL, which is pretrained on natural and longitudinal chest X-ray data for the diff-VQA task. The model is developed using a step-by-step approach, starting with being pretrained on natural images and texts, followed by being trained using longitudinal chest X-ray data. The longitudinal data consist of pairs of X-ray images, along with question-answer sets and radiologist's reports that describe the changes in lung abnormalities and diseases over time. Our experimental results show that the PLURAL model outperforms state-of-the-art methods not only in diff-VQA for longitudinal X-rays but also in conventional VQA for a single X-ray image. Through extensive experiments, we demonstrate the effectiveness of the proposed VLM architecture and pretraining method in improving the model's performance.
Generalizing Visual Question Answering from Synthetic to Human-Written Questions via a Chain of QA with a Large Language Model
Jan 16, 2024



Visual question answering (VQA) is a task where an image is given, and a series of questions are asked about the image. To build an efficient VQA algorithm, a large amount of QA data is required which is very expensive. Generating synthetic QA pairs based on templates is a practical way to obtain data. However, VQA models trained on those data do not perform well on complex, human-written questions. To address this issue, we propose a new method called {\it chain of QA for human-written questions} (CoQAH). CoQAH utilizes a sequence of QA interactions between a large language model and a VQA model trained on synthetic data to reason and derive logical answers for human-written questions. We tested the effectiveness of CoQAH on two types of human-written VQA datasets for 3D-rendered and chest X-ray images and found that it achieved state-of-the-art accuracy in both types of data. Notably, CoQAH outperformed general vision-language models, VQA models, and medical foundation models with no finetuning.
Fast and accurate sparse-view CBCT reconstruction using meta-learned neural attenuation field and hash-encoding regularization
Dec 04, 2023



Cone beam computed tomography (CBCT) is an emerging medical imaging technique to visualize the internal anatomical structures of patients. During a CBCT scan, several projection images of different angles or views are collectively utilized to reconstruct a tomographic image. However, reducing the number of projections in a CBCT scan while preserving the quality of a reconstructed image is challenging due to the nature of an ill-posed inverse problem. Recently, a neural attenuation field (NAF) method was proposed by adopting a neural radiance field algorithm as a new way for CBCT reconstruction, demonstrating fast and promising results using only 50 views. However, decreasing the number of