 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSilicon Bureaucracy and AI Test-Oriented Education: Contamination Sensitivity and Score Confidence in LLM Benchmarks
Mar 23, 2026Public benchmarks increasingly govern how large language models (LLMs) are ranked, selected, and deployed. We frame this benchmark-centered regime as Silicon Bureaucracy and AI Test-Oriented Education, and argue that it rests on a fragile assumption: that benchmark scores directly reflect genuine generalization. In practice, however, such scores may conflate exam-oriented competence with principled capability, especially when contamination and semantic leakage are difficult to exclude from modern training pipelines. We therefore propose an audit framework for analyzing contamination sensitivity and score confidence in LLM benchmarks. Using a router-worker setup, we compare a clean-control condition with noisy conditions in which benchmark problems are systematically deleted, rewritten, and perturbed before being passed downstream. For a genuinely clean benchmark, noisy conditions should not consistently outperform the clean-control baseline. Yet across multiple models, we find widespread but heterogeneous above-baseline gains under noisy conditions, indicating that benchmark-related cues may be reassembled and can reactivate contamination-related memory. These results suggest that similar benchmark scores may carry substantially different levels of confidence. Rather than rejecting benchmarks altogether, we argue that benchmark-based evaluation should be supplemented with explicit audits of contamination sensitivity and score confidence.
Ruyi2 Technical Report
Feb 26, 2026Large Language Models (LLMs) face significant challenges regarding deployment costs and latency, necessitating adaptive computing strategies. Building upon the AI Flow framework, we introduce Ruyi2 as an evolution of our adaptive model series designed for efficient variable-depth computation. While early-exit architectures offer a viable efficiency-performance balance, the Ruyi model and existing methods often struggle with optimization complexity and compatibility with large-scale distributed training. To bridge this gap, Ruyi2 introduces a stable "Familial Model" based on Megatron-LM. By using 3D parallel training, it achieves a 2-3 times speedup over Ruyi, while performing comparably to same-sized Qwen3 models. These results confirm that family-based parameter sharing is a highly effective strategy, establishing a new "Train Once, Deploy Many" paradigm and providing a key reference for balancing architectural efficiency with high-performance capabilities.
CreditAudit: 2D Auditing for LLM Evaluation and Selection
Jan 23, 2026Leaderboard scores on public benchmarks have been steadily rising and converging, with many frontier language models now separated by only marginal differences. However, these scores often fail to match users' day to day experience, because system prompts, output protocols, and interaction modes evolve under routine iteration, and in agentic multi step pipelines small protocol shifts can trigger disproportionate failures, leaving practitioners uncertain about which model to deploy. We propose CreditAudit, a deployment oriented credit audit framework that evaluates models under a family of semantically aligned and non adversarial system prompt templates across multiple benchmarks, reporting mean ability as average performance across scenarios and scenario induced fluctuation sigma as a stability risk signal, and further mapping volatility into interpretable credit grades from AAA to BBB via cross model quantiles with diagnostics that mitigate template difficulty drift. Controlled experiments on GPQA, TruthfulQA, and MMLU Pro show that models with similar mean ability can exhibit substantially different fluctuation, and stability risk can overturn prioritization decisions in agentic or high failure cost regimes. By providing a 2D and grade based language for regime specific selection, CreditAudit supports tiered deployment and more disciplined allocation of testing and monitoring effort, enabling more objective and trustworthy model evaluation for real world use.
Single-Pixel Vision-Language Model for Intrinsic Privacy-Preserving Behavioral Intelligence
Jan 21, 2026Adverse social interactions, such as bullying, harassment, and other illicit activities, pose significant threats to individual well-being and public safety, leaving profound impacts on physical and mental health. However, these critical events frequently occur in privacy-sensitive environments like restrooms, and changing rooms, where conventional surveillance is prohibited or severely restricted by stringent privacy regulations and ethical concerns. Here, we propose the Single-Pixel Vision-Language Model (SP-VLM), a novel framework that reimagines secure environmental monitoring. It achieves intrinsic privacy-by-design by capturing human dynamics through inherently low-dimensional single-pixel modalities and inferring complex behavioral patterns via seamless vision-language integration. Building on this framework, we demonstrate that single-pixel sensing intrinsically suppresses identity recoverability, rendering state-of-the-art face recognition systems ineffective below a critical sampling rate. We further show that SP-VLM can nonetheless extract meaningful behavioral semantics, enabling robust anomaly detection, people counting, and activity understanding from severely degraded single-pixel observations. Combining these findings, we identify a practical sampling-rate regime in which behavioral intelligence emerges while personal identity remains strongly protected. Together, these results point to a human-rights-aligned pathway for safety monitoring that can support timely intervention without normalizing intrusive surveillance in privacy-sensitive spaces.
