 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Centric Interpretability for LLM-based Multi-Agent Reinforcement Learning
Feb 05, 2026Large language models (LLMs) are increasingly trained in complex Reinforcement Learning, multi-agent environments, making it difficult to understand how behavior changes over training. Sparse Autoencoders (SAEs) have recently shown to be useful for data-centric interpretability. In this work, we analyze large-scale reinforcement learning training runs from the sophisticated environment of Full-Press Diplomacy by applying pretrained SAEs, alongside LLM-summarizer methods. We introduce Meta-Autointerp, a method for grouping SAE features into interpretable hypotheses about training dynamics. We discover fine-grained behaviors including role-playing patterns, degenerate outputs, language switching, alongside high-level strategic behaviors and environment-specific bugs. Through automated evaluation, we validate that 90% of discovered SAE Meta-Features are significant, and find a surprising reward hacking behavior. However, through two user studies, we find that even subjectively interesting and seemingly helpful SAE features may be worse than useless to humans, along with most LLM generated hypotheses. However, a subset of SAE-derived hypotheses are predictively useful for downstream tasks. We further provide validation by augmenting an untrained agent's system prompt, improving the score by +14.2%. Overall, we show that SAEs and LLM-summarizer provide complementary views into agent behavior, and together our framework forms a practical starting point for future data-centric interpretability work on ensuring trustworthy LLM behavior throughout training.
Democratizing Diplomacy: A Harness for Evaluating Any Large Language Model on Full-Press Diplomacy
Aug 10, 2025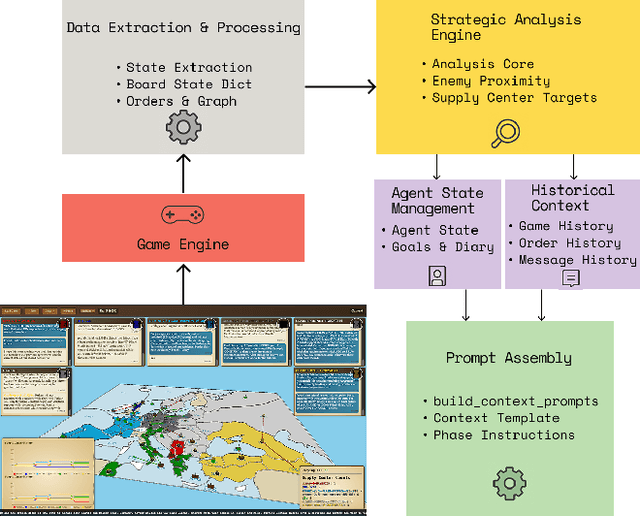



We present the first evaluation harness that enables any out-of-the-box, local, Large Language Models (LLMs) to play full-press Diplomacy without fine-tuning or specialized training. Previous work required frontier LLMs, or fine-tuning, due to the high complexity and information density of Diplomacy's game state. Combined with the high variance of matches, these factors made Diplomacy prohibitive for study. In this work, we used data-driven iteration to optimize a textual game state representation such that a 24B model can reliably complete matches without any fine tuning. We develop tooling to facilitate hypothesis testing and statistical analysis, and we present case studies on persuasion, aggressive playstyles, and performance across a range of models. We conduct a variety of experiments across many popular LLMs, finding the larger models perform the best, but the smaller models still play adequately. We also introduce Critical State Analysis: an experimental protocol for rapidly iterating and analyzing key moments in a game at depth. Our harness democratizes the evaluation of strategic reasoning in LLMs by eliminating the need for fine-tuning, and it provides insights into how these capabilities emerge naturally from widely used LLMs. Our code is available in the supplement and will be open sourced.
LLM as an Art Director : Using LLMs to improve Text-to-Media Generators
Nov 07, 2023Recent advancements in text-to-image generation have revolutionized numerous fields, including art and cinema, by automating the generation of high-quality, context-aware images and video. However, the utility of these technologies is often limited by the inadequacy of text prompts in guiding the generator to produce artistically coherent and subject-relevant images. In this paper, We describe the techniques that can be used to make Large Language Models (LLMs) act as Art Directors that enhance image and video generation. We describe our unified system for this called "LaDi". We explore how LaDi integrates multiple techniques for augmenting the capabilities of text-to-image generators (T2Is) and text-to-video generators (T2Vs), with a focus on constrained decoding, intelligent prompting, fine-tuning, and retrieval. LaDi and these techniques are being used today in apps and platforms developed by Plai Labs.