 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Visual Reasoning on One-Stage Object Detection
Paper and Code
Feb 26, 2022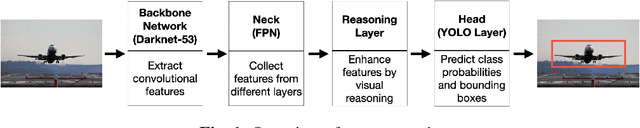

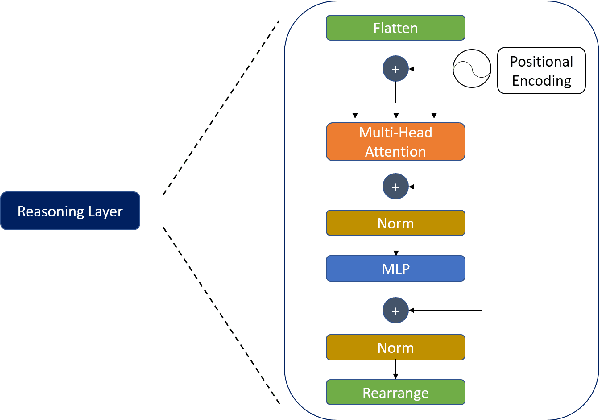
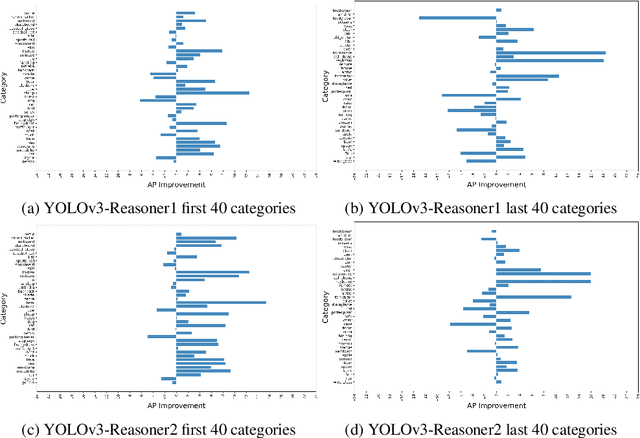
Current state-of-the-art one-stage object detectors are limited by treating each image region separately without considering possible relations of the objects. This causes dependency solely on high-quality convolutional feature representations for detecting objects successfully. However, this may not be possible sometimes due to some challenging conditions. In this paper, the usage of reasoning features on one-stage object detection is analyzed. We attempted different architectures that reason the relations of the image regions by using self-attention. YOLOv3-Reasoner2 model spatially and semantically enhances features in the reasoning layer and fuses them with the original convolutional features to improve performance. The YOLOv3-Reasoner2 model achieves around 2.5% absolute improvement with respect to baseline YOLOv3 on COCO in terms of mAP while still running in real-time.