 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenDebateEvidence: A Massive-Scale Argument Mining and Summarization Dataset
Jun 20, 2024



We introduce OpenDebateEvidence, a comprehensive dataset for argument mining and summarization sourced from the American Competitive Debate community. This dataset includes over 3.5 million documents with rich metadata, making it one of the most extensive collections of debate evidence. OpenDebateEvidence captures the complexity of arguments in high school and college debates, providing valuable resources for training and evaluation. Our extensive experiments demonstrate the efficacy of fine-tuning state-of-the-art large language models for argumentative abstractive summarization across various methods, models, and datasets. By providing this comprehensive resource, we aim to advance computational argumentation and support practical applications for debaters, educators, and researchers. OpenDebateEvidence is publicly available to support further research and innovation in computational argumentation. Access it here: https://huggingface.co/datasets/Yusuf5/OpenCaselist
LLM as an Art Director : Using LLMs to improve Text-to-Media Generators
Nov 07, 2023Recent advancements in text-to-image generation have revolutionized numerous fields, including art and cinema, by automating the generation of high-quality, context-aware images and video. However, the utility of these technologies is often limited by the inadequacy of text prompts in guiding the generator to produce artistically coherent and subject-relevant images. In this paper, We describe the techniques that can be used to make Large Language Models (LLMs) act as Art Directors that enhance image and video generation. We describe our unified system for this called "LaDi". We explore how LaDi integrates multiple techniques for augmenting the capabilities of text-to-image generators (T2Is) and text-to-video generators (T2Vs), with a focus on constrained decoding, intelligent prompting, fine-tuning, and retrieval. LaDi and these techniques are being used today in apps and platforms developed by Plai Labs.
DebateKG: Automatic Policy Debate Case Creation with Semantic Knowledge Graphs
Jul 09, 2023Recent work within the Argument Mining community has shown the applicability of Natural Language Processing systems for solving problems found within competitive debate. One of the most important tasks within competitive debate is for debaters to create high quality debate cases. We show that effective debate cases can be constructed using constrained shortest path traversals on Argumentative Semantic Knowledge Graphs. We study this potential in the context of a type of American Competitive Debate, called Policy Debate, which already has a large scale dataset targeting it called DebateSum. We significantly improve upon DebateSum by introducing 53180 new examples, as well as further useful metadata for every example, to the dataset. We leverage the txtai semantic search and knowledge graph toolchain to produce and contribute 9 semantic knowledge graphs built on this dataset. We create a unique method for evaluating which knowledge graphs are better in the context of producing policy debate cases. A demo which automatically generates debate cases, along with all other code and the Knowledge Graphs, are open-sourced and made available to the public here: https://github.com/Hellisotherpeople/DebateKG
Most Language Models can be Poets too: An AI Writing Assistant and Constrained Text Generation Studio
Jun 28, 2023Despite rapid advancement in the field of Constrained Natural Language Generation, little time has been spent on exploring the potential of language models which have had their vocabularies lexically, semantically, and/or phonetically constrained. We find that most language models generate compelling text even under significant constraints. We present a simple and universally applicable technique for modifying the output of a language model by compositionally applying filter functions to the language models vocabulary before a unit of text is generated. This approach is plug-and-play and requires no modification to the model. To showcase the value of this technique, we present an easy to use AI writing assistant called Constrained Text Generation Studio (CTGS). CTGS allows users to generate or choose from text with any combination of a wide variety of constraints, such as banning a particular letter, forcing the generated words to have a certain number of syllables, and/or forcing the words to be partial anagrams of another word. We introduce a novel dataset of prose that omits the letter e. We show that our method results in strictly superior performance compared to fine-tuning alone on this dataset. We also present a Huggingface space web-app presenting this technique called Gadsby. The code is available to the public here: https://github.com/Hellisotherpeople/Constrained-Text-Generation-Studio
CX DB8: A queryable extractive summarizer and semantic search engine
Dec 07, 2020


