 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-training via Metric Learning for Source-Free Domain Adaptation of Semantic Segmentation
Dec 08, 2022Unsupervised source-free domain adaptation methods aim to train a model to be used in the target domain utilizing the pretrained source-domain model and unlabeled target-domain data, where the source data may not be accessible due to intellectual property or privacy issues. These methods frequently utilize self-training with pseudo-labeling thresholded by prediction confidence. In a source-free scenario, only supervision comes from target data, and thresholding limits the contribution of the self-training. In this study, we utilize self-training with a mean-teacher approach. The student network is trained with all predictions of the teacher network. Instead of thresholding the predictions, the gradients calculated from the pseudo-labels are weighted based on the reliability of the teacher's predictions. We propose a novel method that uses proxy-based metric learning to estimate reliability. We train a metric network on the encoder features of the teacher network. Since the teacher is updated with the moving average, the encoder feature space is slowly changing. Therefore, the metric network can be updated in training time, which enables end-to-end training. We also propose a metric-based online ClassMix method to augment the input of the student network where the patches to be mixed are decided based on the metric reliability. We evaluated our method in synthetic-to-real and cross-city scenarios. The benchmarks show that our method significantly outperforms the existing state-of-the-art methods.
Analysis of Visual Reasoning on One-Stage Object Detection
Feb 26, 2022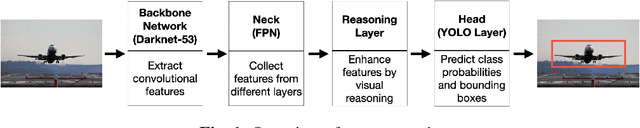

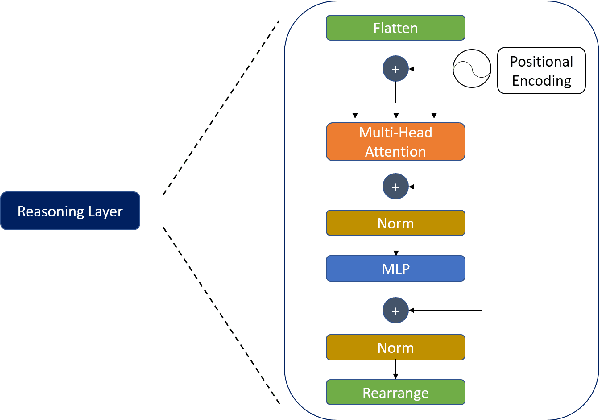
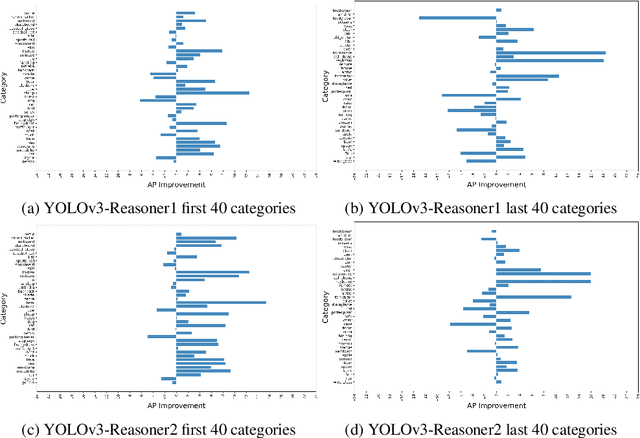
Current state-of-the-art one-stage object detectors are limited by treating each image region separately without considering possible relations of the objects. This causes dependency solely on high-quality convolutional feature representations for detecting objects successfully. However, this may not be possible sometimes due to some challenging conditions. In this paper, the usage of reasoning features on one-stage object detection is analyzed. We attempted different architectures that reason the relations of the image regions by using self-attention. YOLOv3-Reasoner2 model spatially and semantically enhances features in the reasoning layer and fuses them with the original convolutional features to improve performance. The YOLOv3-Reasoner2 model achieves around 2.5% absolute improvement with respect to baseline YOLOv3 on COCO in terms of mAP while still running in real-time.
