 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced 3DMM Attribute Control via Synthetic Dataset Creation Pipeline
Dec 11, 2020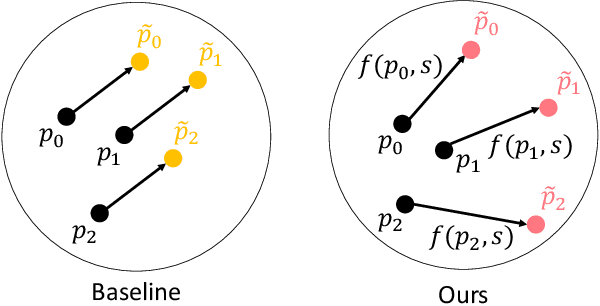

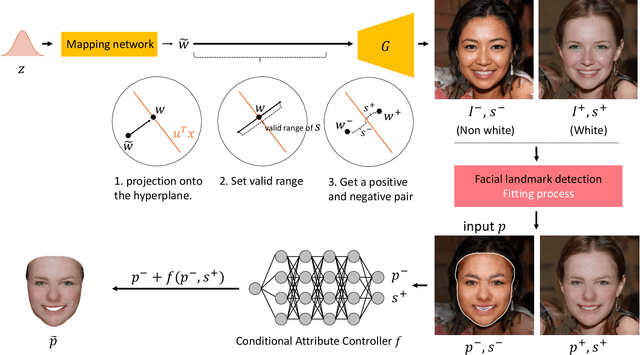

While facial attribute manipulation of 2D images via Generative Adversarial Networks (GANs) has become common in computer vision and graphics due to its many practical uses, research on 3D attribute manipulation is relatively undeveloped. Existing 3D attribute manipulation methods are limited because the same semantic changes are applied to every 3D face. The key challenge for developing better 3D attribute control methods is the lack of paired training data in which one attribute is changed while other attributes are held fixed -- e.g., a pair of 3D faces where one is male and the other is female but all other attributes, such as race and expression, are the same. To overcome this challenge, we design a novel pipeline for generating paired 3D faces by harnessing the power of GANs. On top of this pipeline, we then propose an enhanced non-linear 3D conditional attribute controller that increases the precision and diversity of 3D attribute control compared to existing methods. We demonstrate the validity of our dataset creation pipeline and the superior performance of our conditional attribute controller via quantitative and qualitative evaluations.
StyleUV: Diverse and High-fidelity UV Map Generative Model
Nov 25, 2020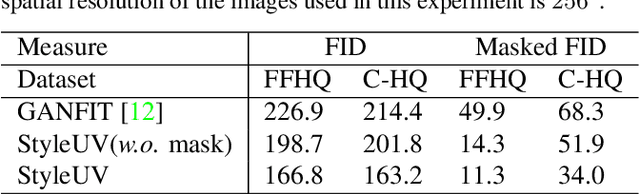
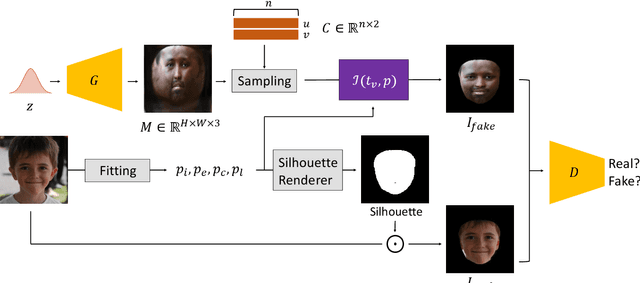


