 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-focus Attention Network for Efficient Deep Reinforcement Learning
Paper and Code
Dec 13, 2017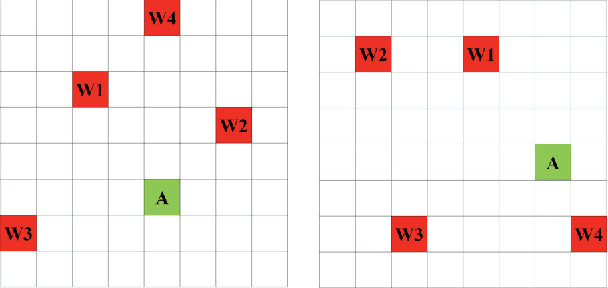

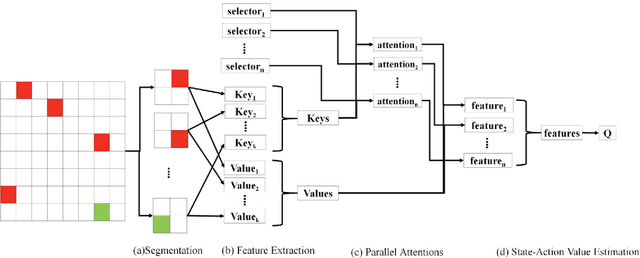
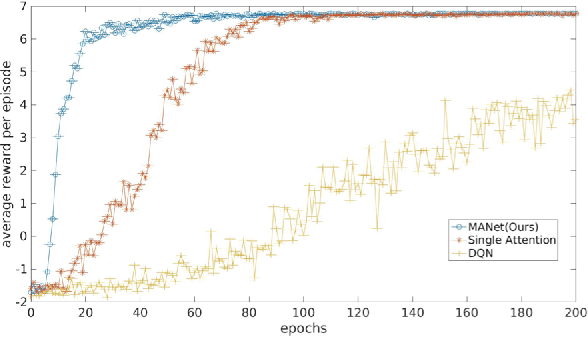
Deep reinforcement learning (DRL) has shown incredible performance in learning various tasks to the human level. However, unlike human perception, current DRL models connect the entire low-level sensory input to the state-action values rather than exploiting the relationship between and among entities that constitute the sensory input. Because of this difference, DRL needs vast amount of experience samples to learn. In this paper, we propose a Multi-focus Attention Network (MANet) which mimics human ability to spatially abstract the low-level sensory input into multiple entities and attend to them simultaneously. The proposed method first divides the low-level input into several segments which we refer to as partial states. After this segmentation, parallel attention layers attend to the partial states relevant to solving the task. Our model estimates state-action values using these attended partial states. In our experiments, MANet attains highest scores with significantly less experience samples. Additionally, the model shows higher performance compared to the Deep Q-network and the single attention model as benchmarks. Furthermore, we extend our model to attentive communication model for performing multi-agent cooperative tasks. In multi-agent cooperative task experiments, our model shows 20% faster learning than existing state-of-the-art model.