 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Ensembling and Meta-Learning Improve Outlier Detection in Randomized Controlled Trials?
Nov 09, 2023Modern multi-centre randomized controlled trials (MCRCTs) collect massive amounts of tabular data, and are monitored intensively for irregularities by humans. We began by empirically evaluating 6 modern machine learning-based outlier detection algorithms on the task of identifying irregular data in 838 datasets from 7 real-world MCRCTs with a total of 77,001 patients from over 44 countries. Our results reinforce key findings from prior work in the outlier detection literature on data from other domains. Existing algorithms often succeed at identifying irregularities without any supervision, with at least one algorithm exhibiting positive performance 70.6% of the time. However, performance across datasets varies substantially with no single algorithm performing consistently well, motivating new techniques for unsupervised model selection or other means of aggregating potentially discordant predictions from multiple candidate models. We propose the Meta-learned Probabilistic Ensemble (MePE), a simple algorithm for aggregating the predictions of multiple unsupervised models, and show that it performs favourably compared to recent meta-learning approaches for outlier detection model selection. While meta-learning shows promise, small ensembles outperform all forms of meta-learning on average, a negative result that may guide the application of current outlier detection approaches in healthcare and other real-world domains.
Pyclipse, a library for deidentification of free-text clinical notes
Nov 05, 2023



Automated deidentification of clinical text data is crucial due to the high cost of manual deidentification, which has been a barrier to sharing clinical text and the advancement of clinical natural language processing. However, creating effective automated deidentification tools faces several challenges, including issues in reproducibility due to differences in text processing, evaluation methods, and a lack of consistency across clinical domains and institutions. To address these challenges, we propose the pyclipse framework, a unified and configurable evaluation procedure to streamline the comparison of deidentification algorithms. Pyclipse serves as a single interface for running open-source deidentification algorithms on local clinical data, allowing for context-specific evaluation. To demonstrate the utility of pyclipse, we compare six deidentification algorithms across four public and two private clinical text datasets. We find that algorithm performance consistently falls short of the results reported in the original papers, even when evaluated on the same benchmark dataset. These discrepancies highlight the complexity of accurately assessing and comparing deidentification algorithms, emphasizing the need for a reproducible, adjustable, and extensible framework like pyclipse. Our framework lays the foundation for a unified approach to evaluate and improve deidentification tools, ultimately enhancing patient protection in clinical natural language processing.
Semi-Markov Offline Reinforcement Learning for Healthcare
Mar 21, 2022
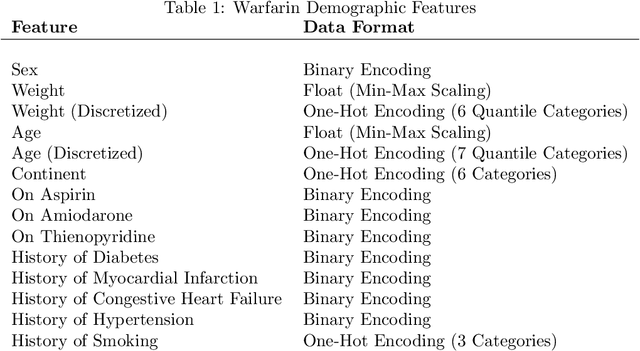
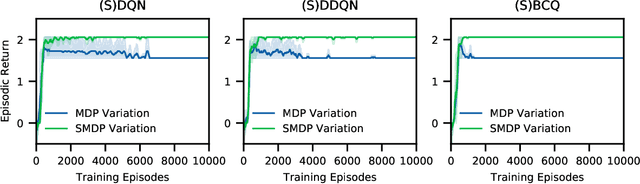
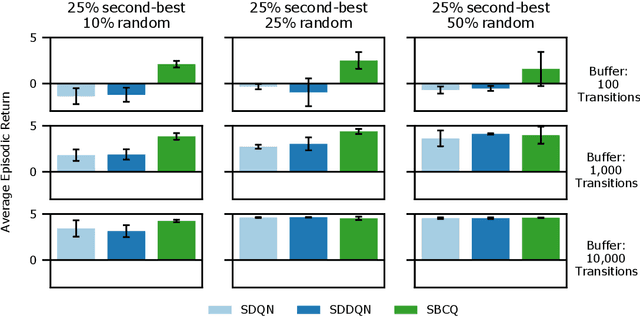
Reinforcement learning (RL) tasks are typically framed as Markov Decision Processes (MDPs), assuming that decisions are made at fixed time intervals. However, many applications of great importance, including healthcare, do not satisfy this assumption, yet they are commonly modelled as MDPs after an artificial reshaping of the data. In addition, most healthcare (and similar) problems are offline by nature, allowing for only retrospective studies. To address both challenges, we begin by discussing the Semi-MDP (SMDP) framework, which formally handles actions of variable timings. We next present a formal way to apply SMDP modifications to nearly any given value-based offline RL method. We use this theory to introduce three SMDP-based offline RL algorithms, namely, SDQN, SDDQN, and SBCQ. We then experimentally demonstrate that only these SMDP-based algorithms learn the optimal policy in variable-time environments, whereas their MDP counterparts do not. Finally, we apply our new algorithms to a real-world offline dataset pertaining to warfarin dosing for stroke prevention and demonstrate similar results.