 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving reproducibility by controlling random seed stability in machine learning based estimation via bagging
Apr 20, 2026Predictions from machine learning algorithms can vary across random seeds, inducing instability in downstream debiased machine learning estimators. We formalize random seed stability via a concentration condition and prove that subbagging guarantees stability for any bounded-outcome regression algorithm. We introduce a new cross-fitting procedure, adaptive cross-bagging, which simultaneously eliminates seed dependence from both nuisance estimation and sample splitting in debiased machine learning. Numerical experiments confirm that the method achieves the targeted level of stability whereas alternatives do not. Our method incurs a small computational penalty relative to standard practice whereas alternative methods incur large penalties.
Highly Adaptive Principal Component Regression
Feb 11, 2026The Highly Adaptive Lasso (HAL) is a nonparametric regression method that achieves almost dimension-free convergence rates under minimal smoothness assumptions, but its implementation can be computationally prohibitive in high dimensions due to the large basis matrix it requires. The Highly Adaptive Ridge (HAR) has been proposed as a scalable alternative. Building on both procedures, we introduce the Principal Component based Highly Adaptive Lasso (PCHAL) and Principal Component based Highly Adaptive Ridge (PCHAR). These estimators constitute an outcome-blind dimension reduction which offer substantial gains in computational efficiency and match the empirical performances of HAL and HAR. We also uncover a striking spectral link between the leading principal components of the HAL/HAR Gram operator and a discrete sinusoidal basis, revealing an explicit Fourier-type structure underlying the PC truncation.
Targeted Deep Architectures: A TMLE-Based Framework for Robust Causal Inference in Neural Networks
Jul 16, 2025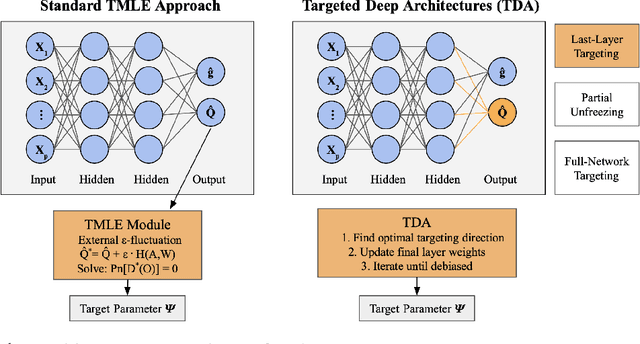
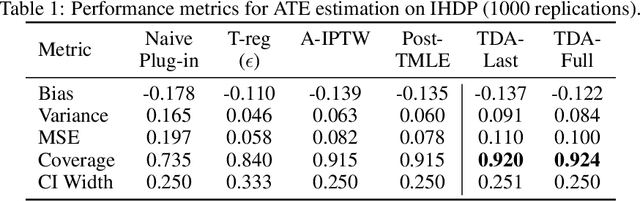
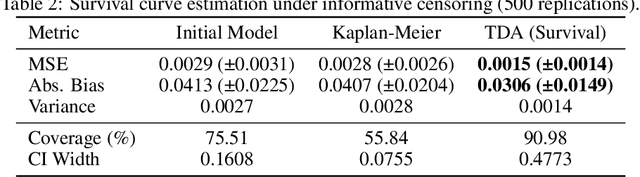
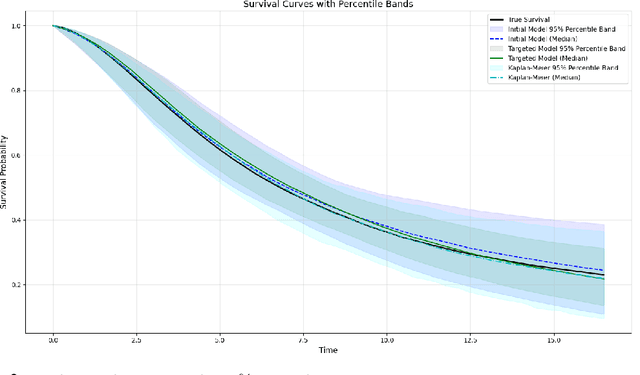
Modern deep neural networks are powerful predictive tools yet often lack valid inference for causal parameters, such as treatment effects or entire survival curves. While frameworks like Double Machine Learning (DML) and Targeted Maximum Likelihood Estimation (TMLE) can debias machine-learning fits, existing neural implementations either rely on "targeted losses" that do not guarantee solving the efficient influence function equation or computationally expensive post-hoc "fluctuations" for multi-parameter settings. We propose Targeted Deep Architectures (TDA), a new framework that embeds TMLE directly into the network's parameter space with no restrictions on the backbone architecture. Specifically, TDA partitions model parameters - freezing all but a small "targeting" subset - and iteratively updates them along a targeting gradient, derived from projecting the influence functions onto the span of the gradients of the loss with respect to weights. This procedure yields plug-in estimates that remove first-order bias and produce asymptotically valid confidence intervals. Crucially, TDA easily extends to multi-dimensional causal estimands (e.g., entire survival curves) by merging separate targeting gradients into a single universal targeting update. Theoretically, TDA inherits classical TMLE properties, including double robustness and semiparametric efficiency. Empirically, on the benchmark IHDP dataset (average treatment effects) and simulated survival data with informative censoring, TDA reduces bias and improves coverage relative to both standard neural-network estimators and prior post-hoc approaches. In doing so, TDA establishes a direct, scalable pathway toward rigorous causal inference within modern deep architectures for complex multi-parameter targets.