Effect of Input Size on the Classification of Lung Nodules Using Convolutional Neural Networks
Jul 11, 2021Recent studies have shown that lung cancer screening using annual low-dose computed tomography (CT) reduces lung cancer mortality by 20% compared to traditional chest radiography. Therefore, CT lung screening has started to be used widely all across the world. However, analyzing these images is a serious burden for radiologists. The number of slices in a CT scan can be up to 600. Therefore, computer-aided-detection (CAD) systems are very important for faster and more accurate assessment of the data. In this study, we proposed a framework that analyzes CT lung screenings using convolutional neural networks (CNNs) to reduce false positives. We trained our model with different volume sizes and showed that volume size plays a critical role in the performance of the system. We also used different fusions in order to show their power and effect on the overall accuracy. 3D CNNs were preferred over 2D CNNs because 2D convolutional operations applied to 3D data could result in information loss. The proposed framework has been tested on the dataset provided by the LUNA16 Challenge and resulted in a sensitivity of 0.831 at 1 false positive per scan.
Self-training Guided Adversarial Domain Adaptation For Thermal Imagery
Jun 14, 2021
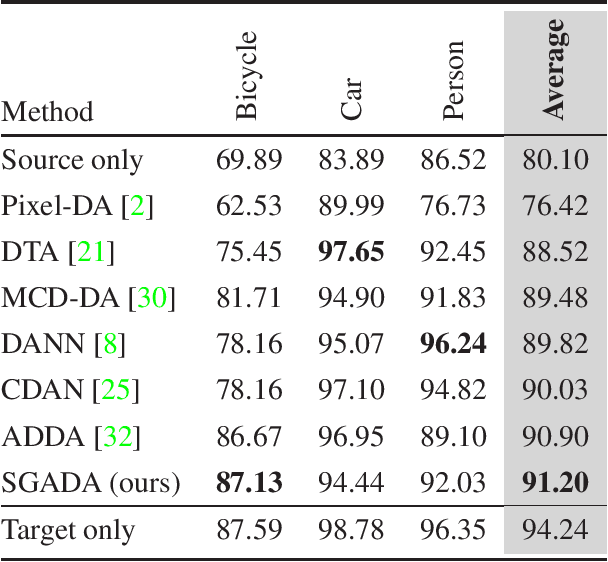
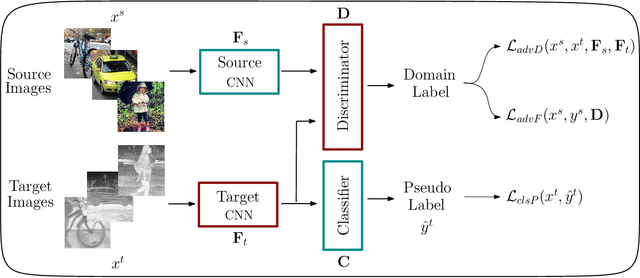
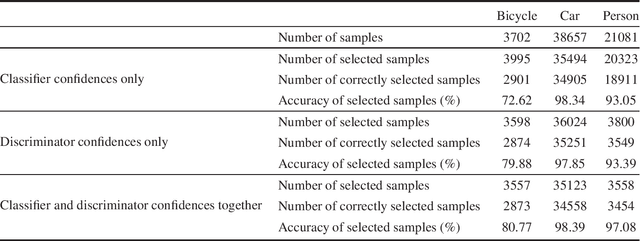
Deep models trained on large-scale RGB image datasets have shown tremendous success. It is important to apply such deep models to real-world problems. However, these models suffer from a performance bottleneck under illumination changes. Thermal IR cameras are more robust against such changes, and thus can be very useful for the real-world problems. In order to investigate efficacy of combining feature-rich visible spectrum and thermal image modalities, we propose an unsupervised domain adaptation method which does not require RGB-to-thermal image pairs. We employ large-scale RGB dataset MS-COCO as source domain and thermal dataset FLIR ADAS as target domain to demonstrate results of our method. Although adversarial domain adaptation methods aim to align the distributions of source and target domains, simply aligning the distributions cannot guarantee perfect generalization to the target domain. To this end, we propose a self-training guided adversarial domain adaptation method to promote generalization capabilities of adversarial domain adaptation methods. To perform self-training, pseudo labels are assigned to the samples on the target thermal domain to learn more generalized representations for the target domain. Extensive experimental analyses show that our proposed method achieves better results than the state-of-the-art adversarial domain adaptation methods. The code and models are publicly available.
