 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrioritized Replay for RL Post-training
Jan 06, 2026We introduce a problem-level prioritization framework for RL post-training of large language models. Building on insights from prioritized replay in deep RL, as well as prior observations that rollouts with intermediate success rates tend to produce stronger learning signals under methods such as GRPO, our approach selects problems according to a simple, model-driven priority score derived from empirical success statistics. In contrast to conventional curriculum strategies that emphasize easier tasks early in training, the resulting schedule naturally focuses training on problems that are neither consistently solved nor consistently failed, while deprioritizing those that contribute little gradient information. The method yields a continuously adapting and automatic prioritization process that requires no predefined difficulty tiers, auxiliary predictors, or external labels. We further introduce lightweight mechanisms for practical deployment, including heap-based prioritized sampling and periodic retesting of solved and unsolved problems to mitigate starvation and forgetting. Overall, the approach offers a principled and scalable alternative to manually designed curricula while aligning data selection directly with the dynamics of GRPO-based post-training.
Concise Reasoning via Reinforcement Learning
Apr 07, 2025Despite significant advancements in large language models (LLMs), a major drawback of reasoning models is their enormous token usage, which increases computational cost, resource requirements, and response time. In this work, we revisit the core principles of reinforcement learning (RL) and, through mathematical analysis, demonstrate that the tendency to generate lengthy responses arises inherently from RL-based optimization during training. This finding questions the prevailing assumption that longer responses inherently improve reasoning accuracy. Instead, we uncover a natural correlation between conciseness and accuracy that has been largely overlooked. Moreover, we show that introducing a secondary phase of RL post-training, using a small set of problems and limited resources, can significantly reduce a model's chain of thought while maintaining or even enhancing accuracy. Finally, we validate our conclusions through extensive experimental results.
OpenDebateEvidence: A Massive-Scale Argument Mining and Summarization Dataset
Jun 20, 2024



We introduce OpenDebateEvidence, a comprehensive dataset for argument mining and summarization sourced from the American Competitive Debate community. This dataset includes over 3.5 million documents with rich metadata, making it one of the most extensive collections of debate evidence. OpenDebateEvidence captures the complexity of arguments in high school and college debates, providing valuable resources for training and evaluation. Our extensive experiments demonstrate the efficacy of fine-tuning state-of-the-art large language models for argumentative abstractive summarization across various methods, models, and datasets. By providing this comprehensive resource, we aim to advance computational argumentation and support practical applications for debaters, educators, and researchers. OpenDebateEvidence is publicly available to support further research and innovation in computational argumentation. Access it here: https://huggingface.co/datasets/Yusuf5/OpenCaselist
A Dynamical View of the Question of Why
Feb 27, 2024


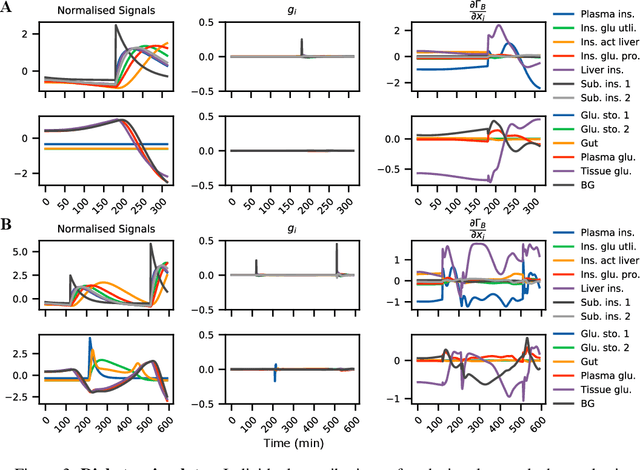
We address causal reasoning in multivariate time series data generated by stochastic processes. Existing approaches are largely restricted to static settings, ignoring the continuity and emission of variations across time. In contrast, we propose a learning paradigm that directly establishes causation between events in the course of time. We present two key lemmas to compute causal contributions and frame them as reinforcement learning problems. Our approach offers formal and computational tools for uncovering and quantifying causal relationships in diffusion processes, subsuming various important settings such as discrete-time Markov decision processes. Finally, in fairly intricate experiments and through sheer learning, our framework reveals and quantifies causal links, which otherwise seem inexplicable.
