 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvocodo: Generative Adversarial Network for Artifact-free Vocoder
Paper and Code
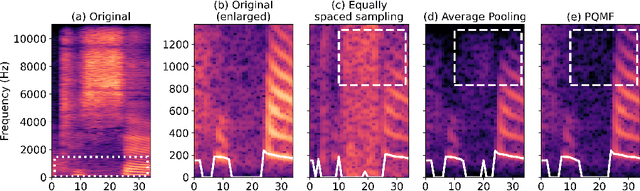
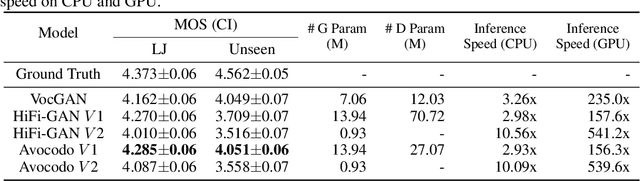
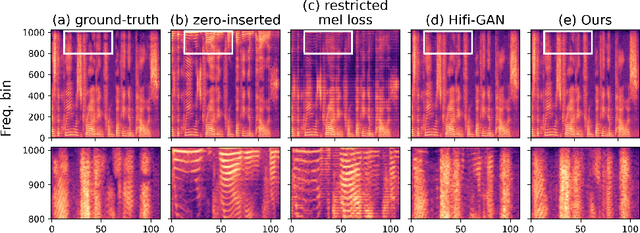
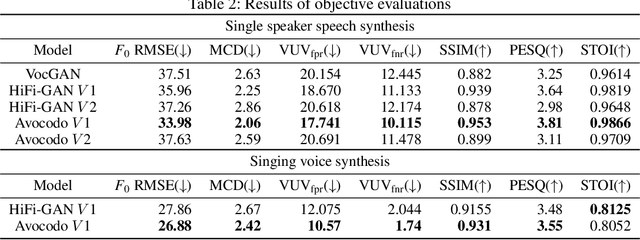
Neural vocoders based on the generative adversarial neural network (GAN) have been widely used due to their fast inference speed and lightweight networks while generating high-quality speech waveforms. Since the perceptually important speech components are primarily concentrated in the low-frequency band, most of the GAN-based neural vocoders perform multi-scale analysis that evaluates downsampled speech waveforms. This multi-scale analysis helps the generator improve speech intelligibility. However, in preliminary experiments, we observed that the multi-scale analysis which focuses on the low-frequency band causes unintended artifacts, e.g., aliasing and imaging artifacts, and these artifacts degrade the synthesized speech waveform quality. Therefore, in this paper, we investigate the relationship between these artifacts and GAN-based neural vocoders and propose a GAN-based neural vocoder, called Avocodo, that allows the synthesis of high-fidelity speech with reduced artifacts. We introduce two kinds of discriminators to evaluate waveforms in various perspectives: a collaborative multi-band discriminator and a sub-band discriminator. We also utilize a pseudo quadrature mirror filter bank to obtain downsampled multi-band waveforms while avoiding aliasing. The experimental results show that Avocodo outperforms conventional GAN-based neural vocoders in both speech and singing voice synthesis tasks and can synthesize artifact-free speech. Especially, Avocodo is even capable to reproduce high-quality waveforms of unseen speakers.