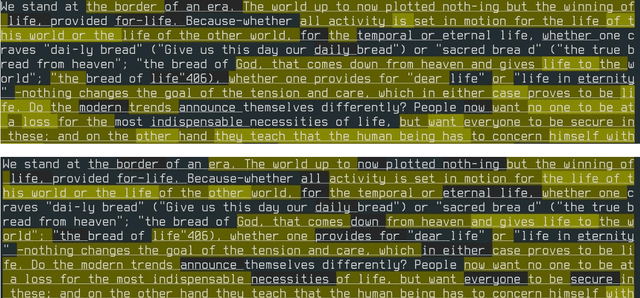
Competitive Debate's increasingly technical nature has left competitors looking for tools to accelerate evidence production. We find that the unique type of extractive summarization performed by competitive debaters - summarization with a bias towards a particular target meaning - can be performed using the latest innovations in unsupervised pre-trained text vectorization models. We introduce CX_DB8, a queryable word-level extractive summarizer and evidence creation framework, which allows for rapid, biasable summarization of arbitarily sized texts. CX_DB8s usage of the embedding framework Flair means that as the underlying models improve, CX_DB8 will also improve. We observe that CX_DB8 also functions as a semantic search engine, and has application as a supplement to traditional "find" functionality in programs and webpages. CX_DB8 is currently used by competitive debaters and is made available to the public at https://github.com/Hellisotherpeople/CX_DB8
DebateSum: A large-scale argument mining and summarization dataset
Nov 14, 2020

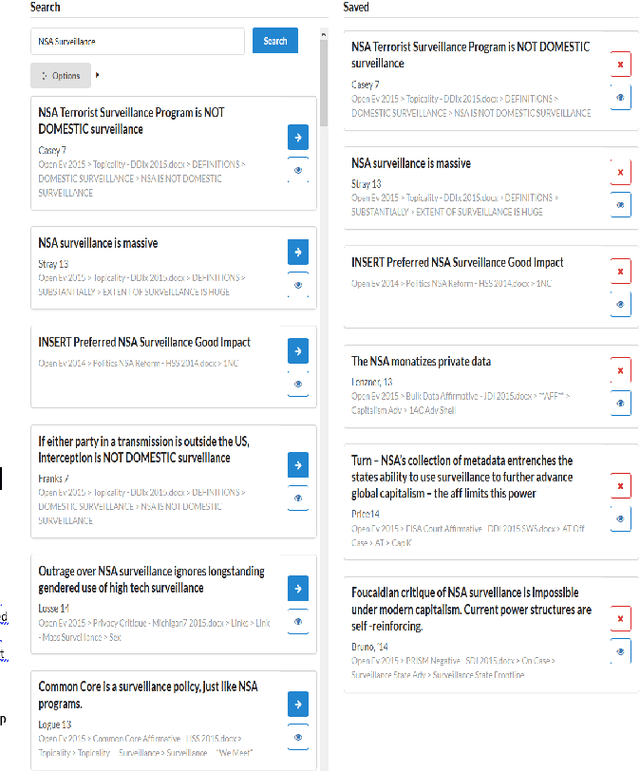
Prior work in Argument Mining frequently alludes to its potential applications in automatic debating systems. Despite this focus, almost no datasets or models exist which apply natural language processing techniques to problems found within competitive formal debate. To remedy this, we present the DebateSum dataset. DebateSum consists of 187,386 unique pieces of evidence with corresponding argument and extractive summaries. DebateSum was made using data compiled by competitors within the National Speech and Debate Association over a 7-year period. We train several transformer summarization models to benchmark summarization performance on DebateSum. We also introduce a set of fasttext word-vectors trained on DebateSum called debate2vec. Finally, we present a search engine for this dataset which is utilized extensively by members of the National Speech and Debate Association today. The DebateSum search engine is available to the public here: http://www.debate.cards