Are LLMs Vulnerable to Preference-Undermining Attacks (PUA)? A Factorial Analysis Methodology for Diagnosing the Trade-off between Preference Alignment and Real-World Validity
Jan 10, 2026Large Language Model (LLM) training often optimizes for preference alignment, rewarding outputs that are perceived as helpful and interaction-friendly. However, this preference-oriented objective can be exploited: manipulative prompts can steer responses toward user-appeasing agreement and away from truth-oriented correction. In this work, we investigate whether aligned models are vulnerable to Preference-Undermining Attacks (PUA), a class of manipulative prompting strategies designed to exploit the model's desire to please user preferences at the expense of truthfulness. We propose a diagnostic methodology that provides a finer-grained and more directive analysis than aggregate benchmark scores, using a factorial evaluation framework to decompose prompt-induced shifts into interpretable effects of system objectives (truth- vs. preference-oriented) and PUA-style dialogue factors (directive control, personal derogation, conditional approval, reality denial) within a controlled $2 \times 2^4$ design. Surprisingly, more advanced models are sometimes more susceptible to manipulative prompts. Beyond the dominant reality-denial factor, we observe model-specific sign reversals and interactions with PUA-style factors, suggesting tailored defenses rather than uniform robustness. These findings offer a novel, reproducible factorial evaluation methodology that provides finer-grained diagnostics for post-training processes like RLHF, enabling better trade-offs in the product iteration of LLMs by offering a more nuanced understanding of preference alignment risks and the impact of manipulative prompts.
Theoretical Foundations of Scaling Law in Familial Models
Dec 29, 2025Neural scaling laws have become foundational for optimizing large language model (LLM) training, yet they typically assume a single dense model output. This limitation effectively overlooks "Familial models, a transformative paradigm essential for realizing ubiquitous intelligence across heterogeneous device-edge-cloud hierarchies. Transcending static architectures, familial models integrate early exits with relay-style inference to spawn G deployable sub-models from a single shared backbone. In this work, we theoretically and empirically extend the scaling law to capture this "one-run, many-models" paradigm by introducing Granularity (G) as a fundamental scaling variable alongside model size (N) and training tokens (D). To rigorously quantify this relationship, we propose a unified functional form L(N, D, G) and parameterize it using large-scale empirical runs. Specifically, we employ a rigorous IsoFLOP experimental design to strictly isolate architectural impact from computational scale. Across fixed budgets, we systematically sweep model sizes (N) and granularities (G) while dynamically adjusting tokens (D). This approach effectively decouples the marginal cost of granularity from the benefits of scale, ensuring high-fidelity parameterization of our unified scaling law. Our results reveal that the granularity penalty follows a multiplicative power law with an extremely small exponent. Theoretically, this bridges fixed-compute training with dynamic architectures. Practically, it validates the "train once, deploy many" paradigm, demonstrating that deployment flexibility is achievable without compromising the compute-optimality of dense baselines.
AI Flow: Perspectives, Scenarios, and Approaches
Jun 14, 2025Pioneered by the foundational information theory by Claude Shannon and the visionary framework of machine intelligence by Alan Turing, the convergent evolution of information and communication technologies (IT/CT) has created an unbroken wave of connectivity and computation. This synergy has sparked a technological revolution, now reaching its peak with large artificial intelligence (AI) models that are reshaping industries and redefining human-machine collaboration. However, the realization of ubiquitous intelligence faces considerable challenges due to substantial resource consumption in large models and high communication bandwidth demands. To address these challenges, AI Flow has been introduced as a multidisciplinary framework that integrates cutting-edge IT and CT advancements, with a particular emphasis on the following three key points. First, device-edge-cloud framework serves as the foundation, which integrates end devices, edge servers, and cloud clusters to optimize scalability and efficiency for low-latency model inference. Second, we introduce the concept of familial models, which refers to a series of different-sized models with aligned hidden features, enabling effective collaboration and the flexibility to adapt to varying resource constraints and dynamic scenarios. Third, connectivity- and interaction-based intelligence emergence is a novel paradigm of AI Flow. By leveraging communication networks to enhance connectivity, the collaboration among AI models across heterogeneous nodes achieves emergent intelligence that surpasses the capability of any single model. The innovations of AI Flow provide enhanced intelligence, timely responsiveness, and ubiquitous accessibility to AI services, paving the way for the tighter fusion of AI techniques and communication systems.
Physics in Next-token Prediction
Nov 01, 2024
We discovered the underlying physics in Next-token Prediction (NTP). We identified the law of information conservation within NTP and proposed the First Law of Information Capacity (IC-1), demonstrating that the essence of intelligence emergence in auto-regressive models is fundamentally a process of information transfer. We also introduced Landauer's Principle into NTP, formulating the Second Law of Information Capacity (IC-2), which establishes the relationship between auto-regressive model training and energy consumption. Additionally, we presented several corollaries, which hold practical significance for production practices. Finally, we validated the compatibility and complementarity of our findings with existing theories.