GAIT: Gradient Adjusted Unsupervised Image-to-Image Translation
Sep 02, 2020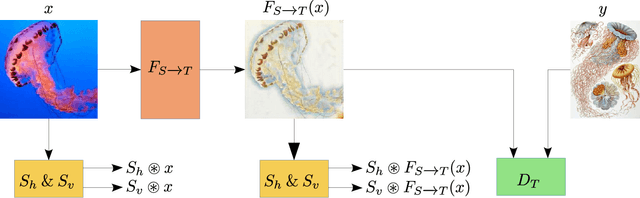
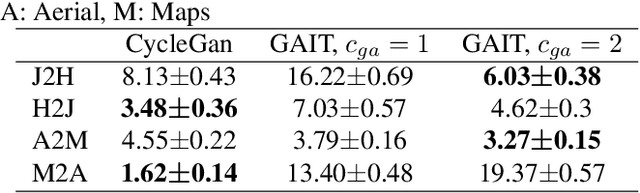


Image-to-image translation (IIT) has made much progress recently with the development of adversarial learning. In most of the recent work, an adversarial loss is utilized to match the distributions of the translated and target image sets. However, this may create artifacts if two domains have different marginal distributions, for example, in uniform areas. In this work, we propose an unsupervised IIT method that preserves the uniform regions after the translation. The gradient adjustment loss, which is the L2 norm between the Sobel response of the target image and the adjusted Sobel response of the source images, is utilized. The proposed method is validated on the jellyfish-to-Haeckel dataset, which is prepared to demonstrate the mentioned problem, which contains images with different background distributions. We demonstrate that our method obtained a performance gain compared to the baseline method qualitatively and quantitatively, showing the effectiveness of the proposed method.
Attentive Deep Regression Networks for Real-Time Visual Face Tracking in Video Surveillance
Aug 10, 2019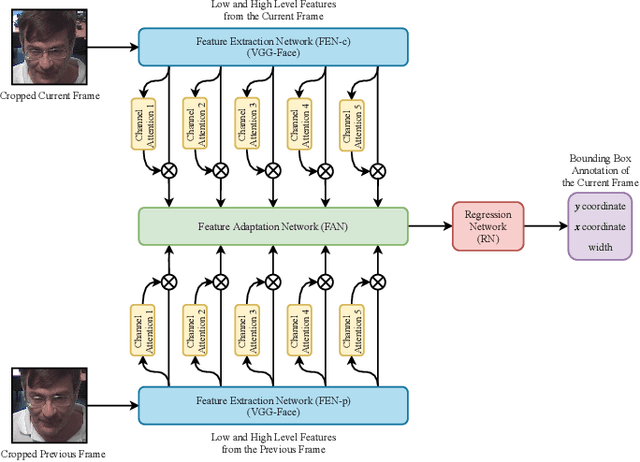
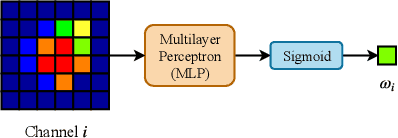
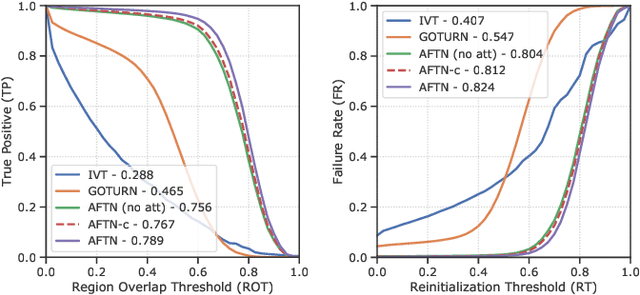
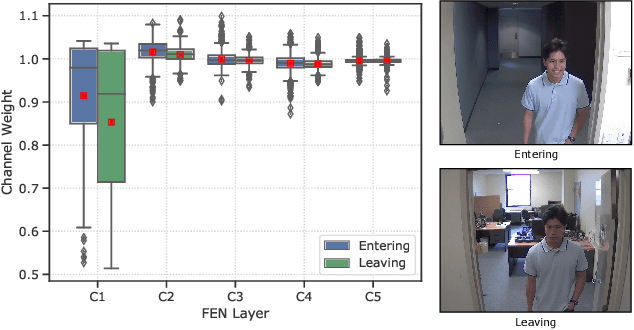
Visual face tracking is one of the most important tasks in video surveillance systems. However, due to the variations in pose, scale, expression, and illumination it is considered to be a difficult task. Recent studies show that deep learning methods have a significant potential in object tracking tasks and adaptive feature selection methods can boost their performance. Motivated by these, we propose an end-to-end attentive deep learning