 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKPQA: A Metric for Generative Question Answering Using Word Weights
Paper and Code

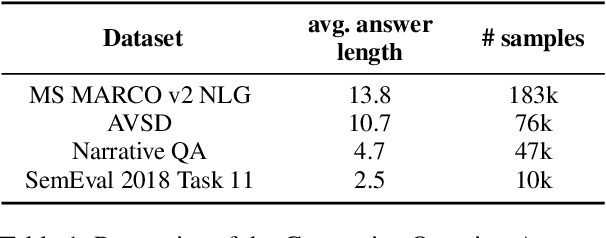
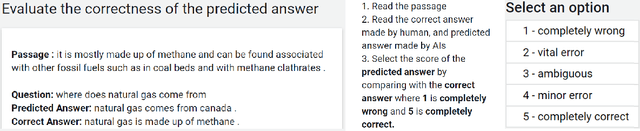

For the automatic evaluation of Generative Question Answering (genQA) systems, it is essential to assess the correctness of the generated answers. However, n-gram similarity metrics, which are widely used to compare generated texts and references, are prone to misjudge fact-based assessments. Moreover, there is a lack of benchmark datasets to measure the quality of metrics in terms of the correctness. To study a better metric for genQA, we collect high-quality human judgments of correctness on two standard genQA datasets. Using our human-evaluation datasets, we show that existing metrics based on n-gram similarity do not correlate with human judgments. To alleviate this problem, we propose a new metric for evaluating the correctness of genQA. Specifically, the new metric assigns different weights on each token via keyphrase prediction, thereby judging whether a predicted answer sentence captures the key meaning of the human judge's ground-truth. Our proposed metric shows a significantly higher correlation with human judgment than widely used existing metrics.