RieszBoost: Gradient Boosting for Riesz Regression
Jan 08, 2025Answering causal questions often involves estimating linear functionals of conditional expectations, such as the average treatment effect or the effect of a longitudinal modified treatment policy. By the Riesz representation theorem, these functionals can be expressed as the expected product of the conditional expectation of the outcome and the Riesz representer, a key component in doubly robust estimation methods. Traditionally, the Riesz representer is estimated indirectly by deriving its explicit analytical form, estimating its components, and substituting these estimates into the known form (e.g., the inverse propensity score). However, deriving or estimating the analytical form can be challenging, and substitution methods are often sensitive to practical positivity violations, leading to higher variance and wider confidence intervals. In this paper, we propose a novel gradient boosting algorithm to directly estimate the Riesz representer without requiring its explicit analytical form. This method is particularly suited for tabular data, offering a flexible, nonparametric, and computationally efficient alternative to existing methods for Riesz regression. Through simulation studies, we demonstrate that our algorithm performs on par with or better than indirect estimation techniques across a range of functionals, providing a user-friendly and robust solution for estimating causal quantities.
Highly Adaptive Ridge
Oct 03, 2024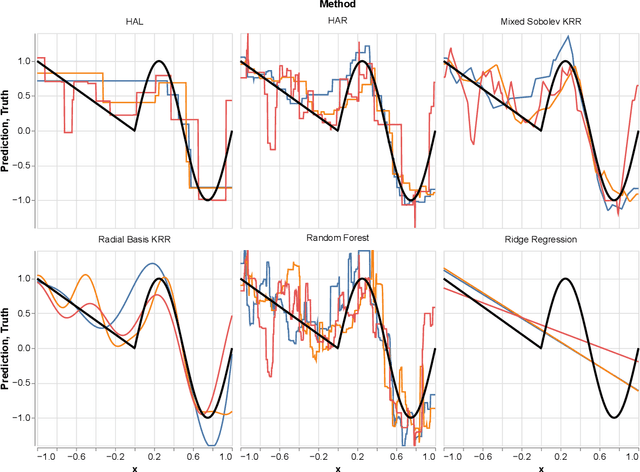
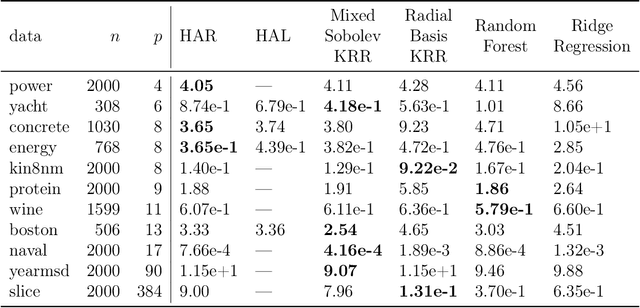
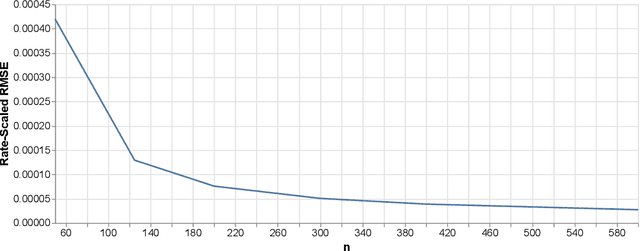
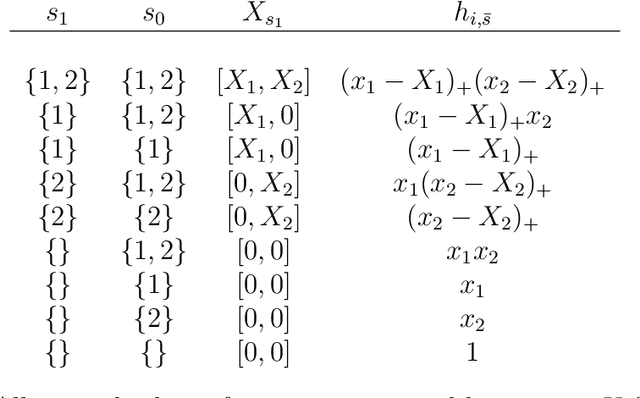
In this paper we propose the Highly Adaptive Ridge (HAR): a regression method that achieves a $n^{-1/3}$ dimension-free L2 convergence rate in the class of right-continuous functions with square-integrable sectional derivatives. This is a large nonparametric function class that is particularly appropriate for tabular data. HAR is exactly kernel ridge regression with a specific data-adaptive kernel based on a saturated zero-order tensor-product spline basis expansion. We use simulation and real data to confirm our theory. We demonstrate empirical performance better than state-of-the-art algorithms for small datasets in particular.
