 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial Models for Building Adaptive Model-Based Reinforcement Learning Agents
May 27, 2024In neuroscience, one of the key behavioral tests for determining whether a subject of study exhibits model-based behavior is to study its adaptiveness to local changes in the environment. In reinforcement learning, however, recent studies have shown that modern model-based agents display poor adaptivity to such changes. The main reason for this is that modern agents are typically designed to improve sample efficiency in single task settings and thus do not take into account the challenges that can arise in other settings. In local adaptation settings, one particularly important challenge is in quickly building and maintaining a sufficiently accurate model after a local change. This is challenging for deep model-based agents as their models and replay buffers are monolithic structures lacking distribution shift handling capabilities. In this study, we show that the conceptually simple idea of partial models can allow deep model-based agents to overcome this challenge and thus allow for building locally adaptive model-based agents. By modeling the different parts of the state space through different models, the agent can not only maintain a model that is accurate across the state space, but it can also quickly adapt it in the presence of a local change in the environment. We demonstrate this by showing that the use of partial models in agents such as deep Dyna-Q, PlaNet and Dreamer can allow for them to effectively adapt to the local changes in their environments.
Combining Spatial and Temporal Abstraction in Planning for Better Generalization
Sep 30, 2023
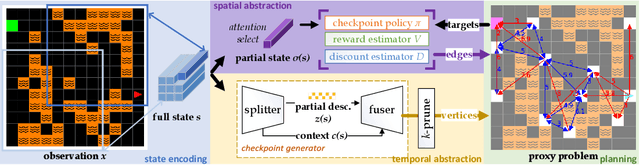
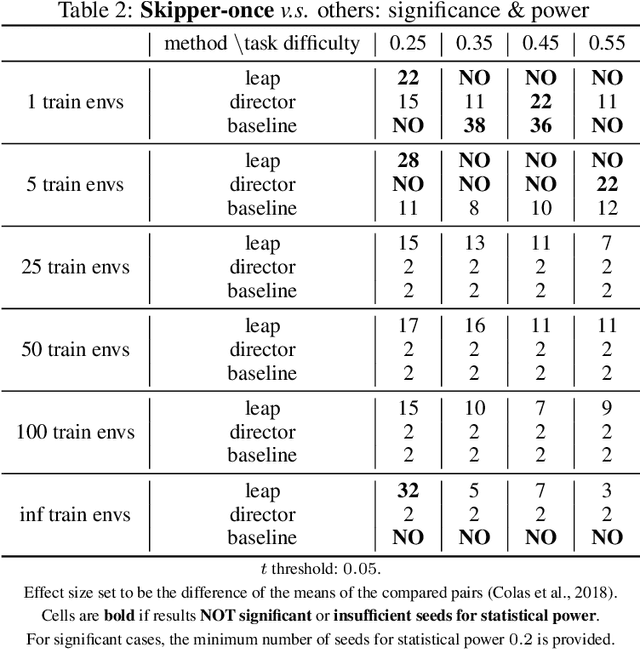
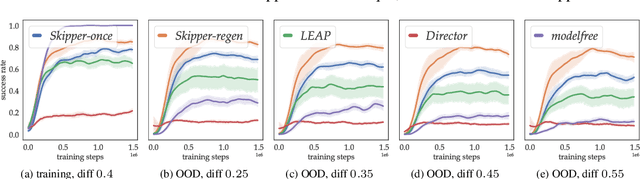
Inspired by human conscious planning, we propose Skipper, a model-based reinforcement learning agent that utilizes spatial and temporal abstractions to generalize learned skills in novel situations. It automatically decomposes the task at hand into smaller-scale, more manageable subtasks and hence enables sparse decision-making and focuses its computation on the relevant parts of the environment. This relies on the definition of a high-level proxy problem represented as a directed graph, in which vertices and edges are learned end-to-end using hindsight. Our theoretical analyses provide performance guarantees under appropriate assumptions and establish where our approach is expected to be helpful. Generalization-focused experiments validate Skipper's significant advantage in zero-shot generalization, compared to existing state-of-the-art hierarchical planning methods.
