 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNext-Latent Prediction Transformers Learn Compact World Models
Nov 08, 2025Transformers replace recurrence with a memory that grows with sequence length and self-attention that enables ad-hoc look ups over past tokens. Consequently, they lack an inherent incentive to compress history into compact latent states with consistent transition rules. This often leads to learning solutions that generalize poorly. We introduce Next-Latent Prediction (NextLat), which extends standard next-token training with self-supervised predictions in the latent space. Specifically, NextLat trains a transformer to learn latent representations that are predictive of its next latent state given the next output token. Theoretically, we show that these latents provably converge to belief states, compressed information of the history necessary to predict the future. This simple auxiliary objective also injects a recurrent inductive bias into transformers, while leaving their architecture, parallel training, and inference unchanged. NextLat effectively encourages the transformer to form compact internal world models with its own belief states and transition dynamics -- a crucial property absent in standard next-token prediction transformers. Empirically, across benchmarks targeting core sequence modeling competencies -- world modeling, reasoning, planning, and language modeling -- NextLat demonstrates significant gains over standard next-token training in downstream accuracy, representation compression, and lookahead planning. NextLat stands as a simple and efficient paradigm for shaping transformer representations toward stronger generalization.
Learning to Achieve Goals with Belief State Transformers
Oct 30, 2024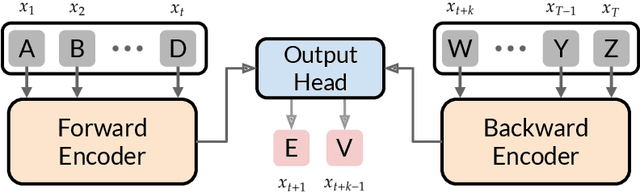
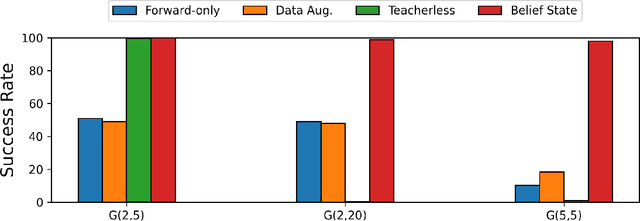
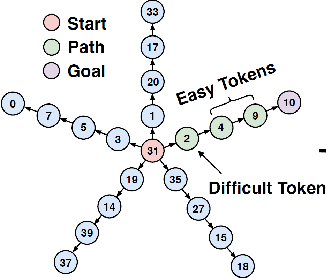
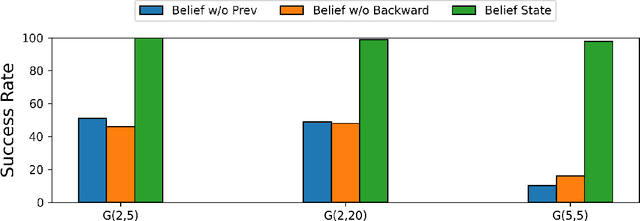
We introduce the "Belief State Transformer", a next-token predictor that takes both a prefix and suffix as inputs, with a novel objective of predicting both the next token for the prefix and the previous token for the suffix. The Belief State Transformer effectively learns to solve challenging problems that conventional forward-only transformers struggle with, in a domain-independent fashion. Key to this success is learning a compact belief state that captures all relevant information necessary for accurate predictions. Empirical ablations show that each component of the model is essential in difficult scenarios where standard Transformers fall short. For the task of story writing with known prefixes and suffixes, our approach outperforms the Fill-in-the-Middle method for reaching known goals and demonstrates improved performance even when the goals are unknown. Altogether, the Belief State Transformer enables more efficient goal-conditioned decoding, better test-time inference, and high-quality text representations on small scale problems.
Unified Auto-Encoding with Masked Diffusion
Jun 25, 2024At the core of both successful generative and self-supervised representation learning models there is a reconstruction objective that incorporates some form of image corruption. Diffusion models implement this approach through a scheduled Gaussian corruption process, while masked auto-encoder models do so by masking patches of the image. Despite their different approaches, the underlying similarity in their methodologies suggests a promising avenue for an auto-encoder capable of both de-noising tasks. We propose a unified self-supervised objective, dubbed Unified Masked Diffusion (UMD), that combines patch-based and noise-based corruption techniques within a single auto-encoding framework. Specifically, UMD modifies the diffusion transformer (DiT) training process by introducing an additional noise-free, high masking representation step in the diffusion noising schedule, and utilizes a mixed masked and noised image for subsequent timesteps. By integrating features useful for diffusion modeling and for predicting masked patch tokens, UMD achieves strong performance in downstream generative and representation learning tasks, including linear probing and class-conditional generation. This is achieved without the need for heavy data augmentations, multiple views, or additional encoders. Furthermore, UMD improves over the computational efficiency of prior diffusion based methods in total training time. We release our code at https://github.com/philippe-eecs/small-vision.