projections is still preferable to reduce potential radiation exposure, and a faster reconstruction time is required considering a typical scan time. In this work, we propose a fast and accurate sparse-view CBCT reconstruction (FACT) method to provide better reconstruction quality and faster optimization speed in the minimal number of view acquisitions ($<$ 50 views). In the FACT method, we meta-trained a neural network and a hash-encoder using a few scans (= 15), and a new regularization technique is utilized to reconstruct the details of an anatomical structure. In conclusion, we have shown that the FACT method produced better, and faster reconstruction results over the other conventional algorithms based on CBCT scans of different body parts (chest, head, and abdomen) and CT vendors (Siemens, Phillips, and GE).
Coil2Coil: Self-supervised MR image denoising using phased-array coil images
Aug 16, 2022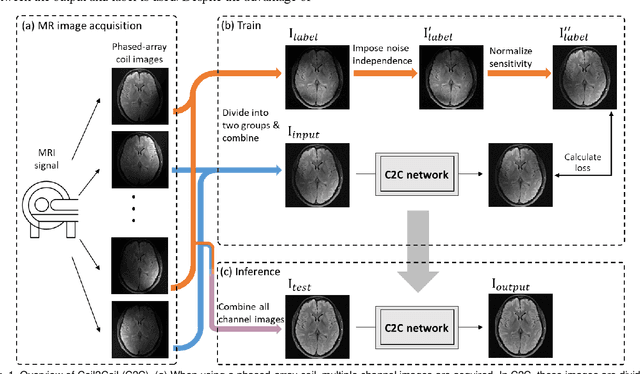
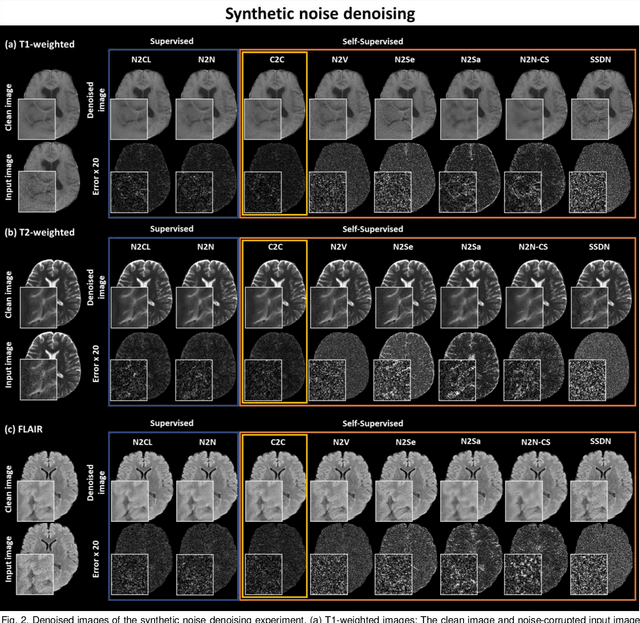
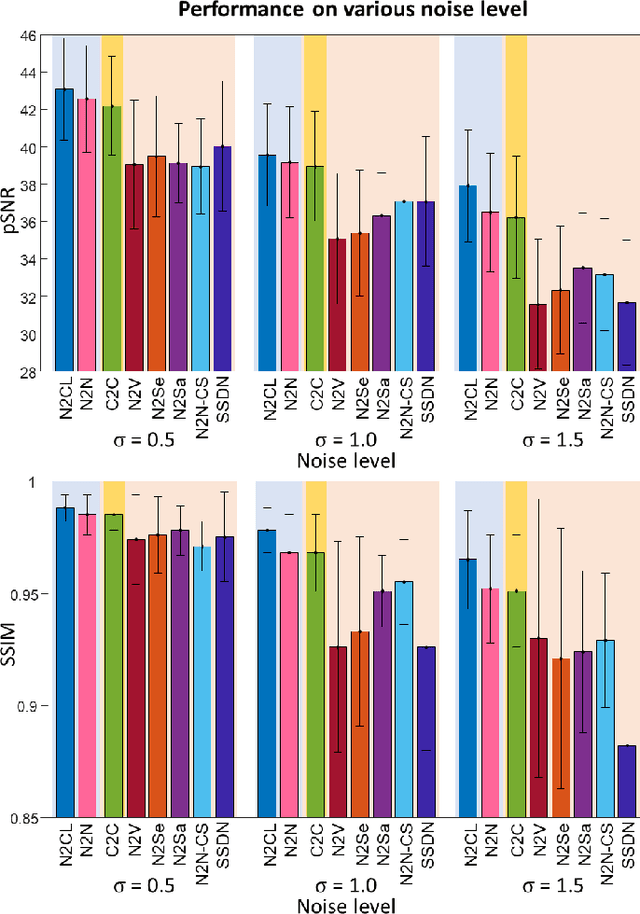
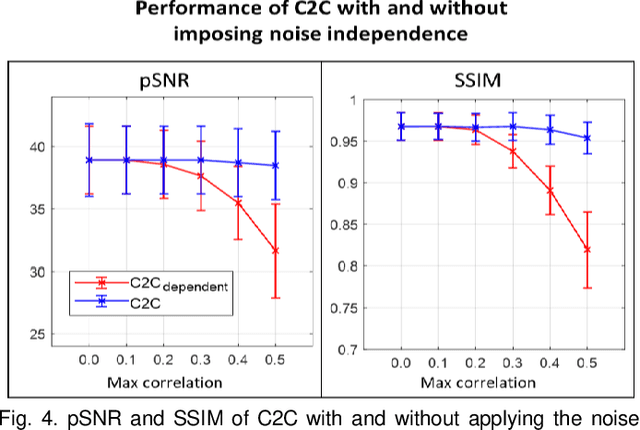
Denoising of magnetic resonance images is beneficial in improving the quality of low signal-to-noise ratio images. Recently, denoising using deep neural networks has demonstrated promising results. Most of these networks, however, utilize supervised learning, which requires large training images of noise-corrupted and clean image pairs. Obtaining training images, particularly clean images, is expensive and time-consuming. Hence, methods such as Noise2Noise (N2N) that require only pairs of noise-corrupted images have been developed to reduce the burden of obtaining training datasets. In this study, we propose a new self-supervised denoising method, Coil2Coil (C2C), that does not require the acquisition of clean images or paired noise-corrupted images for training. Instead, the method utilizes multichannel data from phased-array coils to generate training images. First, it divides and combines multichannel coil images into two images, one for input and the other for label. Then, they are processed to impose noise independence and sensitivity normalization such that they can be used for the training images of N2N. For inference, the method inputs a coil-combined image (e.g., DICOM image), enabling a wide application of the method. When evaluated using synthetic noise-added images, C2C shows the best performance against several self-supervised methods, reporting comparable outcomes to supervised methods. When testing the DICOM images, C2C successfully denoised real noise without showing structure-dependent residuals in the error maps. Because of the significant advantage of not requiring additional scans for clean or paired images, the method can be easily utilized for various clinical applications.
