 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuccessor Features for Efficient Multisubject Controlled Text Generation
Paper and Code

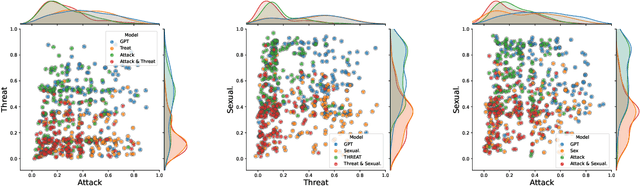

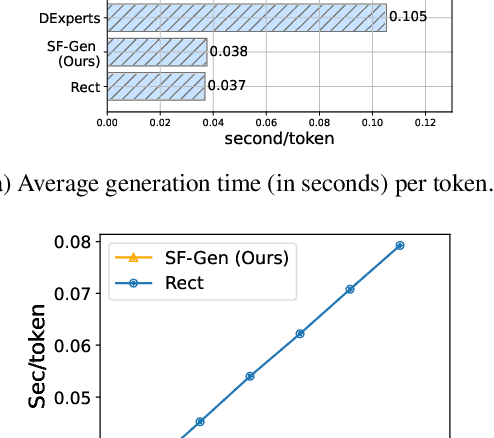
While large language models (LLMs) have achieved impressive performance in generating fluent and realistic text, controlling the generated text so that it exhibits properties such as safety, factuality, and non-toxicity remains challenging. % such as DExperts, GeDi, and rectification Existing decoding-based methods are static in terms of the dimension of control; if the target subject is changed, they require new training. Moreover, it can quickly become prohibitive to concurrently control multiple subjects. In this work, we introduce SF-GEN, which is grounded in two primary concepts: successor features (SFs) to decouple the LLM's dynamics from task-specific rewards, and language model rectification to proportionally adjust the probability of selecting a token based on the likelihood that the finished text becomes undesired. SF-GEN seamlessly integrates the two to enable dynamic steering of text generation with no need to alter the LLM's parameters. Thanks to the decoupling effect induced by successor features, our method proves to be memory-wise and computationally efficient for training as well as decoding, especially when dealing with multiple target subjects. To the best of our knowledge, our research represents the first application of successor features in text generation. In addition to its computational efficiency, the resultant language produced by our method is comparable to the SOTA (and outperforms baselines) in both control measures as well as language quality, which we demonstrate through a series of experiments in various controllable text generation tasks.