Reward Centering
May 16, 2024We show that discounted methods for solving continuing reinforcement learning problems can perform significantly better if they center their rewards by subtracting out the rewards' empirical average. The improvement is substantial at commonly used discount factors and increases further as the discount factor approaches one. In addition, we show that if a problem's rewards are shifted by a constant, then standard methods perform much worse, whereas methods with reward centering are unaffected. Estimating the average reward is straightforward in the on-policy setting; we propose a slightly more sophisticated method for the off-policy setting. Reward centering is a general idea, so we expect almost every reinforcement-learning algorithm to benefit by the addition of reward centering.
Robotic Offline RL from Internet Videos via Value-Function Pre-Training
Sep 22, 2023Pre-training on Internet data has proven to be a key ingredient for broad generalization in many modern ML systems. What would it take to enable such capabilities in robotic reinforcement learning (RL)? Offline RL methods, which learn from datasets of robot experience, offer one way to leverage prior data into the robotic learning pipeline. However, these methods have a "type mismatch" with video data (such as Ego4D), the largest prior datasets available for robotics, since video offers observation-only experience without the action or reward annotations needed for RL methods. In this paper, we develop a system for leveraging large-scale human video datasets in robotic offline RL, based entirely on learning value functions via temporal-difference learning. We show that value learning on video datasets learns representations that are more conducive to downstream robotic offline RL than other approaches for learning from video data. Our system, called V-PTR, combines the benefits of pre-training on video data with robotic offline RL approaches that train on diverse robot data, resulting in value functions and policies for manipulation tasks that perform better, act robustly, and generalize broadly. On several manipulation tasks on a real WidowX robot, our framework produces policies that greatly improve over prior methods. Our video and additional details can be found at https://dibyaghosh.com/vptr/
Ignorance is Bliss: Robust Control via Information Gating
Mar 10, 2023



Informational parsimony -- i.e., using the minimal information required for a task, -- provides a useful inductive bias for learning representations that achieve better generalization by being robust to noise and spurious correlations. We propose information gating in the pixel space as a way to learn more parsimonious representations. Information gating works by learning masks that capture only the minimal information required to solve a given task. Intuitively, our models learn to identify which visual cues actually matter for a given task. We gate information using a differentiable parameterization of the signal-to-noise ratio, which can be applied to arbitrary values in a network, e.g.~masking out pixels at the input layer. We apply our approach, which we call InfoGating, to various objectives such as: multi-step forward and inverse dynamics, Q-learning, behavior cloning, and standard self-supervised tasks. Our experiments show that learning to identify and use minimal information can improve generalization in downstream tasks -- e.g., policies based on info-gated images are considerably more robust to distracting/irrelevant visual features.
Representation Learning in Deep RL via Discrete Information Bottleneck
Dec 28, 2022


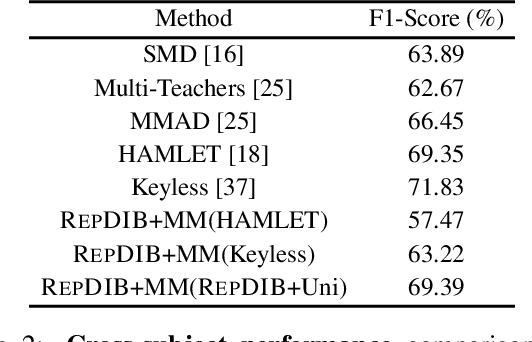
Several self-supervised representation learning methods have been proposed for reinforcement learning (RL) with rich observations. For real-world applications of RL, recovering underlying latent states is crucial, particularly when sensory inputs contain irrelevant and exogenous information. In this work, we study how information bottlenecks can be used to construct latent states efficiently in the presence of task-irrelevant information. We propose architectures that utilize variational and discrete information bottlenecks, coined as RepDIB, to learn structured factorized representations. Exploiting the expressiveness bought by factorized representations, we introduce a simple, yet effective, bottleneck that can be integrated with any existing self-supervised objective for RL. We demonstrate this across several online and offline RL benchmarks, along with a real robot arm task, where we find that compressed representations with RepDIB can lead to strong performance improvements, as the learned bottlenecks help predict only the relevant state while ignoring irrelevant information.
