 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Model-based Model-free Diffusion for Planning with Constraints
Sep 10, 2025Model-free diffusion planners have shown great promise for robot motion planning, but practical robotic systems often require combining them with model-based optimization modules to enforce constraints, such as safety. Naively integrating these modules presents compatibility challenges when diffusion's multi-modal outputs behave adversarially to optimization-based modules. To address this, we introduce Joint Model-based Model-free Diffusion (JM2D), a novel generative modeling framework. JM2D formulates module integration as a joint sampling problem to maximize compatibility via an interaction potential, without additional training. Using importance sampling, JM2D guides modules outputs based only on evaluations of the interaction potential, thus handling non-differentiable objectives commonly arising from non-convex optimization modules. We evaluate JM2D via application to aligning diffusion planners with safety modules on offline RL and robot manipulation. JM2D significantly improves task performance compared to conventional safety filters without sacrificing safety. Further, we show that conditional generation is a special case of JM2D and elucidate key design choices by comparing with SOTA gradient-based and projection-based diffusion planners. More details at: https://jm2d-corl25.github.io/.
Generative Trajectory Stitching through Diffusion Composition
Mar 07, 2025



Effective trajectory stitching for long-horizon planning is a significant challenge in robotic decision-making. While diffusion models have shown promise in planning, they are limited to solving tasks similar to those seen in their training data. We propose CompDiffuser, a novel generative approach that can solve new tasks by learning to compositionally stitch together shorter trajectory chunks from previously seen tasks. Our key insight is modeling the trajectory distribution by subdividing it into overlapping chunks and learning their conditional relationships through a single bidirectional diffusion model. This allows information to propagate between segments during generation, ensuring physically consistent connections. We conduct experiments on benchmark tasks of various difficulties, covering different environment sizes, agent state dimension, trajectory types, training data quality, and show that CompDiffuser significantly outperforms existing methods.
RAIL: Reachability-Aided Imitation Learning for Safe Policy Execution
Sep 28, 2024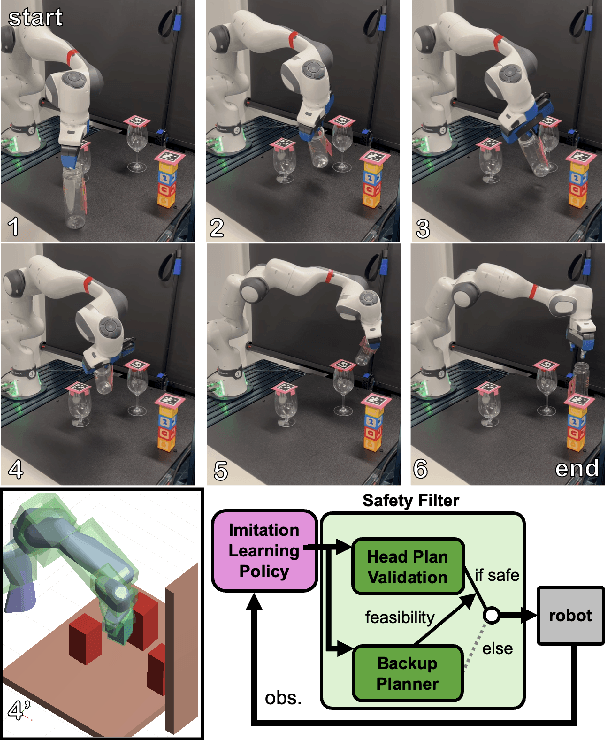
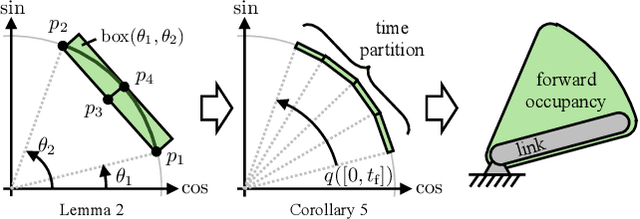


Imitation learning (IL) has shown great success in learning complex robot manipulation tasks. However, there remains a need for practical safety methods to justify widespread deployment. In particular, it is important to certify that a system obeys hard constraints on unsafe behavior in settings when it is unacceptable to design a tradeoff between performance and safety via tuning the policy (i.e. soft constraints). This leads to the question, how does enforcing hard constraints impact the performance (meaning safely completing tasks) of an IL policy? To answer this question, this paper builds a reachability-based safety filter to enforce hard constraints on IL, which we call Reachability-Aided Imitation Learning (RAIL). Through evaluations with state-of-the-art IL policies in mobile robots and manipulation tasks, we make two key findings. First, the highest-performing policies are sometimes only so because they frequently violate constraints, and significantly lose performance under hard constraints. Second, surprisingly, hard constraints on the lower-performing policies can occasionally increase their ability to perform tasks safely. Finally, hardware evaluation confirms the method can operate in real time.