DeepRF: Deep Reinforcement Learning Designed RadioFrequency Waveform in MRI
May 07, 2021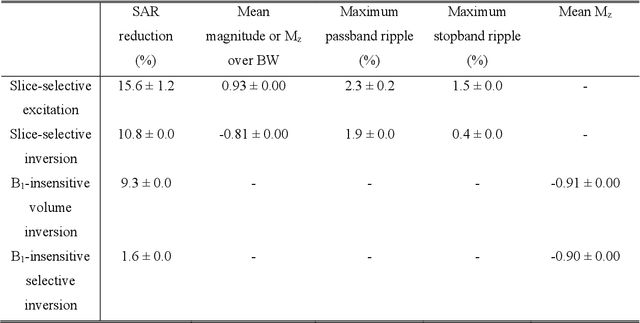
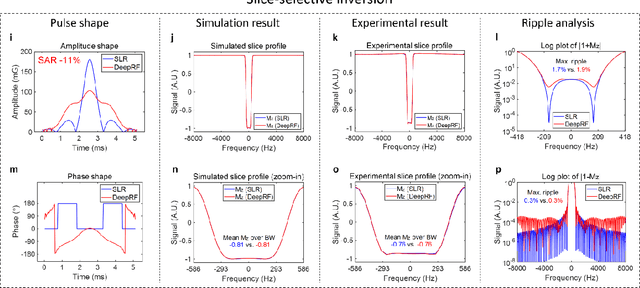
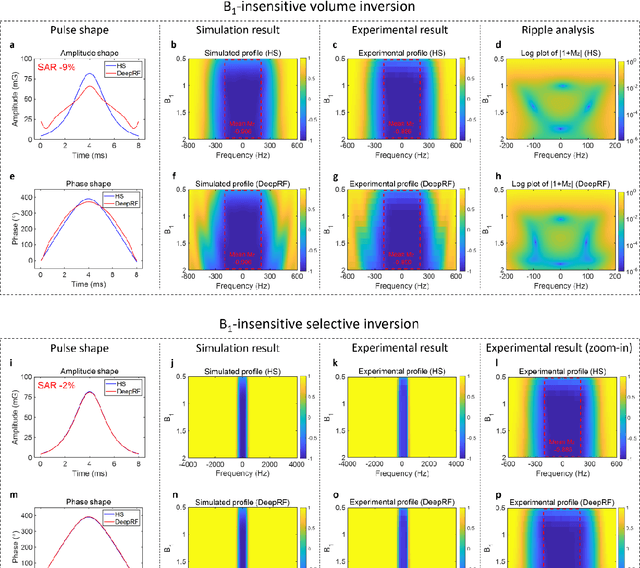
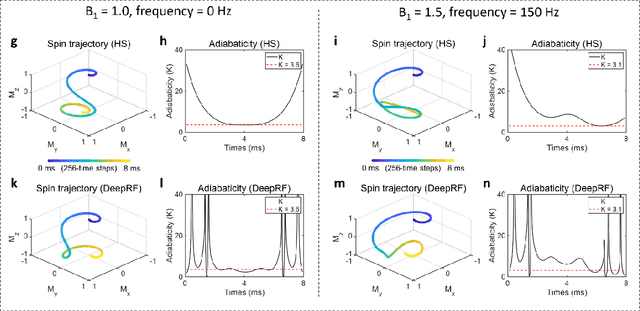
A carefully engineered radiofrequency (RF) pulse plays a key role in a number of systems such as mobile phone, radar, and magnetic resonance imaging (MRI). The design of an RF waveform, however, is often posed as an inverse problem that has no general solution. As a result, various design methods each with a specific purpose have been developed based on the intuition of human experts. In this work, we propose an artificial intelligence-powered RF pulse design framework, DeepRF, which utilizes the self-learning characteristics of deep reinforcement learning (DRL) to generate a novel RF beyond human intuition. Additionally, the method can design various types of RF pulses via customized reward functions. The algorithm of DeepRF consists of two modules: the RF generation module, which utilizes DRL to explore new RF pulses, and the RF refinement module, which optimizes the seed RF pulses from the generation module via gradient ascent. The effectiveness of DeepRF is demonstrated using four exemplary RF pulses, slice-selective excitation pulse, slice-selective inversion pulse, B1-insensitive volume inversion pulse, and B1-insensitive selective inversion pulse, that are commonly used in MRI. The results show that the DeepRF-designed pulses successfully satisfy the design criteria while improving specific absorption rates when compared to those of the conventional RF pulses. Further analyses suggest that the DeepRF-designed pulses utilize new mechanisms of magnetization manipulation that are difficult to be explained by conventional theory, suggesting the potentials of DeepRF in discovering unseen design dimensions beyond human intuition. This work may lay the foundation for an emerging field of AI-driven RF waveform design.