The Selectively Adaptive Lasso
May 22, 2022
Machine learning regression methods allow estimation of functions without unrealistic parametric assumptions. Although they can perform exceptionally in prediction error, most lack theoretical convergence rates necessary for semi-parametric efficient estimation (e.g. TMLE, AIPW) of parameters like average treatment effects. The Highly Adaptive Lasso (HAL) is the only regression method proven to converge quickly enough for a meaningfully large class of functions, independent of the dimensionality of the predictors. Unfortunately, HAL is not computationally scalable. In this paper we build upon the theory of HAL to construct the Selectively Adaptive Lasso (SAL), a new algorithm which retains HAL's dimension-free, nonparametric convergence rate but which also scales computationally to massive datasets. To accomplish this, we prove some general theoretical results pertaining to empirical loss minimization in nested Donsker classes. Our resulting algorithm is a form of gradient tree boosting with an adaptive learning rate, which makes it fast and trivial to implement with off-the-shelf software. Finally, we show that our algorithm retains the performance of standard gradient boosting on a diverse group of real-world datasets. SAL makes semi-parametric efficient estimators practically possible and theoretically justifiable in many big data settings.
Multivariate Probabilistic Regression with Natural Gradient Boosting
Jun 07, 2021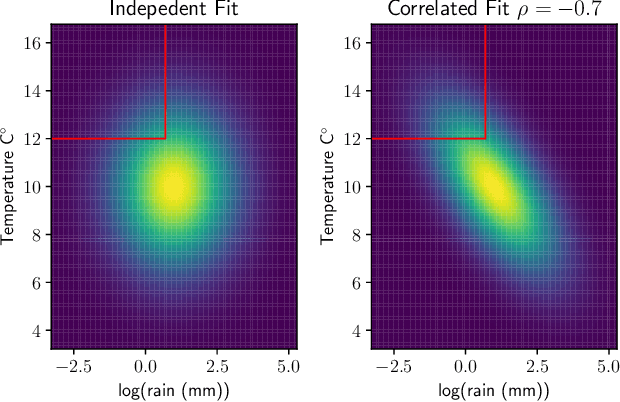
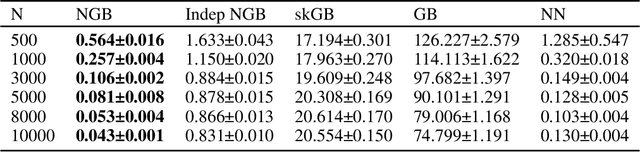
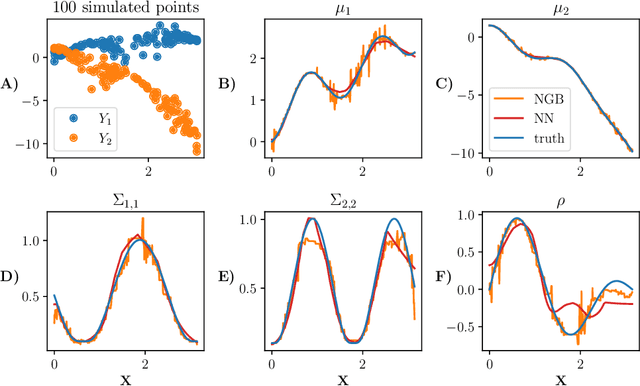