Generative Factor Chaining: Coordinated Manipulation with Diffusion-based Factor Graph
Sep 24, 2024Learning to plan for multi-step, multi-manipulator tasks is notoriously difficult because of the large search space and the complex constraint satisfaction problems. We present Generative Factor Chaining~(GFC), a composable generative model for planning. GFC represents a planning problem as a spatial-temporal factor graph, where nodes represent objects and robots in the scene, spatial factors capture the distributions of valid relationships among nodes, and temporal factors represent the distributions of skill transitions. Each factor is implemented as a modular diffusion model, which are composed during inference to generate feasible long-horizon plans through bi-directional message passing. We show that GFC can solve complex bimanual manipulation tasks and exhibits strong generalization to unseen planning tasks with novel combinations of objects and constraints. More details can be found at: https://generative-fc.github.io/
Learning Representations for Pixel-based Control: What Matters and Why?
Nov 15, 2021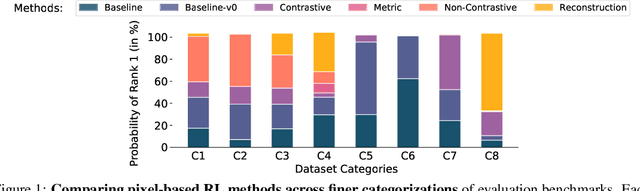
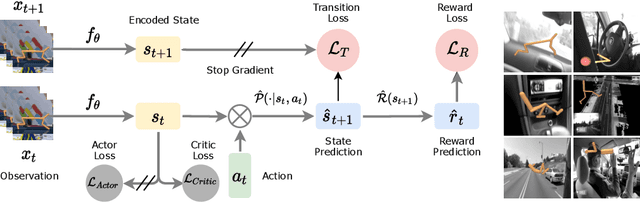
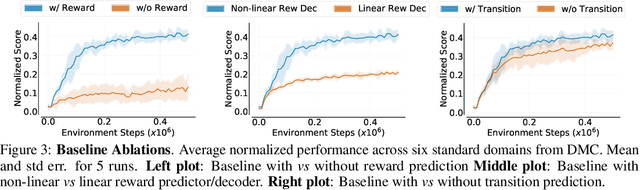

Learning representations for pixel-based control has garnered significant attention recently in reinforcement learning. A wide range of methods have been proposed to enable efficient learning, leading to sample complexities similar to those in the full state setting. However, moving beyond carefully curated pixel data sets (centered crop, appropriate lighting, clear background, etc.) remains challenging. In this paper, we adopt a more difficult setting, incorporating background distractors, as a first step towards addressing this challenge. We present a simple baseline approach that can learn meaningful representations with no metric-based learning, no data augmentations, no world-model learning, and no contrastive learning. We then analyze when and why previously proposed methods are likely to fail or reduce to the same performance as the baseline in this harder setting and why we should think carefully about extending such methods beyond the well curated environments. Our results show that finer categorization of benchmarks on the basis of characteristics like density of reward, planning horizon of the problem, presence of task-irrelevant components, etc., is crucial in evaluating algorithms. Based on these observations, we propose different metrics to consider when evaluating an algorithm on benchmark tasks. We hope such a data-centric view can motivate researchers to rethink representation learning when investigating how to best apply RL to real-world tasks.