Successor Features for Efficient Multisubject Controlled Text Generation
Nov 03, 2023
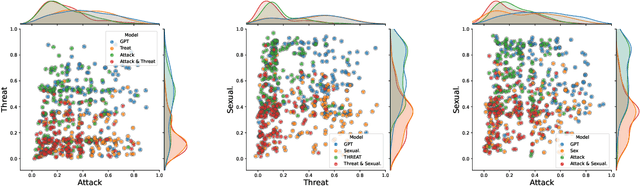

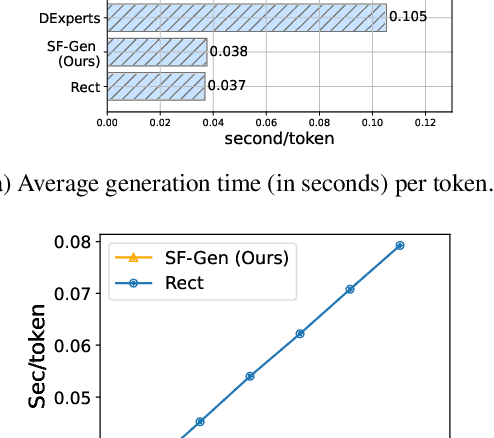
While large language models (LLMs) have achieved impressive performance in generating fluent and realistic text, controlling the generated text so that it exhibits properties such as safety, factuality, and non-toxicity remains challenging. % such as DExperts, GeDi, and rectification Existing decoding-based methods are static in terms of the dimension of control; if the target subject is changed, they require new training. Moreover, it can quickly become prohibitive to concurrently control multiple subjects. In this work, we introduce SF-GEN, which is grounded in two primary concepts: successor features (SFs) to decouple the LLM's dynamics from task-specific rewards, and language model rectification to proportionally adjust the probability of selecting a token based on the likelihood that the finished text becomes undesired. SF-GEN seamlessly integrates the two to enable dynamic steering of text generation with no need to alter the LLM's parameters. Thanks to the decoupling effect induced by successor features, our method proves to be memory-wise and computationally efficient for training as well as decoding, especially when dealing with multiple target subjects. To the best of our knowledge, our research represents the first application of successor features in text generation. In addition to its computational efficiency, the resultant language produced by our method is comparable to the SOTA (and outperforms baselines) in both control measures as well as language quality, which we demonstrate through a series of experiments in various controllable text generation tasks.
Systematic Rectification of Language Models via Dead-end Analysis
Feb 27, 2023



With adversarial or otherwise normal prompts, existing large language models (LLM) can be pushed to generate toxic discourses. One way to reduce the risk of LLMs generating undesired discourses is to alter the training of the LLM. This can be very restrictive due to demanding computation requirements. Other methods rely on rule-based or prompt-based token elimination, which are limited as they dismiss future tokens and the overall meaning of the complete discourse. Here, we center detoxification on the probability that the finished discourse is ultimately considered toxic. That is, at each point, we advise against token selections proportional to how likely a finished text from this point will be toxic. To this end, we formally extend the dead-end theory from the recent reinforcement learning (RL) literature to also cover uncertain outcomes. Our approach, called rectification, utilizes a separate but significantly smaller model for detoxification, which can be applied to diverse LLMs as long as they share the same vocabulary. Importantly, our method does not require access to the internal representations of the LLM, but only the token probability distribution at each decoding step. This is crucial as many LLMs today are hosted in servers and only accessible through APIs. When applied to various LLMs, including GPT-3, our approach significantly improves the generated discourse compared to the base LLMs and other techniques in terms of both the overall language and detoxification performance.