Many single-target regression problems require estimates of uncertainty along with the point predictions. Probabilistic regression algorithms are well-suited for these tasks. However, the options are much more limited when the prediction target is multivariate and a joint measure of uncertainty is required. For example, in predicting a 2D velocity vector a joint uncertainty would quantify the probability of any vector in the plane, which would be more expressive than two separate uncertainties on the x- and y- components. To enable joint probabilistic regression, we propose a Natural Gradient Boosting (NGBoost) approach based on nonparametrically modeling the conditional parameters of the multivariate predictive distribution. Our method is robust, works out-of-the-box without extensive tuning, is modular with respect to the assumed target distribution, and performs competitively in comparison to existing approaches. We demonstrate these claims in simulation and with a case study predicting two-dimensional oceanographic velocity data. An implementation of our method is available at https://github.com/stanfordmlgroup/ngboost.
Bayesian prognostic covariate adjustment
Dec 24, 2020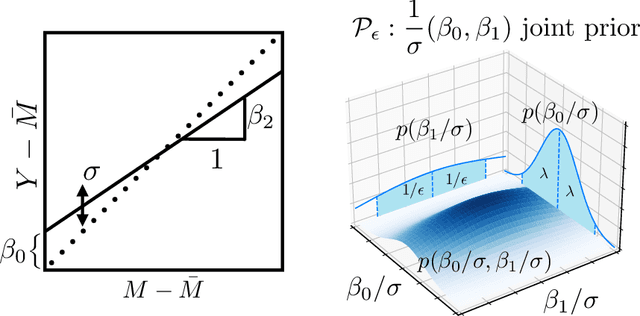
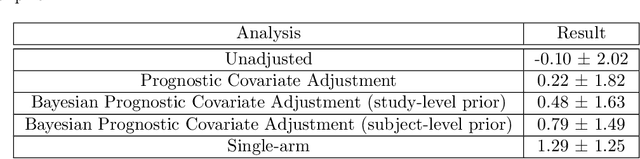
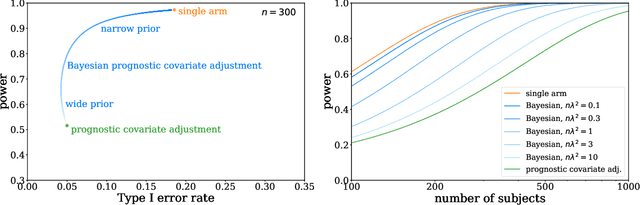
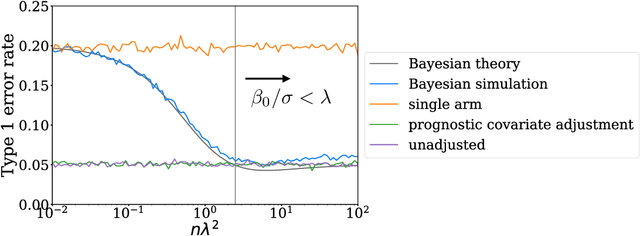
Historical data about disease outcomes can be integrated into the analysis of clinical trials in many ways. We build on existing literature that uses prognostic scores from a predictive model to increase the efficiency of treatment effect estimates via covariate adjustment. Here we go further, utilizing a Bayesian framework that combines prognostic covariate adjustment with an empirical prior distribution learned from the predictive performances of the prognostic model on past trials. The Bayesian approach interpolates between prognostic covariate adjustment with strict type I error control when the prior is diffuse, and a single-arm trial when the prior is sharply peaked. This method is shown theoretically to offer a substantial increase in statistical power, while limiting the type I error rate under reasonable conditions. We demonstrate the utility of our method in simulations and with an analysis of a past Alzheimer's disease clinical trial.