Minimal Value-Equivalent Partial Models for Scalable and Robust Planning in Lifelong Reinforcement Learning
Jan 24, 2023Learning models of the environment from pure interaction is often considered an essential component of building lifelong reinforcement learning agents. However, the common practice in model-based reinforcement learning is to learn models that model every aspect of the agent's environment, regardless of whether they are important in coming up with optimal decisions or not. In this paper, we argue that such models are not particularly well-suited for performing scalable and robust planning in lifelong reinforcement learning scenarios and we propose new kinds of models that only model the relevant aspects of the environment, which we call "minimal value-equivalent partial models". After providing a formal definition for these models, we provide theoretical results demonstrating the scalability advantages of performing planning with such models and then perform experiments to empirically illustrate our theoretical results. Then, we provide some useful heuristics on how to learn these kinds of models with deep learning architectures and empirically demonstrate that models learned in such a way can allow for performing planning that is robust to distribution shifts and compounding model errors. Overall, both our theoretical and empirical results suggest that minimal value-equivalent partial models can provide significant benefits to performing scalable and robust planning in lifelong reinforcement learning scenarios.
Understanding Decision-Time vs. Background Planning in Model-Based Reinforcement Learning
Jun 16, 2022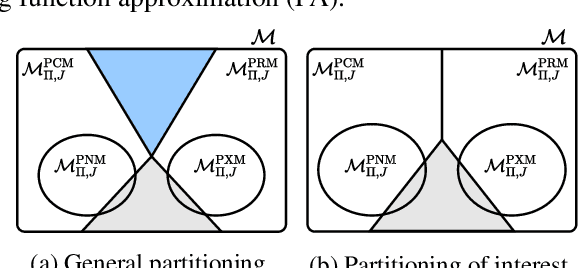



In model-based reinforcement learning, an agent can leverage a learned model to improve its way of behaving in different ways. Two prevalent approaches are decision-time planning and background planning. In this study, we are interested in understanding under what conditions and in which settings one of these two planning styles will perform better than the other in domains that require fast responses. After viewing them through the lens of dynamic programming, we first consider the classical instantiations of these planning styles and provide theoretical results and hypotheses on which one will perform better in the pure planning, planning & learning, and transfer learning settings. We then consider the modern instantiations of these planning styles and provide hypotheses on which one will perform better in the last two of the considered settings. Lastly, we perform several illustrative experiments to empirically validate both our theoretical results and hypotheses. Overall, our findings suggest that even though decision-time planning does not perform as well as background planning in their classical instantiations, in their modern instantiations, it can perform on par or better than background planning in both the planning & learning and transfer learning settings.
Constructing a Good Behavior Basis for Transfer using Generalized Policy Updates
Dec 30, 2021

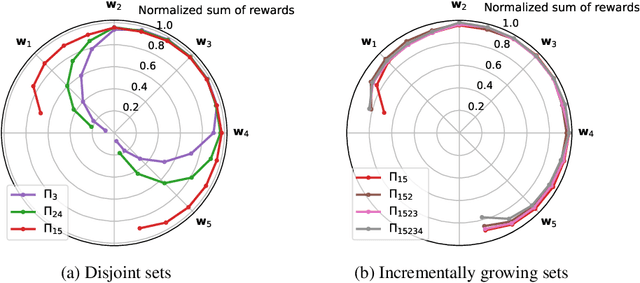
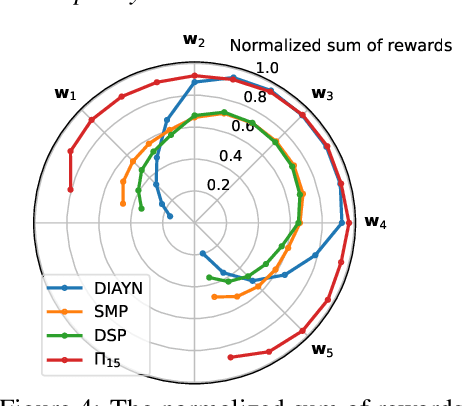
We study the problem of learning a good set of policies, so that when combined together, they can solve a wide variety of unseen reinforcement learning tasks with no or very little new data. Specifically, we consider the framework of generalized policy evaluation and improvement, in which the rewards for all tasks of interest are assumed to be expressible as a linear combination of a fixed set of features. We show theoretically that, under certain assumptions, having access to a specific set of diverse policies, which we call a set of independent policies, can allow for instantaneously achieving high-level performance on all possible downstream tasks which are typically more complex than the ones on which the agent was trained. Based on this theoretical analysis, we propose a simple algorithm that iteratively constructs this set of policies. In addition to empirically validating our theoretical results, we compare our approach with recently proposed diverse policy set construction methods and show that, while others fail, our approach is able to build a behavior basis that enables instantaneous transfer to all possible downstream tasks. We also show empirically that having access to a set of independent policies can better bootstrap the learning process on downstream tasks where the new reward function cannot be described as a linear combination of the features. Finally, we demonstrate that this policy set can be useful in a realistic lifelong reinforcement learning setting.