* The Eleventh International Conference on Learning Representations, ICLR'23
Semi-Markov Offline Reinforcement Learning for Healthcare
Mar 21, 2022
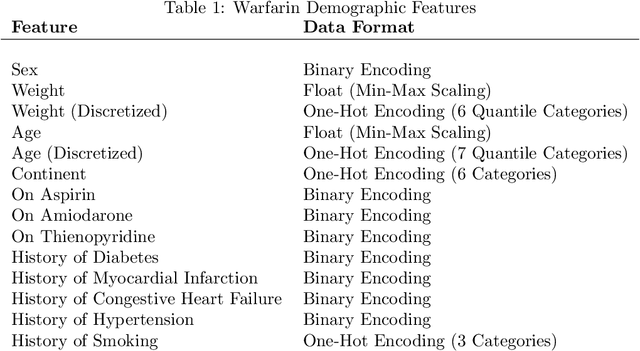
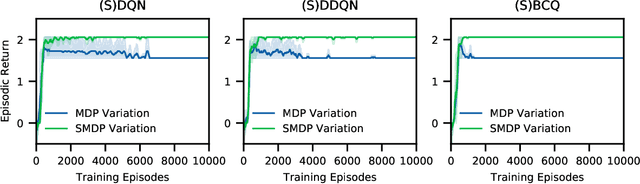
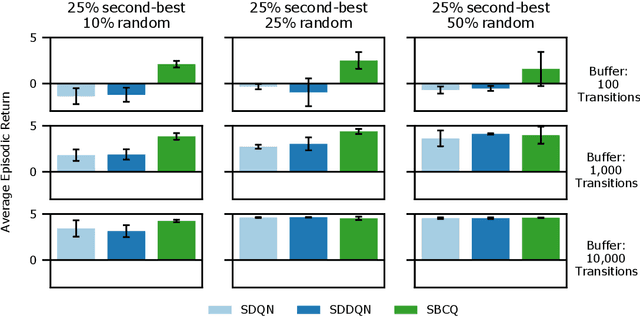
Reinforcement learning (RL) tasks are typically framed as Markov Decision Processes (MDPs), assuming that decisions are made at fixed time intervals. However, many applications of great importance, including healthcare, do not satisfy this assumption, yet they are commonly modelled as MDPs after an artificial reshaping of the data. In addition, most healthcare (and similar) problems are offline by nature, allowing for only retrospective studies. To address both challenges, we begin by discussing the Semi-MDP (SMDP) framework, which formally handles actions of variable timings. We next present a formal way to apply SMDP modifications to nearly any given value-based offline RL method. We use this theory to introduce three SMDP-based offline RL algorithms, namely, SDQN, SDDQN, and SBCQ. We then experimentally demonstrate that only these SMDP-based algorithms learn the optimal policy in variable-time environments, whereas their MDP counterparts do not. Finally, we apply our new algorithms to a real-world offline dataset pertaining to warfarin dosing for stroke prevention and demonstrate similar results.
Orchestrated Value Mapping for Reinforcement Learning
Mar 16, 2022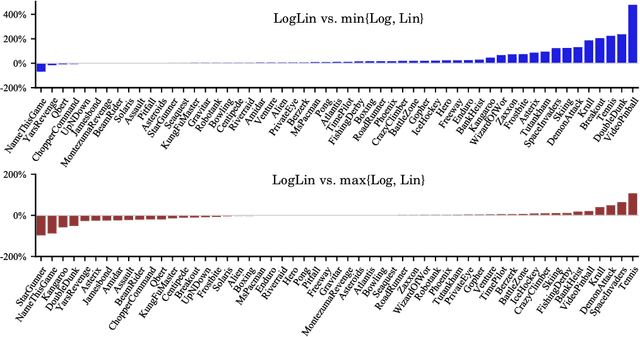



We present a general convergent class of reinforcement learning algorithms that is founded on two distinct principles: (1) mapping value estimates to a different space using arbitrary functions from a broad class, and (2) linearly decomposing the reward signal into multiple channels. The first principle enables incorporating specific properties into the value estimator that can enhance learning. The second principle, on the other hand, allows for the value function to be represented as a composition of multiple utility functions. This can be leveraged for various purposes, e.g. dealing with highly varying reward scales, incorporating a priori knowledge about the sources of reward, and ensemble learning. Combining the two principles yields a general blueprint for instantiating convergent algorithms by orchestrating diverse mapping functions over multiple reward channels. This blueprint generalizes and subsumes algorithms such as Q-Learning, Log Q-Learning, and Q-Decomposition. In addition, our convergence proof for this general class relaxes certain required assumptions in some of these algorithms. Based on our theory, we discuss several interesting configurations as special cases. Finally, to illustrate the potential of the design space that our theory opens up, we instantiate a particular algorithm and evaluate its performance on the Atari suite.