DIFFnet: Diffusion parameter mapping network generalized for input diffusion gradient schemes and bvalues
Feb 04, 2021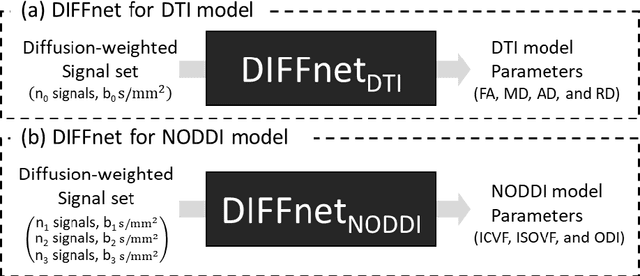
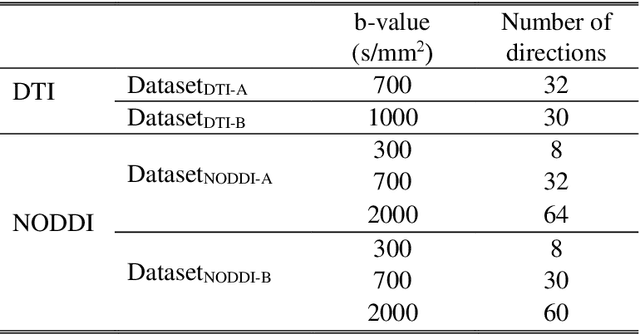
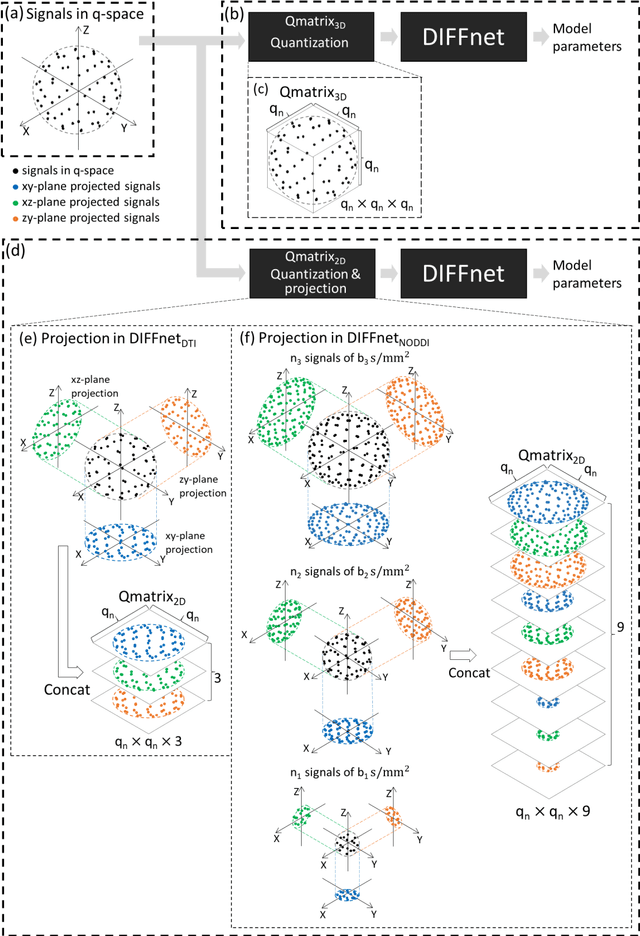
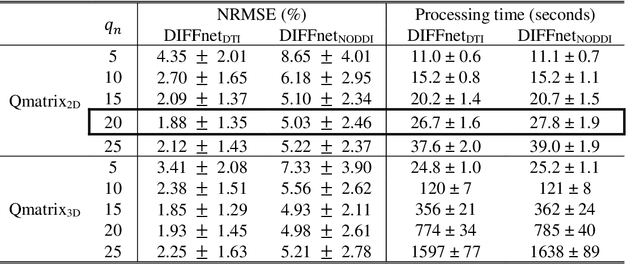
In MRI, deep neural networks have been proposed to reconstruct diffusion model parameters. However, the inputs of the networks were designed for a specific diffusion gradient scheme (i.e., diffusion gradient directions and numbers) and a specific b-value that are the same as the training data. In this study, a new deep neural network, referred to as DIFFnet, is developed to function as a generalized reconstruction tool of the diffusion-weighted signals for various gradient schemes and b-values. For generalization, diffusion signals are normalized in a q-space and then projected and quantized, producing a matrix (Qmatrix) as an input for the network. To demonstrate the validity of this approach, DIFFnet is evaluated for diffusion tensor imaging (DIFFnetDTI) and for neurite