What is Going on Inside Recurrent Meta Reinforcement Learning Agents?
Apr 29, 2021

Recurrent meta reinforcement learning (meta-RL) agents are agents that employ a recurrent neural network (RNN) for the purpose of "learning a learning algorithm". After being trained on a pre-specified task distribution, the learned weights of the agent's RNN are said to implement an efficient learning algorithm through their activity dynamics, which allows the agent to quickly solve new tasks sampled from the same distribution. However, due to the black-box nature of these agents, the way in which they work is not yet fully understood. In this study, we shed light on the internal working mechanisms of these agents by reformulating the meta-RL problem using the Partially Observable Markov Decision Process (POMDP) framework. We hypothesize that the learned activity dynamics is acting as belief states for such agents. Several illustrative experiments suggest that this hypothesis is true, and that recurrent meta-RL agents can be viewed as agents that learn to act optimally in partially observable environments consisting of multiple related tasks. This view helps in understanding their failure cases and some interesting model-based results reported in the literature.
A Brief Look at Generalization in Visual Meta-Reinforcement Learning
Jul 03, 2020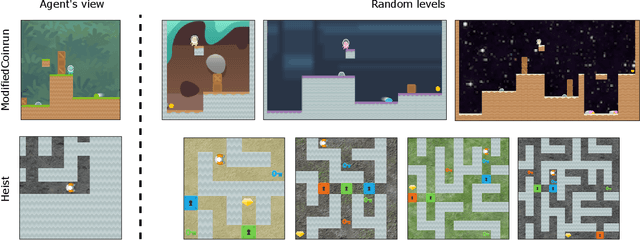
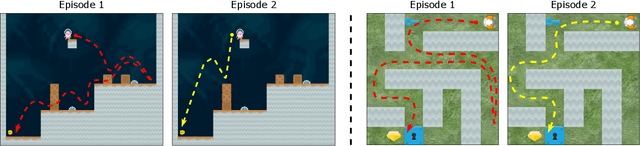
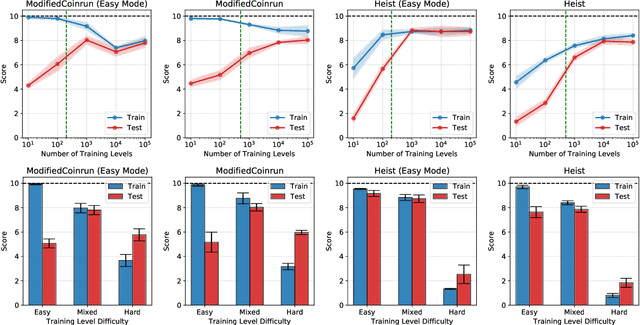

Due to the realization that deep reinforcement learning algorithms trained on high-dimensional tasks can strongly overfit to their training environments, there have been several studies that investigated the generalization performance of these algorithms. However, there has been no similar study that evaluated the generalization performance of algorithms that were specifically designed for generalization, i.e. meta-reinforcement learning algorithms. In this paper, we assess the generalization performance of these algorithms by leveraging high-dimensional, procedurally generated environments. We find that these algorithms can display strong overfitting when they are evaluated on challenging tasks. We also observe that scalability to high-dimensional tasks with sparse rewards remains a significant problem among many of the current meta-reinforcement learning algorithms. With these results, we highlight the need for developing meta-reinforcement learning algorithms that can both generalize and scale.