Reconstructing 3D human faces in the wild with the 3D Morphable Model (3DMM) has become popular in recent years. While most prior work focuses on estimating more robust and accurate geometry, relatively little attention has been paid to improving the quality of the texture model. Meanwhile, with the advent of Generative Adversarial Networks (GANs), there has been great progress in reconstructing realistic 2D images. Recent work demonstrates that GANs trained with abundant high-quality UV maps can produce high-fidelity textures superior to those produced by existing methods. However, acquiring such high-quality UV maps is difficult because they are expensive to acquire, requiring laborious processes to refine. In this work, we present a novel UV map generative model that learns to generate diverse and realistic synthetic UV maps without requiring high-quality UV maps for training. Our proposed framework can be trained solely with in-the-wild images (i.e., UV maps are not required) by leveraging a combination of GANs and a differentiable renderer. Both quantitative and qualitative evaluations demonstrate that our proposed texture model produces more diverse and higher fidelity textures compared to existing methods.
How Sensitive are Sensitivity-Based Explanations?
Jan 27, 2019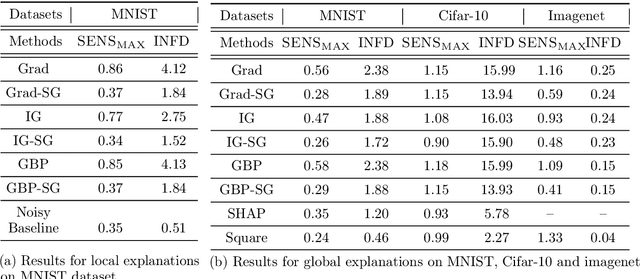
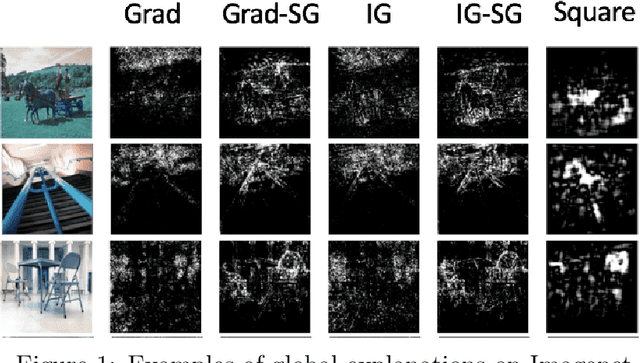
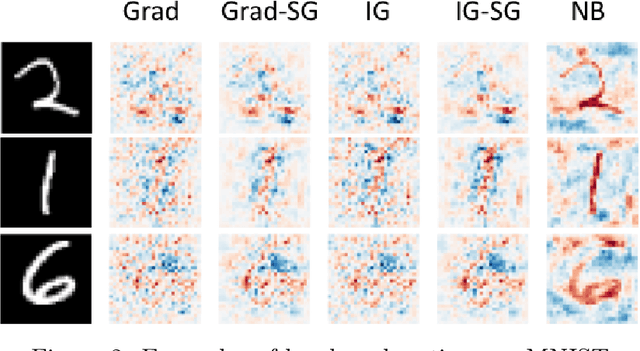
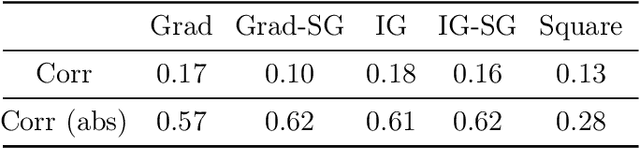
We propose a simple objective evaluation measure for explanations of a complex black-box machine learning model. While most such model explanations have largely been evaluated via qualitative measures, such as how humans might qualitatively perceive the explanations, it is vital to also consider objective measures such as the one we propose in this paper. Our evaluation measure that we naturally call sensitivity is simple: it characterizes how an explanation changes as we vary the test input, and depending on how we measure these changes, and how we vary the input, we arrive at different notions of sensitivity. We also provide a calculus for deriving sensitivity of complex explanations in terms of that for simpler explanations, which thus allows an easy computation of sensitivities for yet to be proposed explanations. One advantage of an objective evaluation measure is that we can optimize the explanation with respect to the measure: we show that (1) any given explanation can be simply modified to improve its sensitivity with just a modest deviation from the original explanation, and (2) gradient based explanations of an adversarially trained network are less sensitive. Perhaps surprisingly, our experiments show that explanations optimized to have lower sensitivity can be more faithful to the model predictions.