SentenceVAE: Enable Next-sentence Prediction for Large Language Models with Faster Speed, Higher Accuracy and Longer Context
Aug 07, 2024Current large language models (LLMs) primarily utilize next-token prediction method for inference, which significantly impedes their processing speed. In this paper, we introduce a novel inference methodology termed next-sentence prediction, aimed at enhancing the inference efficiency of LLMs. We present Sentence Variational Autoencoder (SentenceVAE), a tiny model consisting of a Sentence Encoder and a Sentence Decoder. The Sentence Encoder can effectively condense the information within a sentence into a singular token, while the Sentence Decoder can reconstruct this compressed token back into sentence. By integrating SentenceVAE into the input and output layers of LLMs, we develop Sentence-level LLMs (SLLMs) that employ a sentence-by-sentence inference method. In addition, the SentenceVAE module of SLLMS can maintain the integrity of the original semantic content by segmenting the context into sentences, thereby improving accuracy while boosting inference speed. Moreover, compared to previous LLMs, SLLMs process fewer tokens over equivalent context length, significantly reducing memory demands for self-attention computation and facilitating the handling of longer context. Extensive experiments on Wanjuan dataset have reveal that the proposed method can accelerate inference speed by 204~365%, reduce perplexity (PPL) to 46~75% of its original metric, and decrease memory overhead by 86~91% for the equivalent context length, compared to the token-by-token method.
StreakNet-Arch: An Anti-scattering Network-based Architecture for Underwater Carrier LiDAR-Radar Imaging
Apr 14, 2024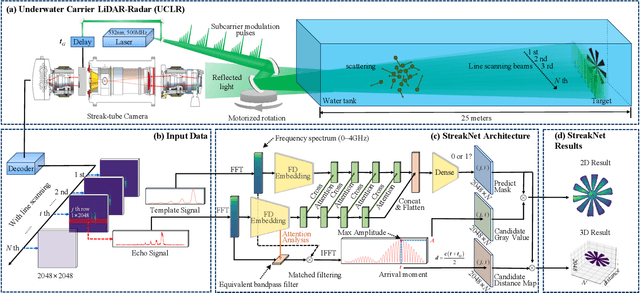
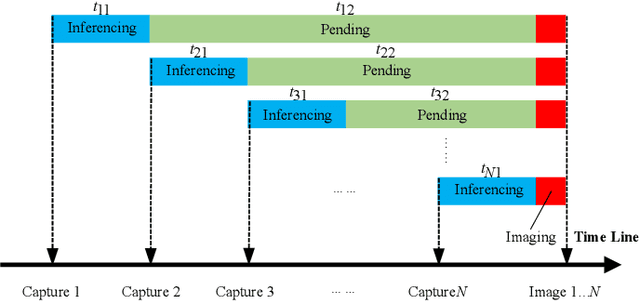
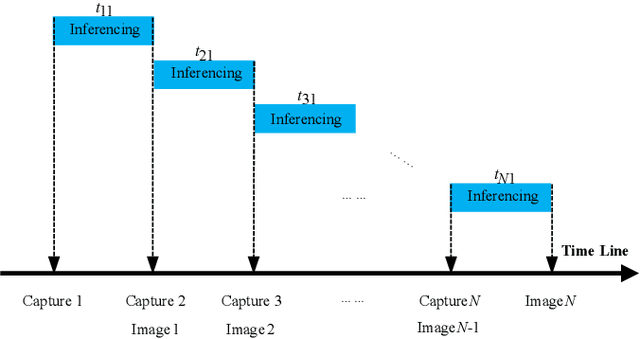
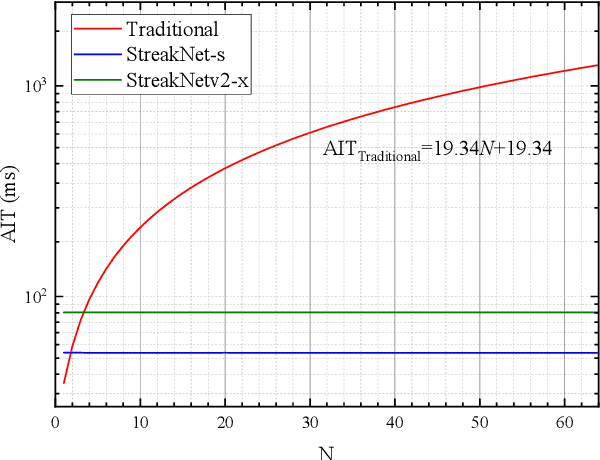
In this paper, we introduce StreakNet-Arch, a novel signal processing architecture designed for Underwater Carrier LiDAR-Radar (UCLR) imaging systems, to address the limitations in scatter suppression and real-time imaging. StreakNet-Arch formulates the signal processing as a real-time, end-to-end binary classification task, enabling real-time image acquisition. To achieve this, we leverage Self-Attention networks and propose a novel Double Branch Cross Attention (DBC-Attention) mechanism that surpasses the performance of traditional methods. Furthermore, we present a method for embedding streak-tube camera images into attention networks, effectively acting as a learned bandpass filter. To facilitate further research, we contribute a publicly available streak-tube camera image dataset. The dataset contains 2,695,168 real-world underwater 3D point cloud data. These advancements significantly improve UCLR capabilities, enhancing its performance and applicability in underwater imaging tasks. The source code and dataset can be found at https://github.com/BestAnHongjun/StreakNet .