 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast DCTTS: Efficient Deep Convolutional Text-to-Speech
Apr 01, 2021
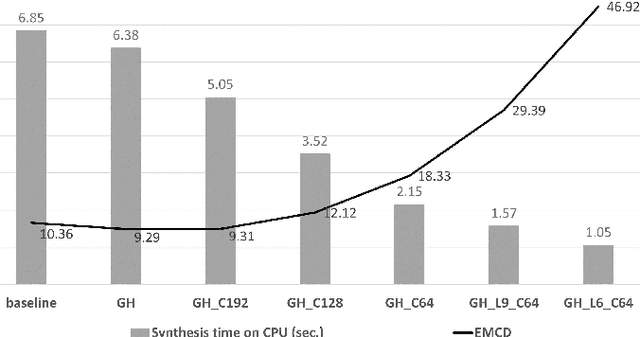


We propose an end-to-end speech synthesizer, Fast DCTTS, that synthesizes speech in real time on a single CPU thread. The proposed model is composed of a carefully-tuned lightweight network designed by applying multiple network reduction and fidelity improvement techniques. In addition, we propose a novel group highway activation that can compromise between computational efficiency and the regularization effect of the gating mechanism. As well, we introduce a new metric called Elastic mel-cepstral distortion (EMCD) to measure the fidelity of the output mel-spectrogram. In experiments, we analyze the effect of the acceleration techniques on speed and speech quality. Compared with the baseline model, the proposed model exhibits improved MOS from 2.62 to 2.74 with only 1.76% computation and 2.75% parameters. The speed on a single CPU thread was improved by 7.45 times, which is fast enough to produce mel-spectrogram in real time without GPU.