orientation dispersion and density imaging (DIFFnetNODDI). In each model, two datasets with different gradient schemes and b-values are tested. The results demonstrate accurate reconstruction of the diffusion parameters at substantially reduced processing time (approximately 8.7 times and 2240 times faster processing time than conventional methods in DTI and NODDI, respectively; less than 4% mean normalized root-mean-square errors (NRMSE) in DTI and less than 8% in NODDI). The generalization capability of the networks was further validated using reduced numbers of diffusion signals from the datasets. Different from previously proposed deep neural networks, DIFFnet does not require any specific gradient scheme and b-value for its input. As a result, it can be adopted as an online reconstruction tool for various complex diffusion imaging.
Deep Reinforcement Learning Designed RF Pulse: $DeepRF_{SLR}$
Dec 19, 2019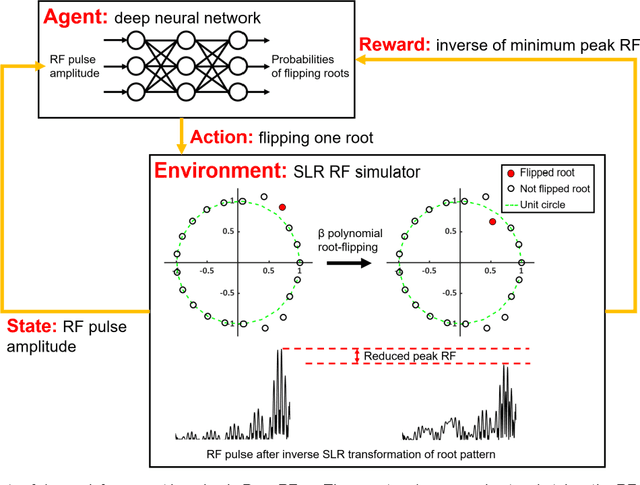
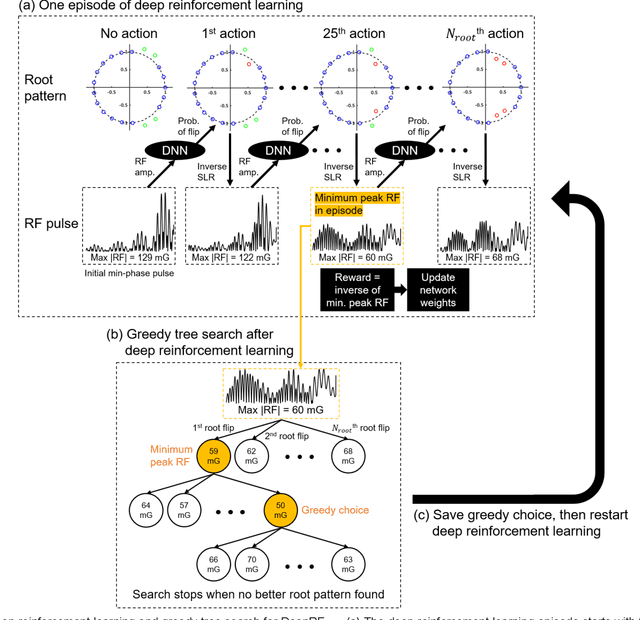
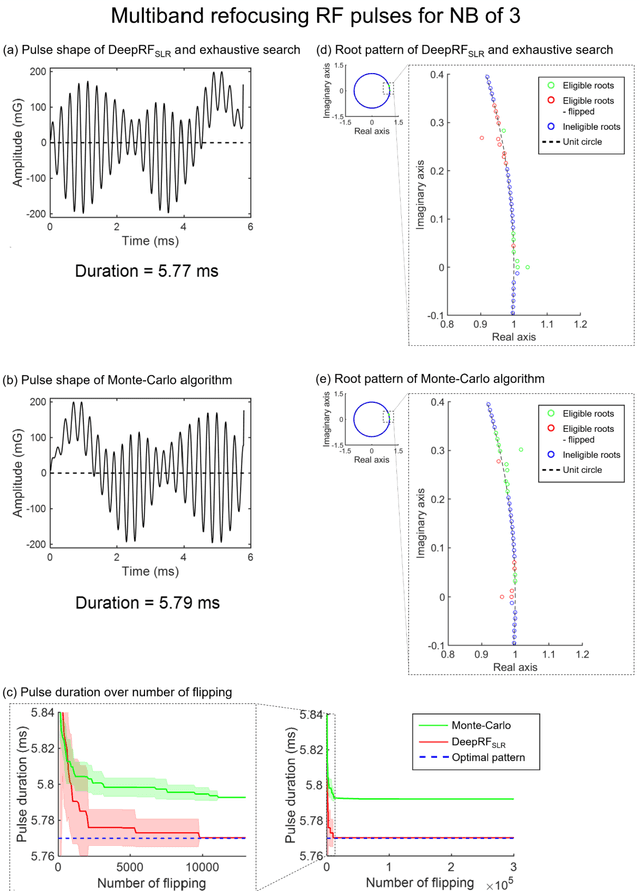
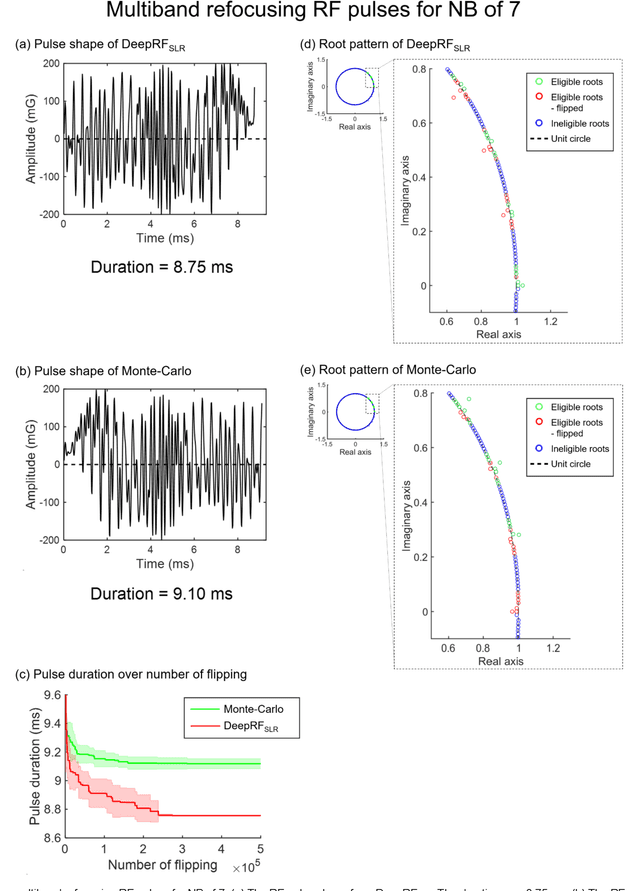
A novel approach of applying deep reinforcement learning to an RF pulse design is introduced. This method, which is referred to as $DeepRF_{SLR}$, is designed to minimize the peak amplitude or, equivalently, minimize the pulse duration of a multiband refocusing pulse generated by the Shinar Le-Roux (SLR) algorithm. In the method, the root pattern of SLR polynomial, which determines the RF pulse shape, is optimized by iterative applications of deep reinforcement learning and greedy tree search. When tested for the designs of the multiband factors of three and seven RFs, $DeepRF_{SLR}$ demonstrated improved performance compared to conventional methods, generating shorter duration RF pulses in shorter computational time. In the experiments, the RF pulse from $DeepRF_{SLR}$ produced a slice profile similar to the minimum-phase SLR RF pulse and the profiles matched to that of the computer simulation. Our approach suggests a new way of designing an RF by applying a machine learning algorithm, demonstrating a machine-designed MRI sequence.