Agent-Controller Representations: Principled Offline RL with Rich Exogenous Information
Oct 31, 2022Learning to control an agent from data collected offline in a rich pixel-based visual observation space is vital for real-world applications of reinforcement learning (RL). A major challenge in this setting is the presence of input information that is hard to model and irrelevant to controlling the agent. This problem has been approached by the theoretical RL community through the lens of exogenous information, i.e, any control-irrelevant information contained in observations. For example, a robot navigating in busy streets needs to ignore irrelevant information, such as other people walking in the background, textures of objects, or birds in the sky. In this paper, we focus on the setting with visually detailed exogenous information, and introduce new offline RL benchmarks offering the ability to study this problem. We find that contemporary representation learning techniques can fail on datasets where the noise is a complex and time dependent process, which is prevalent in practical applications. To address these, we propose to use multi-step inverse models, which have seen a great deal of interest in the RL theory community, to learn Agent-Controller Representations for Offline-RL (ACRO). Despite being simple and requiring no reward, we show theoretically and empirically that the representation created by this objective greatly outperforms baselines.
Learning Representations for Pixel-based Control: What Matters and Why?
Nov 15, 2021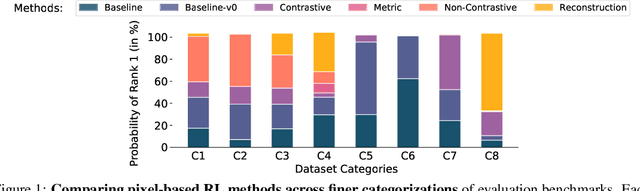
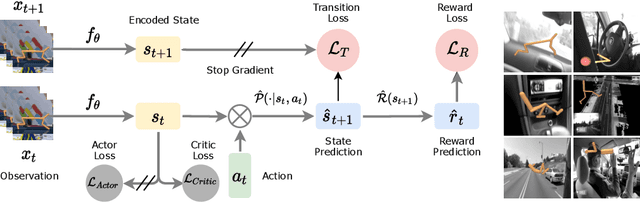
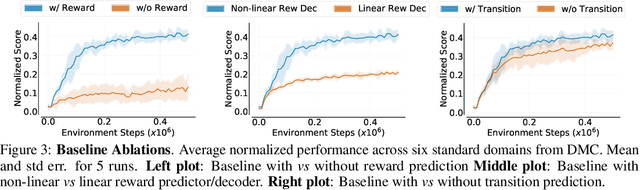

Learning representations for pixel-based control has garnered significant attention recently in reinforcement learning. A wide range of methods have been proposed to enable efficient learning, leading to sample complexities similar to those in the full state setting. However, moving beyond carefully curated pixel data sets (centered crop, appropriate lighting, clear background, etc.) remains challenging. In this paper, we adopt a more difficult setting, incorporating background distractors, as a first step towards addressing this challenge. We present a simple baseline approach that can learn meaningful representations with no metric-based learning, no data augmentations, no world-model learning, and no contrastive learning. We then analyze when and why previously proposed methods are likely to fail or reduce to the same performance as the baseline in this harder setting and why we should think carefully about extending such methods beyond the well curated environments. Our results show that finer categorization of benchmarks on the basis of characteristics like density of reward, planning horizon of the problem, presence of task-irrelevant components, etc., is crucial in evaluating algorithms. Based on these observations, we propose different metrics to consider when evaluating an algorithm on benchmark tasks. We hope such a data-centric view can motivate researchers to rethink representation learning when investigating how to best apply RL to real-world tasks.
Model-Invariant State Abstractions for Model-Based Reinforcement Learning
Feb 19, 2021
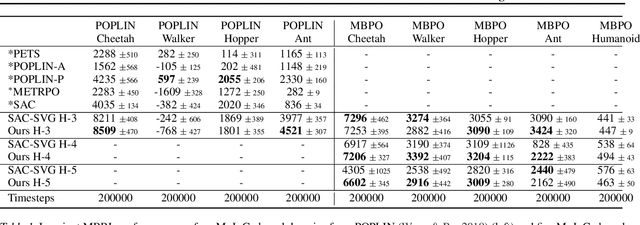

Accuracy and generalization of dynamics models is key to the success of model-based reinforcement learning (MBRL). As the complexity of tasks increases, learning dynamics models becomes increasingly sample inefficient for MBRL methods. However, many tasks also exhibit sparsity in the dynamics, i.e., actions have only a local effect on the system dynamics. In this paper, we exploit this property with a causal invariance perspective in the single-task setting, introducing a new type of state abstraction called \textit{model-invariance}. Unlike previous forms of state abstractions, a model-invariance state abstraction leverages causal sparsity over state variables. This allows for generalization to novel combinations of unseen values of state variables, something that non-factored forms of state abstractions cannot do. We prove that an optimal policy can be learned over this model-invariance state abstraction. Next, we propose a practical method to approximately learn a model-invariant representation for complex domains. We validate our approach by showing improved modeling performance over standard maximum likelihood approaches on challenging tasks, such as the MuJoCo-based Humanoid. Furthermore, within the MBRL setting we show strong performance gains w.r.t. sample efficiency across a host of other continuous control tasks.