Medical Dead-ends and Learning to Identify High-risk States and Treatments
Oct 08, 2021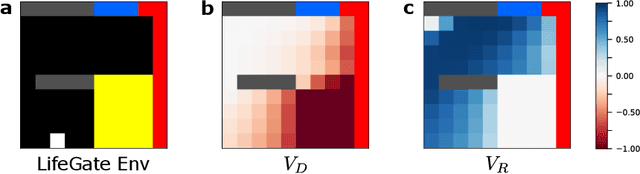
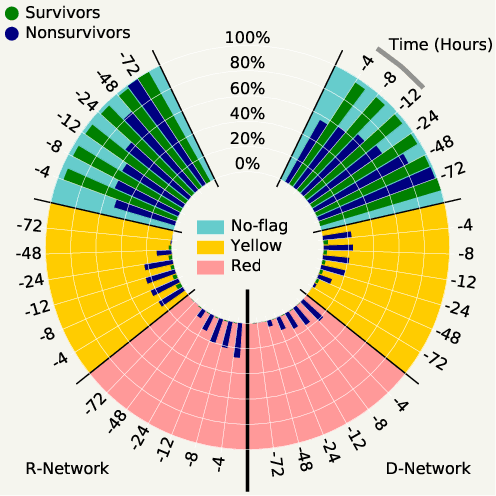
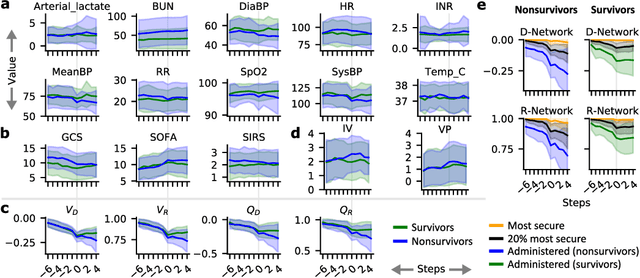
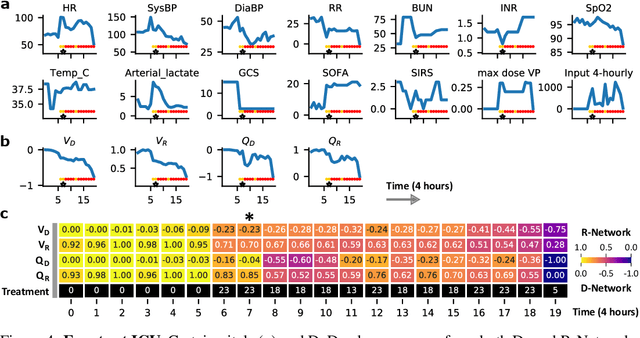
Machine learning has successfully framed many sequential decision making problems as either supervised prediction, or optimal decision-making policy identification via reinforcement learning. In data-constrained offline settings, both approaches may fail as they assume fully optimal behavior or rely on exploring alternatives that may not exist. We introduce an inherently different approach that identifies possible ``dead-ends'' of a state space. We focus on the condition of patients in the intensive care unit, where a ``medical dead-end'' indicates that a patient will expire, regardless of all potential future treatment sequences. We postulate ``treatment security'' as avoiding treatments with probability proportional to their chance of leading to dead-ends, present a formal proof, and frame discovery as an RL problem. We then train three independent deep neural models for automated state construction, dead-end discovery and confirmation. Our empirical results discover that dead-ends exist in real clinical data among septic patients, and further reveal gaps between secure treatments and those that were administered.
