 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Training-Free Defense Framework for Robust Learned Image Compression
Jan 22, 2024



We study the robustness of learned image compression models against adversarial attacks and present a training-free defense technique based on simple image transform functions. Recent learned image compression models are vulnerable to adversarial attacks that result in poor compression rate, low reconstruction quality, or weird artifacts. To address the limitations, we propose a simple but effective two-way compression algorithm with random input transforms, which is conveniently applicable to existing image compression models. Unlike the na\"ive approaches, our approach preserves the original rate-distortion performance of the models on clean images. Moreover, the proposed algorithm requires no additional training or modification of existing models, making it more practical. We demonstrate the effectiveness of the proposed techniques through extensive experiments under multiple compression models, evaluation metrics, and attack scenarios.
Unsupervised Pre-Training For Data-Efficient Text-to-Speech On Low Resource Languages
Mar 28, 2023Neural text-to-speech (TTS) models can synthesize natural human speech when trained on large amounts of transcribed speech. However, collecting such large-scale transcribed data is expensive. This paper proposes an unsupervised pre-training method for a sequence-to-sequence TTS model by leveraging large untranscribed speech data. With our pre-training, we can remarkably reduce the amount of paired transcribed data required to train the model for the target downstream TTS task. The main idea is to pre-train the model to reconstruct de-warped mel-spectrograms from warped ones, which may allow the model to learn proper temporal assignment relation between input and output sequences. In addition, we propose a data augmentation method that further improves the data efficiency in fine-tuning. We empirically demonstrate the effectiveness of our proposed method in low-resource language scenarios, achieving outstanding performance compared to competing methods. The code and audio samples are available at: https://github.com/cnaigithub/SpeechDewarping
Variable-Rate Deep Image Compression through Spatially-Adaptive Feature Transform
Aug 21, 2021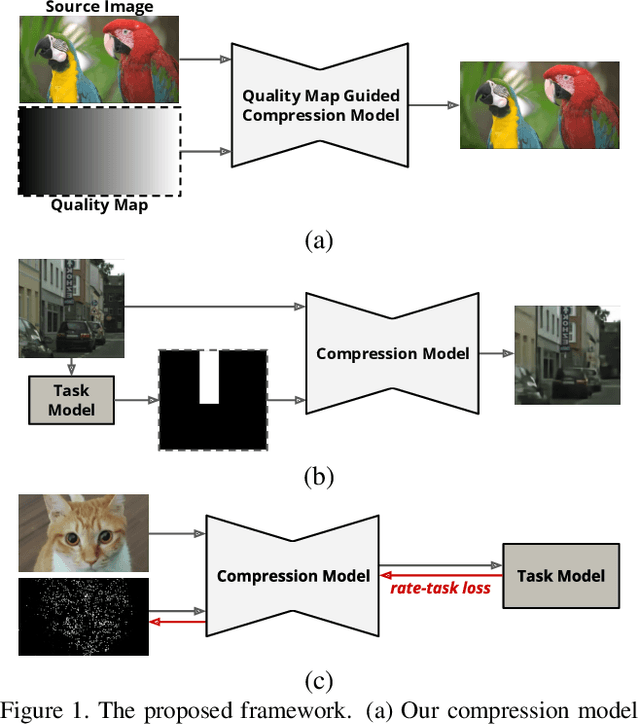


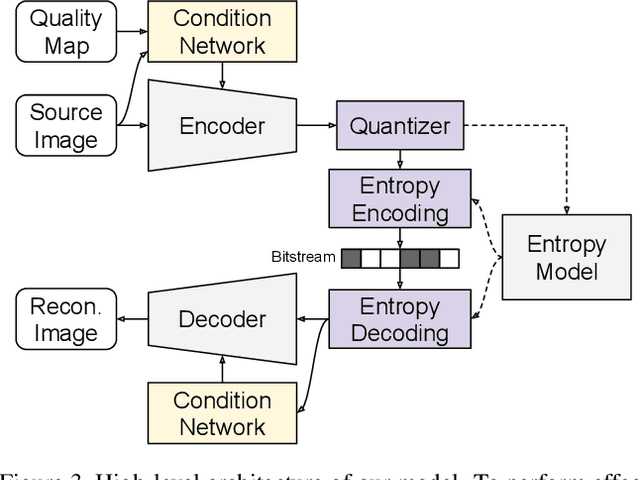
We propose a versatile deep image compression network based on Spatial Feature Transform (SFT arXiv:1804.02815), which takes a source image and a corresponding quality map as inputs and produce a compressed image with variable rates. Our model covers a wide range of compression rates using a single model, which is controlled by arbitrary pixel-wise quality maps. In addition, the proposed framework allows us to perform task-aware image compressions for various tasks, e.g., classification, by efficiently estimating optimized quality maps specific to target tasks for our encoding network. This is even possible with a pretrained network without learning separate models for individual tasks. Our algorithm achieves outstanding rate-distortion trade-off compared to the approaches based on multiple models that are optimized separately for several different target rates. At the same level of compression, the proposed approach successfully improves performance on image classification and text region quality preservation via task-aware quality map estimation without additional model training. The code is available at the project website: https://github.com/micmic123/QmapCompression