Linear Policies are Sufficient to Realize Robust Bipedal Walking on Challenging Terrains
Oct 05, 2021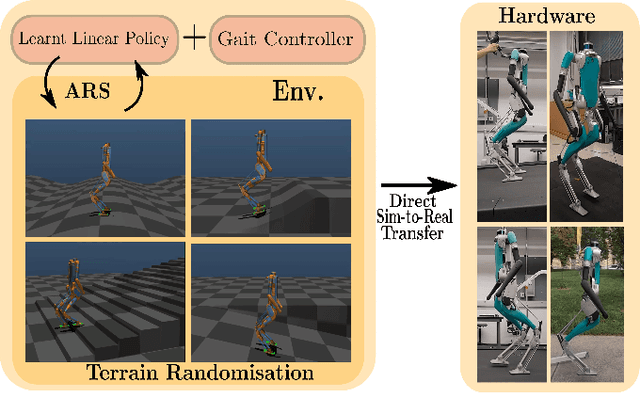
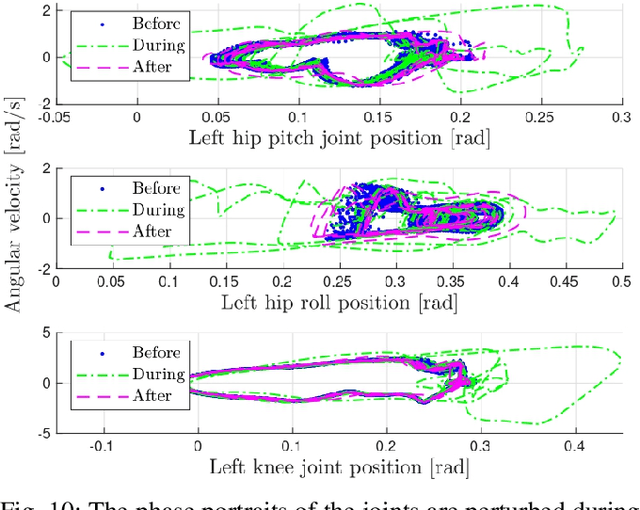
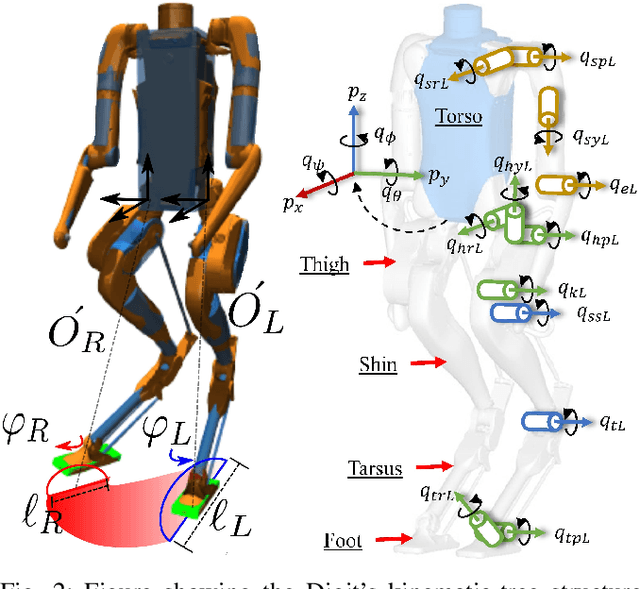
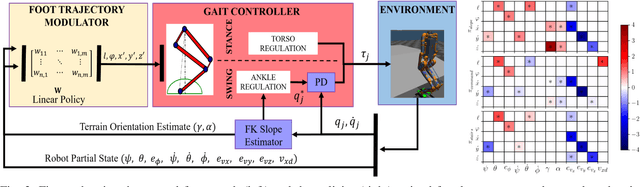
In this work, we demonstrate robust walking in the bipedal robot Digit on uneven terrains by just learning a single linear policy. In particular, we propose a new control pipeline, wherein the high-level trajectory modulator shapes the end-foot ellipsoidal trajectories, and the low-level gait controller regulates the torso and ankle orientation. The foot-trajectory modulator uses a linear policy and the regulator uses a linear PD control law. As opposed to neural network-based policies, the proposed linear policy has only 13 learnable parameters, thereby not only guaranteeing sample efficient learning but also enabling simplicity and interpretability of the policy. This is achieved with no loss of performance on challenging terrains like slopes, stairs and outdoor landscapes. We first demonstrate robust walking in the custom simulation environment, MuJoCo, and then directly transfer to hardware with no modification of the control pipeline. We subject the biped to a series of pushes and terrain height changes, both indoors and outdoors, thereby validating the presented work.