Shortest-Path Constrained Reinforcement Learning for Sparse Reward Tasks
Jul 13, 2021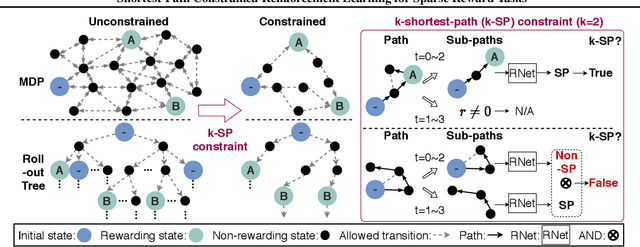
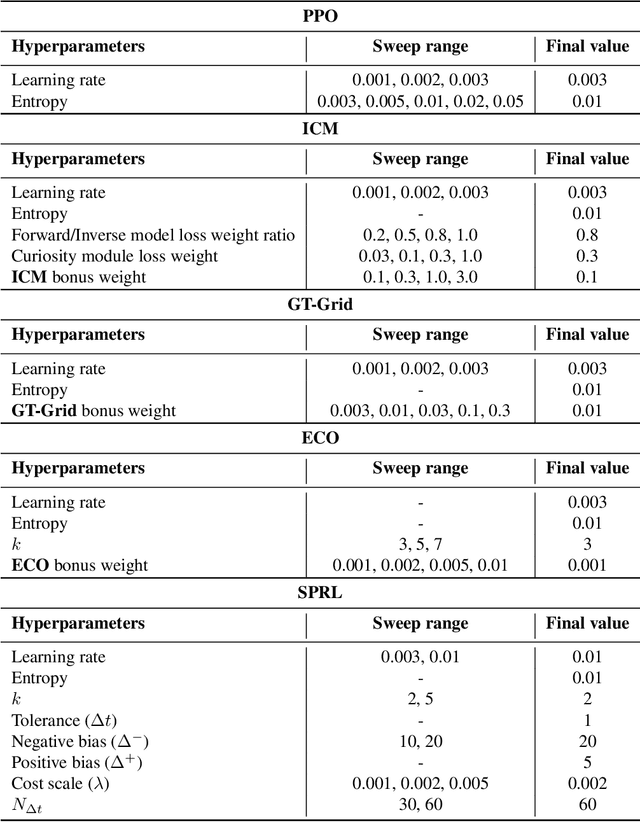

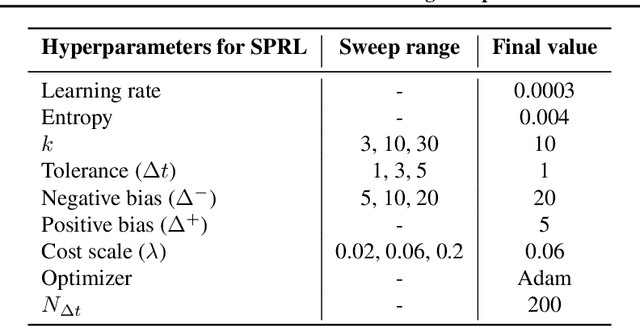
We propose the k-Shortest-Path (k-SP) constraint: a novel constraint on the agent's trajectory that improves the sample efficiency in sparse-reward MDPs. We show that any optimal policy necessarily satisfies the k-SP constraint. Notably, the k-SP constraint prevents the policy from exploring state-action pairs along the non-k-SP trajectories (e.g., going back and forth). However, in practice, excluding state-action pairs may hinder the convergence of RL algorithms. To overcome this, we propose a novel cost function that penalizes the policy violating SP constraint, instead of completely excluding it. Our numerical experiment in a tabular RL setting demonstrates that the SP constraint can significantly reduce the trajectory space of policy. As a result, our constraint enables more sample efficient learning by suppressing redundant exploration and exploitation. Our experiments on MiniGrid, DeepMind Lab, Atari, and Fetch show that the proposed method significantly improves proximal policy optimization (PPO) and outperforms existing novelty-seeking exploration methods including count-based exploration even in continuous control tasks, indicating that it improves the sample efficiency by preventing the agent from taking redundant actions.