 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUDC-VIT: A Real-World Video Dataset for Under-Display Cameras
Jan 30, 2025



Under Display Camera (UDC) is an advanced imaging system that places a digital camera lens underneath a display panel, effectively concealing the camera. However, the display panel significantly degrades captured images or videos, introducing low transmittance, blur, noise, and flare issues. Tackling such issues is challenging because of the complex degradation of UDCs, including diverse flare patterns. Despite extensive research on UDC images and their restoration models, studies on videos have yet to be significantly explored. While two UDC video datasets exist, they primarily focus on unrealistic or synthetic UDC degradation rather than real-world UDC degradation. In this paper, we propose a real-world UDC video dataset called UDC-VIT. Unlike existing datasets, only UDC-VIT exclusively includes human motions that target facial recognition. We propose a video-capturing system to simultaneously acquire non-degraded and UDC-degraded videos of the same scene. Then, we align a pair of captured videos frame by frame, using discrete Fourier transform (DFT). We compare UDC-VIT with six representative UDC still image datasets and two existing UDC video datasets. Using six deep-learning models, we compare UDC-VIT and an existing synthetic UDC video dataset. The results indicate the ineffectiveness of models trained on earlier synthetic UDC video datasets, as they do not reflect the actual characteristics of UDC-degraded videos. We also demonstrate the importance of effective UDC restoration by evaluating face recognition accuracy concerning PSNR, SSIM, and LPIPS scores. UDC-VIT enables further exploration in the UDC video restoration and offers better insights into the challenge. UDC-VIT is available at our project site.
Unidirectional Thin Adapter for Efficient Adaptation of Deep Neural Networks
Mar 23, 2022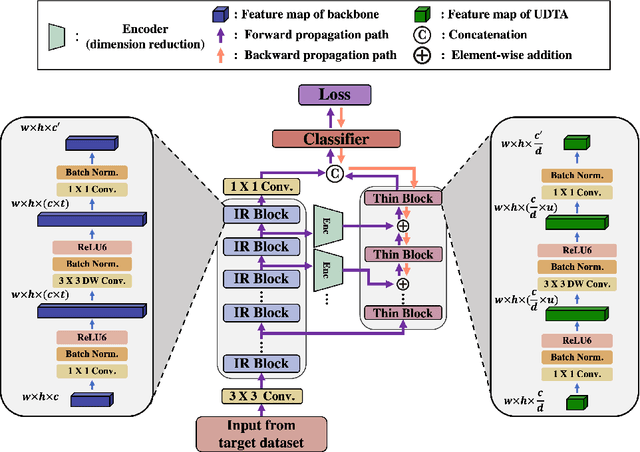
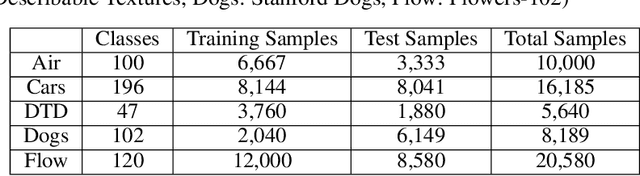

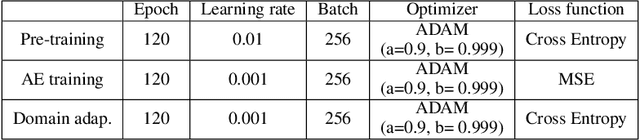
In this paper, we propose a new adapter network for adapting a pre-trained deep neural network to a target domain with minimal computation. The proposed model, unidirectional thin adapter (UDTA), helps the classifier adapt to new data by providing auxiliary features that complement the backbone network. UDTA takes outputs from multiple layers of the backbone as input features but does not transmit any feature to the backbone. As a result, UDTA can learn without computing the gradient of the backbone, which saves computation for training significantly. In addition, since UDTA learns the target task without modifying the backbone, a single backbone can adapt to multiple tasks by learning only UDTAs separately. In experiments on five fine-grained classification datasets consisting of a small number of samples, UDTA significantly reduced computation and training time required for backpropagation while showing comparable or even improved accuracy compared with conventional adapter models.