 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Brief Look at Generalization in Visual Meta-Reinforcement Learning
Paper and Code
Jul 03, 2020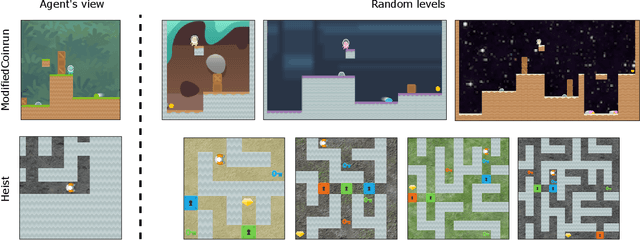
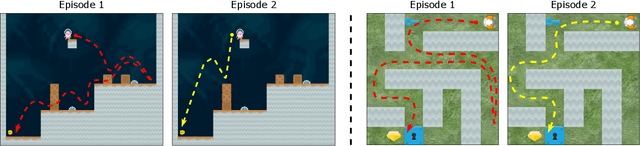
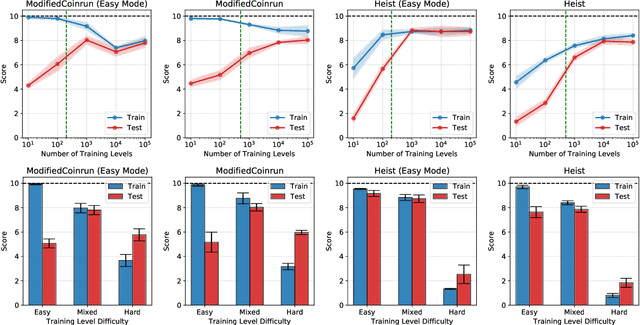

Due to the realization that deep reinforcement learning algorithms trained on high-dimensional tasks can strongly overfit to their training environments, there have been several studies that investigated the generalization performance of these algorithms. However, there has been no similar study that evaluated the generalization performance of algorithms that were specifically designed for generalization, i.e. meta-reinforcement learning algorithms. In this paper, we assess the generalization performance of these algorithms by leveraging high-dimensional, procedurally generated environments. We find that these algorithms can display strong overfitting when they are evaluated on challenging tasks. We also observe that scalability to high-dimensional tasks with sparse rewards remains a significant problem among many of the current meta-reinforcement learning algorithms. With these results, we highlight the need for developing meta-reinforcement learning algorithms that can both generalize and scale.