 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeasibility-Guided Fair Adaptive Offline Reinforcement Learning for Medicaid Care Management
Sep 11, 2025We introduce Feasibility-Guided Fair Adaptive Reinforcement Learning (FG-FARL), an offline RL procedure that calibrates per-group safety thresholds to reduce harm while equalizing a chosen fairness target (coverage or harm) across protected subgroups. Using de-identified longitudinal trajectories from a Medicaid population health management program, we evaluate FG-FARL against behavior cloning (BC) and HACO (Hybrid Adaptive Conformal Offline RL; a global conformal safety baseline). We report off-policy value estimates with bootstrap 95% confidence intervals and subgroup disparity analyses with p-values. FG-FARL achieves comparable value to baselines while improving fairness metrics, demonstrating a practical path to safer and more equitable decision support.
OpenDebateEvidence: A Massive-Scale Argument Mining and Summarization Dataset
Jun 20, 2024



We introduce OpenDebateEvidence, a comprehensive dataset for argument mining and summarization sourced from the American Competitive Debate community. This dataset includes over 3.5 million documents with rich metadata, making it one of the most extensive collections of debate evidence. OpenDebateEvidence captures the complexity of arguments in high school and college debates, providing valuable resources for training and evaluation. Our extensive experiments demonstrate the efficacy of fine-tuning state-of-the-art large language models for argumentative abstractive summarization across various methods, models, and datasets. By providing this comprehensive resource, we aim to advance computational argumentation and support practical applications for debaters, educators, and researchers. OpenDebateEvidence is publicly available to support further research and innovation in computational argumentation. Access it here: https://huggingface.co/datasets/Yusuf5/OpenCaselist
Most Language Models can be Poets too: An AI Writing Assistant and Constrained Text Generation Studio
Jun 28, 2023Despite rapid advancement in the field of Constrained Natural Language Generation, little time has been spent on exploring the potential of language models which have had their vocabularies lexically, semantically, and/or phonetically constrained. We find that most language models generate compelling text even under significant constraints. We present a simple and universally applicable technique for modifying the output of a language model by compositionally applying filter functions to the language models vocabulary before a unit of text is generated. This approach is plug-and-play and requires no modification to the model. To showcase the value of this technique, we present an easy to use AI writing assistant called Constrained Text Generation Studio (CTGS). CTGS allows users to generate or choose from text with any combination of a wide variety of constraints, such as banning a particular letter, forcing the generated words to have a certain number of syllables, and/or forcing the words to be partial anagrams of another word. We introduce a novel dataset of prose that omits the letter e. We show that our method results in strictly superior performance compared to fine-tuning alone on this dataset. We also present a Huggingface space web-app presenting this technique called Gadsby. The code is available to the public here: https://github.com/Hellisotherpeople/Constrained-Text-Generation-Studio
NGBoost: Natural Gradient Boosting for Probabilistic Prediction
Oct 09, 2019



