 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuess the Instruction! Flipped Learning Makes Language Models Stronger Zero-Shot Learners
Paper and Code

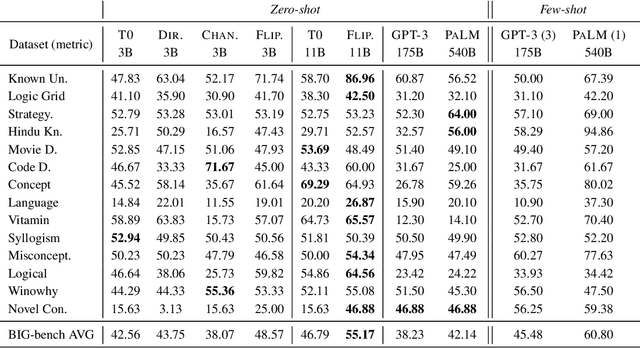


Meta-training, which fine-tunes the language model (LM) on various downstream tasks by maximizing the likelihood of the target label given the task instruction and input instance, has improved the zero-shot task generalization performance. However, meta-trained LMs still struggle to generalize to challenging tasks containing novel labels unseen during meta-training. In this paper, we propose Flipped Learning, an alternative method of meta-training which trains the LM to generate the task instruction given the input instance and label. During inference, the LM trained with Flipped Learning, referred to as Flipped, selects the label option that is most likely to generate the task instruction. On 14 tasks of the BIG-bench benchmark, the 11B-sized Flipped outperforms zero-shot T0-11B and even a 16 times larger 3-shot GPT-3 (175B) on average by 8.4% and 9.7% points, respectively. Flipped gives particularly large improvements on unseen labels, outperforming T0-11B by up to +20% average F1 score. This indicates that the strong task generalization of Flipped comes from improved generalization to novel labels. We release our code at https://github.com/seonghyeonye/Flipped-Learning.