Learning Linear Policies for Robust Bipedal Locomotion on Terrains with Varying Slopes
Apr 04, 2021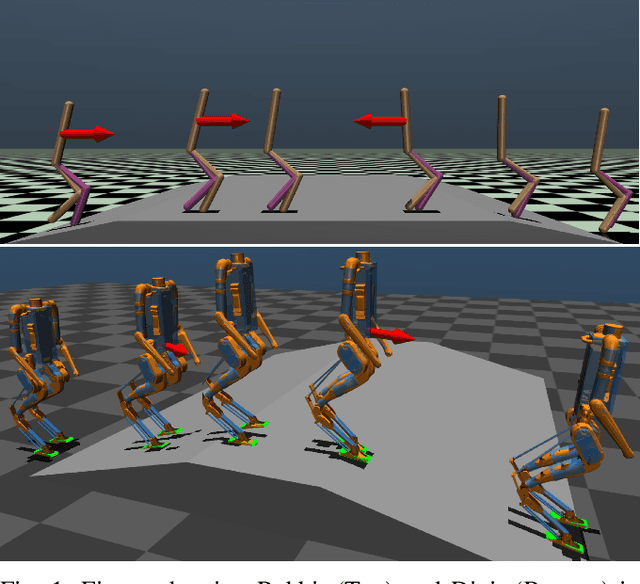
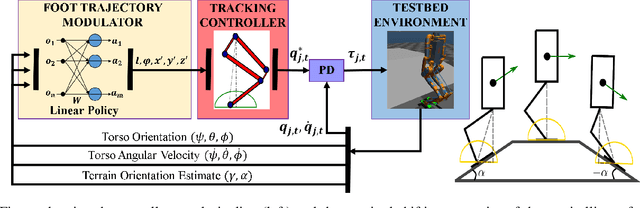
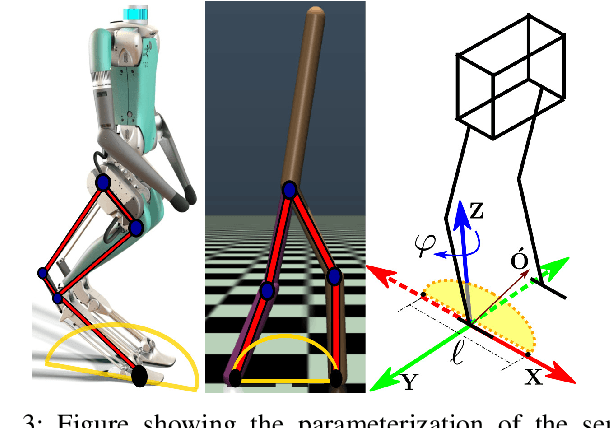
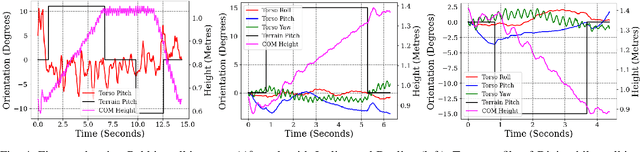
In this paper, with a view toward deployment of light-weight control frameworks for bipedal walking robots, we realize end-foot trajectories that are shaped by a single linear feedback policy. We learn this policy via a model-free and a gradient-free learning algorithm, Augmented Random Search (ARS), in the two robot platforms Rabbit and Digit. Our contributions are two-fold: a) By using torso and support plane orientation as inputs, we achieve robust walking on slopes of up to 20 degrees in simulation. b) We demonstrate additional behaviors like walking backwards, stepping-in-place, and recovery from external pushes of up to 120 N. The end result is a robust and a fast feedback control law for bipedal walking on terrains with varying slopes. Towards the end, we also provide preliminary results of hardware transfer to Digit.