We present Natural Gradient Boosting (NGBoost), an algorithm which brings probabilistic prediction capability to gradient boosting in a generic way. Predictive uncertainty estimation is crucial in many applications such as healthcare and weather forecasting. Probabilistic prediction, which is the approach where the model outputs a full probability distribution over the entire outcome space, is a natural way to quantify those uncertainties. Gradient Boosting Machines have been widely successful in prediction tasks on structured input data, but a simple boosting solution for probabilistic prediction of real valued outputs is yet to be made. NGBoost is a gradient boosting approach which uses the \emph{Natural Gradient} to address technical challenges that makes generic probabilistic prediction hard with existing gradient boosting methods. Our approach is modular with respect to the choice of base learner, probability distribution, and scoring rule. We show empirically on several regression datasets that NGBoost provides competitive predictive performance of both uncertainty estimates and traditional metrics.
Forecasting Internally Displaced Population Migration Patterns in Syria and Yemen
Jun 22, 2018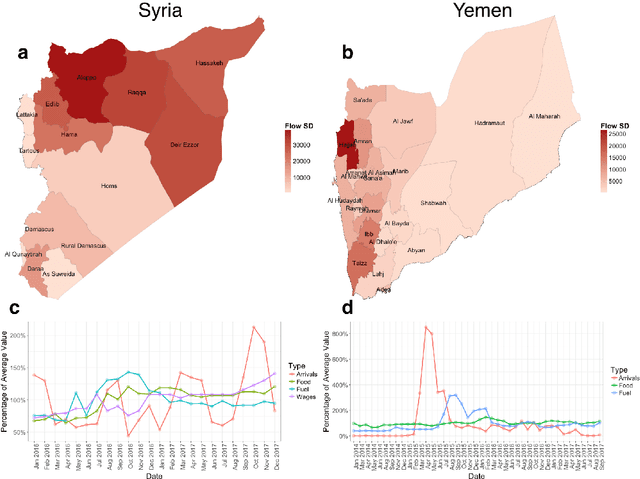
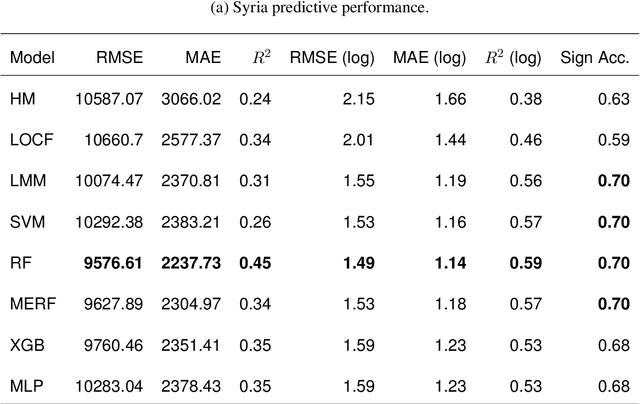
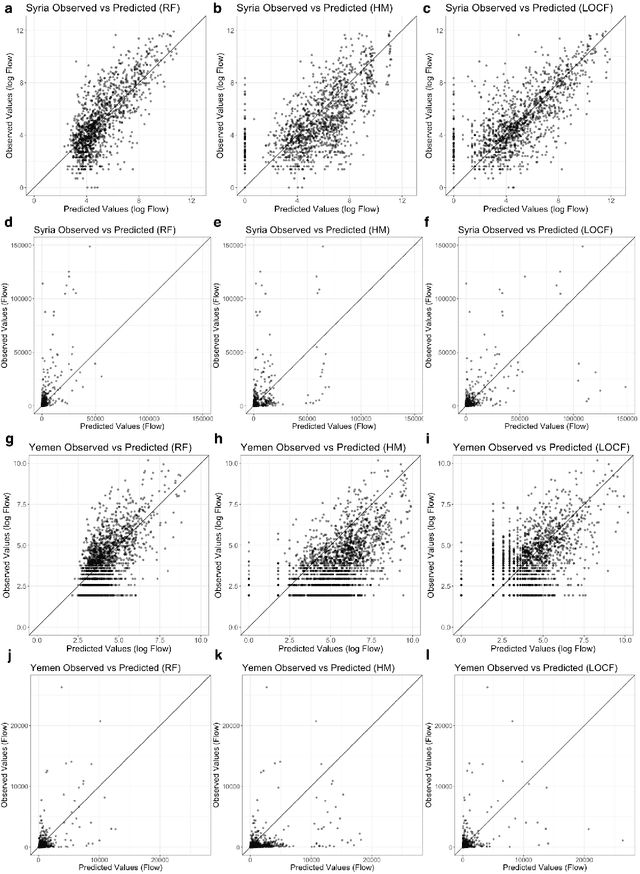

Armed conflict has led to an unprecedented number of internally displaced persons (IDPs) - individuals who are forced out of their homes but remain within their country. IDPs often urgently require shelter, food, and healthcare, yet prediction of when large fluxes of IDPs will cross into an area remains a major challenge for aid delivery organizations. Accurate forecasting of IDP migration would empower humanitarian aid groups to more effectively allocate resources during conflicts. We show that monthly flow of IDPs from province to province in both Syria and Yemen can be accurately forecasted one month in advance, using publicly available data. We model monthly IDP flow using data on food price, fuel price, wage, geospatial, and news data. We find that machine learning approaches can more accurately forecast migration trends than baseline persistence models. Our findings thus potentially enable proactive aid allocation for IDPs in anticipation of forecasted arrivals.