Increasing the efficiency of randomized trial estimates via linear adjustment for a prognostic score
Dec 17, 2020
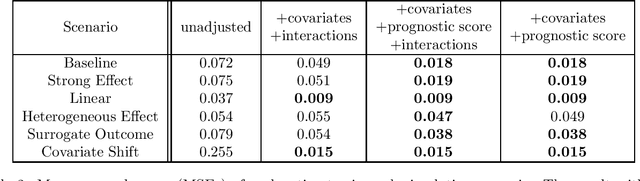
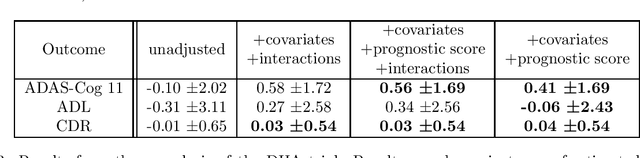

Estimating causal effects from randomized experiments is central to clinical research. Reducing the statistical uncertainty in these analyses is an important objective for statisticians. Registries, prior trials, and health records constitute a growing compendium of historical data on patients under standard-of-care conditions that may be exploitable to this end. However, most methods for historical borrowing achieve reductions in variance by sacrificing strict type-I error rate control. Here, we propose a use of historical data that exploits linear covariate adjustment to improve the efficiency of trial analyses without incurring bias. Specifically, we train a prognostic model on the historical data, then estimate the treatment effect using a linear regression while adjusting for the trial subjects' predicted outcomes (their prognostic scores). We prove that, under certain conditions, this prognostic covariate adjustment procedure attains the minimum variance possible among a large class of estimators. When those conditions are not met, prognostic covariate adjustment is still more efficient than raw covariate adjustment and the gain in efficiency is proportional to a measure of the predictive accuracy of the prognostic model. We demonstrate the approach using simulations and a reanalysis of an Alzheimer's Disease clinical trial and observe meaningful reductions in mean-squared error and the estimated variance. Lastly, we provide a simplified formula for asymptotic variance that enables power and sample size calculations that account for the gains from the prognostic model for clinical trial design.
Performance metrics for intervention-triggering prediction models do not reflect an expected reduction in outcomes from using the model
Jun 02, 2020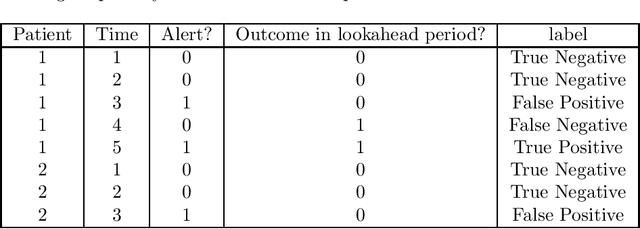


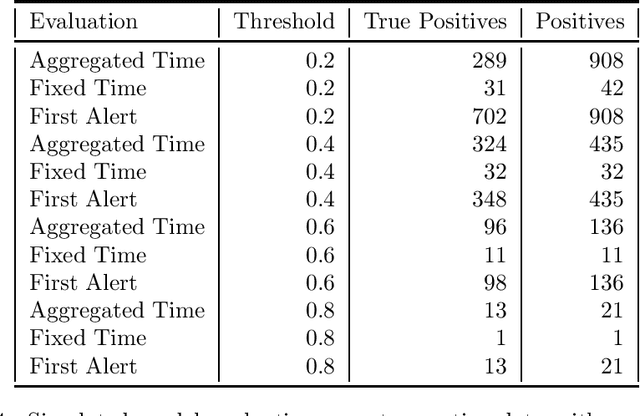
Clinical researchers often select among and evaluate risk prediction models using standard machine learning metrics based on confusion matrices. However, if these models are used to allocate interventions to patients, standard metrics calculated from retrospective data are only related to model utility (in terms of reductions in outcomes) under certain assumptions. When predictions are delivered repeatedly throughout time (e.g. in a patient encounter), the relationship between standard metrics and utility is further complicated. Several kinds of evaluations have been used in the literature, but it has not been clear what the target of estimation is in each evaluation. We synthesize these approaches, determine what is being estimated in each of them, and discuss under what assumptions those estimates are valid. We demonstrate our insights using simulated data as well as real data used in the design of an early warning system. Our theoretical and empirical results show that evaluations without interventional data either do not estimate meaningful quantities, require strong assumptions, or are limited to estimating best-case scenario bounds.