 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced 3DMM Attribute Control via Synthetic Dataset Creation Pipeline
Dec 11, 2020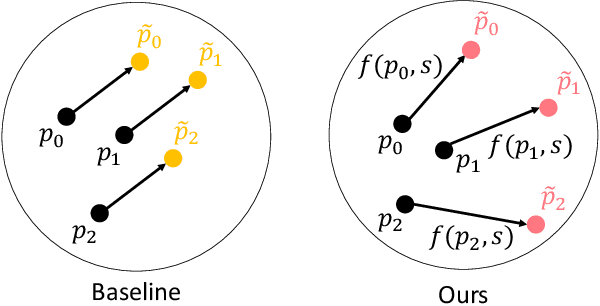

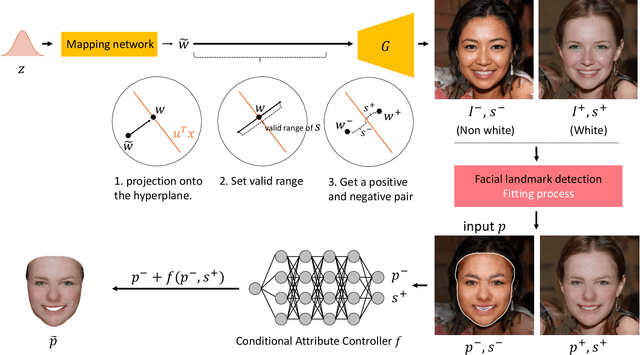

While facial attribute manipulation of 2D images via Generative Adversarial Networks (GANs) has become common in computer vision and graphics due to its many practical uses, research on 3D attribute manipulation is relatively undeveloped. Existing 3D attribute manipulation methods are limited because the same semantic changes are applied to every 3D face. The key challenge for developing better 3D attribute control methods is the lack of paired training data in which one attribute is changed while other attributes are held fixed -- e.g., a pair of 3D faces where one is male and the other is female but all other attributes, such as race and expression, are the same. To overcome this challenge, we design a novel pipeline for generating paired 3D faces by harnessing the power of GANs. On top of this pipeline, we then propose an enhanced non-linear 3D conditional attribute controller that increases the precision and diversity of 3D attribute control compared to existing methods. We demonstrate the validity of our dataset creation pipeline and the superior performance of our conditional attribute controller via quantitative and qualitative evaluations.
Self-Attention Graph Pooling
Apr 24, 2019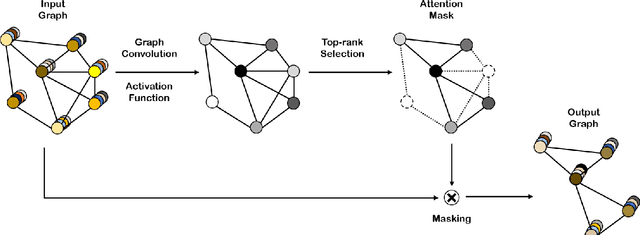



Advanced methods of applying deep learning to structured data such as graphs have been proposed in recent years. In particular, studies have focused on generalizing convolutional neural networks to graph data, which includes redefining the convolution and the downsampling (pooling) operations for graphs. The method of generalizing the convolution operation to graphs has been proven to improve performance and is widely used. However, the method of applying downsampling to graphs is still difficult to perform and has room for improvement. In this paper, we propose a graph pooling method based on self-attention. Self-attention using graph convolution allows our pooling method to consider both node features and graph topology. To ensure a fair comparison, the same training procedures and model architectures were used for the existing pooling methods and our method. The experimental results demonstrate that our method achieves superior graph classification performance on the benchmark datasets using a reasonable number of parameters.
Typeface Completion with Generative Adversarial Networks
Dec 13, 2018
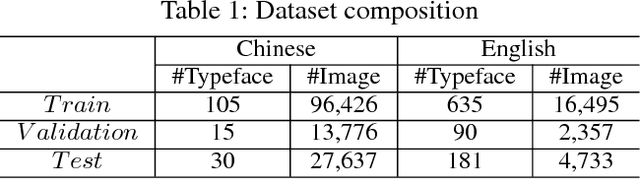
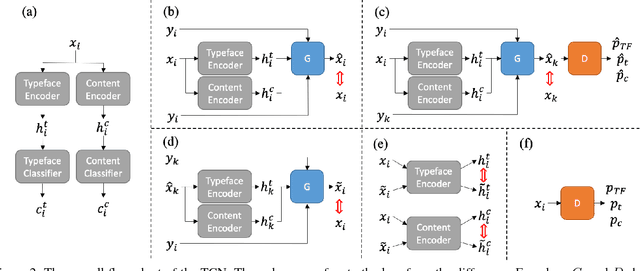
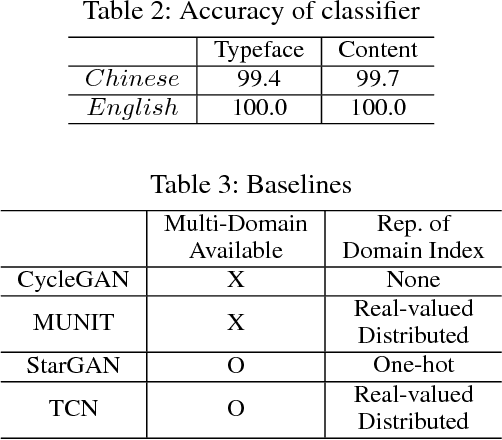
The mood of a text and the intention of the writer can be reflected in the typeface. However, in designing a typeface, it is difficult to keep the style of various characters consistent, especially for languages with lots of morphological variations such as Chinese. In this paper, we propose a Typeface Completion Network (TCN) which takes one character as an input, and automatically completes the entire set of characters in the same style as the input characters. Unlike existing models proposed for image-to-image translation, TCN embeds a character image into two separate vectors representing typeface and content. Combined with a reconstruction loss from the latent space, and with other various losses, TCN overcomes the inherent difficulty in designing a typeface. Also, compared to previous image-to-image translation models, TCN generates high quality character images of the same typeface with a much smaller number of model parameters. We validate our proposed model on the Chinese and English character datasets, which is paired data, and the CelebA dataset, which is unpaired data. In these datasets, TCN outperforms recently proposed state-of-the-art models for image-to-image translation. The source code of our model is available at https://github.com/yongqyu/TCN.