Planning Brachistochrone Hip Trajectory for a Toe-Foot Bipedal Robot going Downstairs
Dec 02, 2020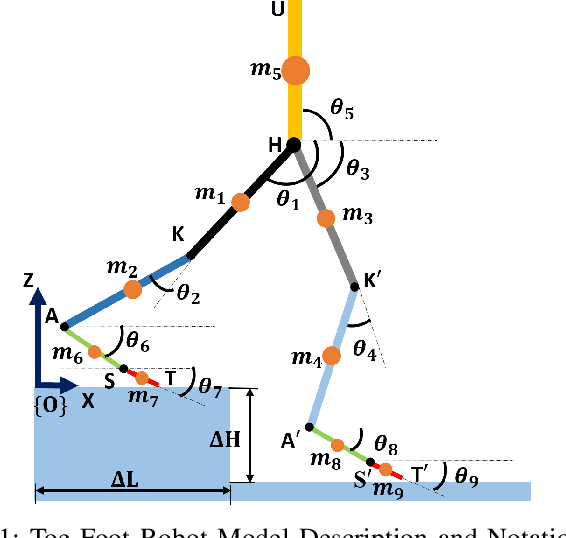

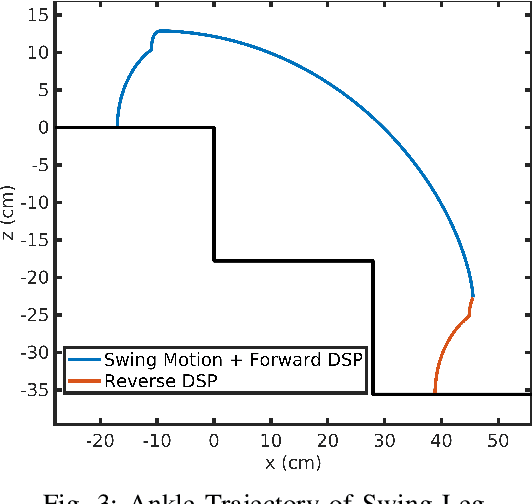
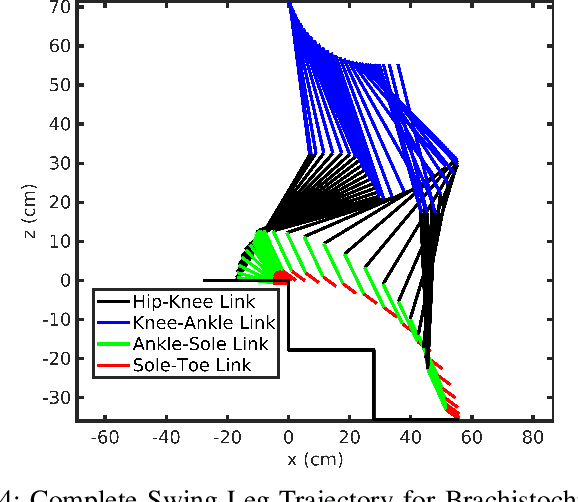
A novel efficient downstairs trajectory is proposed for a 9 link biped robot model with toe-foot. Brachistochrone is the fastest descent trajectory for a particle moving only under the influence of gravity. In most situations, while climbing downstairs, human hip also follow brachistochrone trajectory for a more responsive motion. Here, an adaptive trajectory planning algorithm is developed so that biped robots of varying link lengths, masses can climb down on varying staircase dimensions. We assume that the center of gravity (COG) of the biped concerned lies on the hip. Zero Moment Point (ZMP) based COG trajectory is considered and its stability is ensured. Cycloidal trajectory is considered for ankle of the swing leg. Parameters of both cycloid and brachistochrone depends on dimensions of staircase steps. Hence this paper can be broadly divided into 4 steps 1) Developing ZMP based brachistochrone trajectory for hip 2) Cycloidal trajectory planning for ankle by taking proper collision constraints 3) Solving Inverse kinematics using unsupervised artificial neural network (ANN) 4) Comparison between the proposed, a circular arc and a virtual slope based hip trajectory. The proposed algorithms have been implemented using MATLAB.