Attentive Deep Regression Networks for Real-Time Visual Face Tracking in Video Surveillance
Aug 10, 2019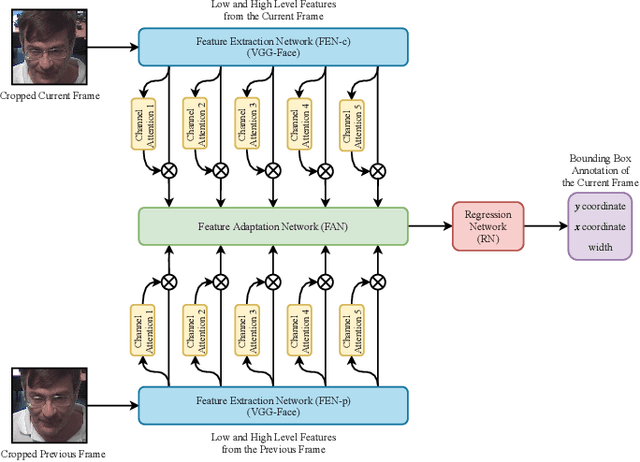
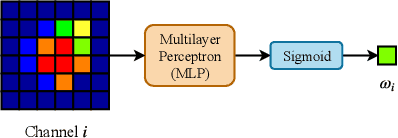
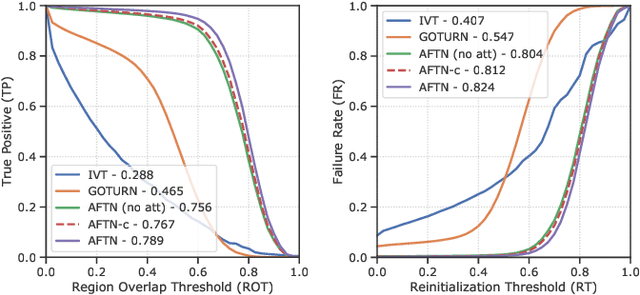
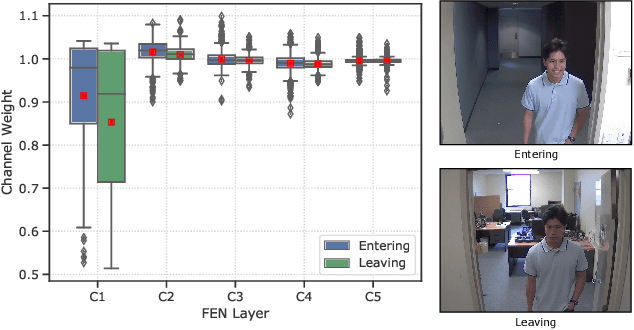
Visual face tracking is one of the most important tasks in video surveillance systems. However, due to the variations in pose, scale, expression, and illumination it is considered to be a difficult task. Recent studies show that deep learning methods have a significant potential in object tracking tasks and adaptive feature selection methods can boost their performance. Motivated by these, we propose an end-to-end attentive deep learning based tracker, that is build on top of the state-of-the-art GOTURN tracker, for the task of real-time visual face tracking in video surveillance. Our method outperforms the state-of-the-art GOTURN and IVT trackers by very large margins and it achieves speeds that are very far beyond the requirements of real-time tracking. Additionally, to overcome the scarce data problem in visual face tracking, we also provide bounding box annotations for the G1 and G2 sets of ChokePoint dataset and make it suitable for further studies in face tracking under surveillance conditions.