 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk-Conditioned Distributional Soft Actor-Critic for Risk-Sensitive Navigation
Paper and Code
Apr 09, 2021
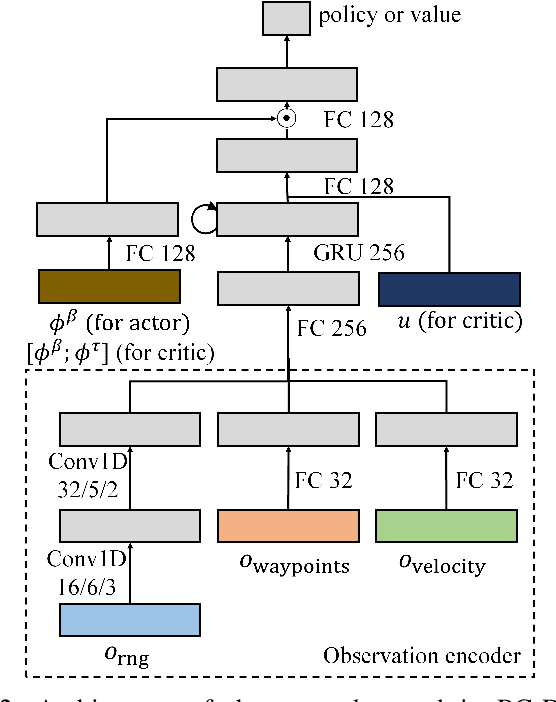


Modern navigation algorithms based on deep reinforcement learning (RL) show promising efficiency and robustness. However, most deep RL algorithms operate in a risk-neutral manner, making no special attempt to shield users from relatively rare but serious outcomes, even if such shielding might cause little loss of performance. Furthermore, such algorithms typically make no provisions to ensure safety in the presence of inaccuracies in the models on which they were trained, beyond adding a cost-of-collision and some domain randomization while training, in spite of the formidable complexity of the environments in which they operate. In this paper, we present a novel distributional RL algorithm that not only learns an uncertainty-aware policy, but can also change its risk measure without expensive fine-tuning or retraining. Our method shows superior performance and safety over baselines in partially-observed navigation tasks. We also demonstrate that agents trained using our method can adapt their policies to a wide range of risk measures at run-time.