based tracker, that is build on top of the state-of-the-art GOTURN tracker, for the task of real-time visual face tracking in video surveillance. Our method outperforms the state-of-the-art GOTURN and IVT trackers by very large margins and it achieves speeds that are very far beyond the requirements of real-time tracking. Additionally, to overcome the scarce data problem in visual face tracking, we also provide bounding box annotations for the G1 and G2 sets of ChokePoint dataset and make it suitable for further studies in face tracking under surveillance conditions.
False Positive Reduction in Lung Computed Tomography Images using Convolutional Neural Networks
Nov 04, 2018

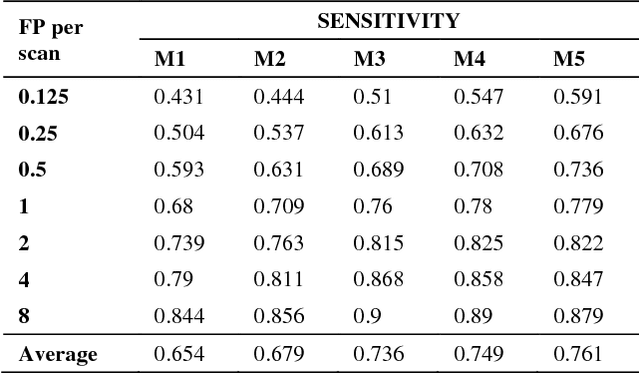
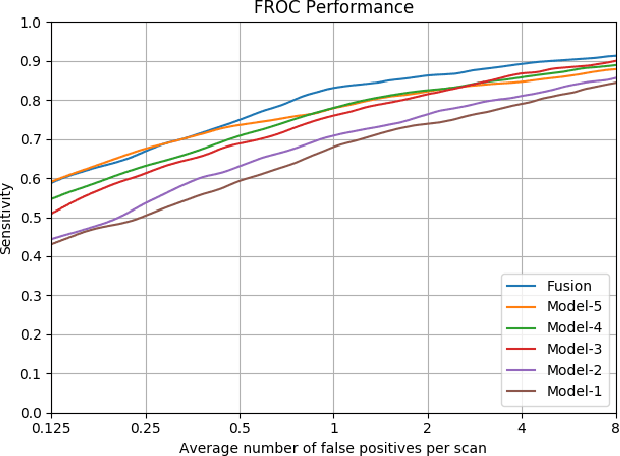
Recent studies have shown that lung cancer screening using annual low-dose computed tomography (CT) reduces lung cancer mortality by 20% compared to traditional chest radiography. Therefore, CT lung screening has started to be used widely all across the world. However, analyzing these images is a serious burden for radiologists. In this study, we propose a novel and simple framework that analyzes CT lung screenings using convolutional neural networks (CNNs) and reduces false positives. Our framework shows that even non-complex architectures are very powerful to classify 3D nodule data when compared to traditional methods. We also use different fusions in order to show their power and effect on the overall score. 3D CNNs are preferred over 2D CNNs because data are in 3D, and 2D convolutional operations may result in information loss. Mini-batch is used in order to overcome class-imbalance. Proposed framework has been validated according to the LUNA16 challenge evaluation and got score of 0.786, which is the average sensitivity values at seven predefined false positive (FP) points.