Cycloidal Trajectory Realization on Staircase with Optimal Trajectory Tracking Control based on Neural Network Temporal Quantized Lagrange Dynamics (NNTQLD)
Dec 02, 2020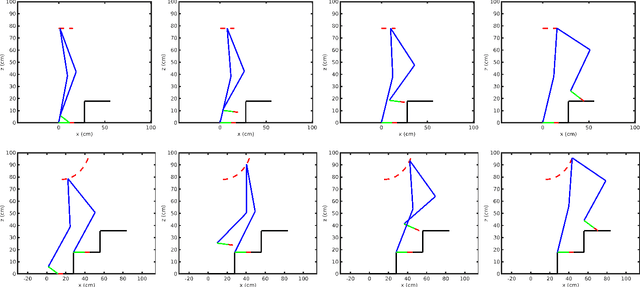
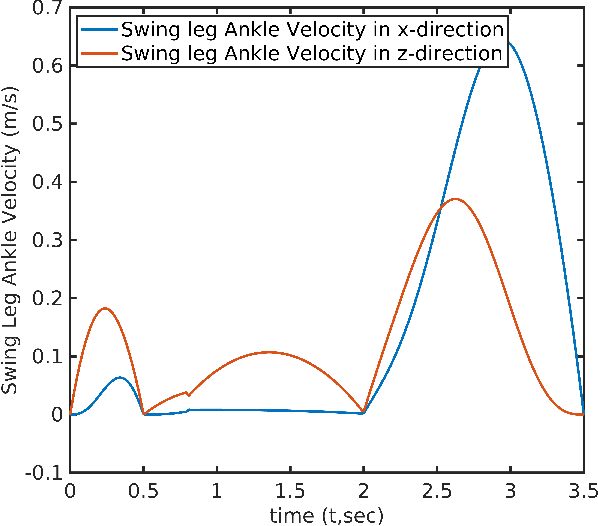
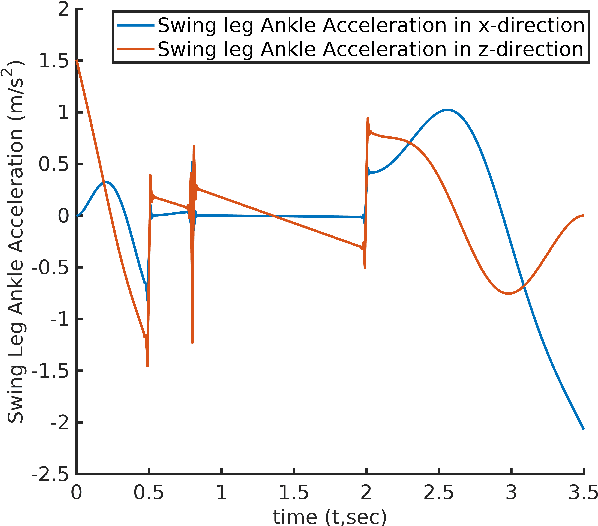
In this paper, a novel optimal technique for joint angles trajectory tracking control of a biped robot with toe foot is proposed. For the task of climbing stairs by a 9 link biped model, a cycloid trajectory for swing phase is proposed in such a way that the cycloid variables depend on the staircase dimensions. Zero Moment Point(ZMP) criteria is taken for satisfying stability constraint. This paper mainly can be divided into 4 steps: 1) Planning stable cycloid trajectory for initial step and subsequent step for climbing upstairs. 2) Inverse Kinematics using unsupervised artificial neural network with knot shifting procedure for jerk minimization. 3) Modeling Dynamics for Toe foot biped model using Lagrange Dynamics along with contact modeling using spring damper system , and finally 4) Real time joint angle trajectory tracking optimization using Temporal Quantized Lagrange Dynamics which takes inverse kinematics output from neural network as its inputs. Generated patterns have been simulated in MATLAB.