 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIgnorance is Bliss: Robust Control via Information Gating
Mar 10, 2023



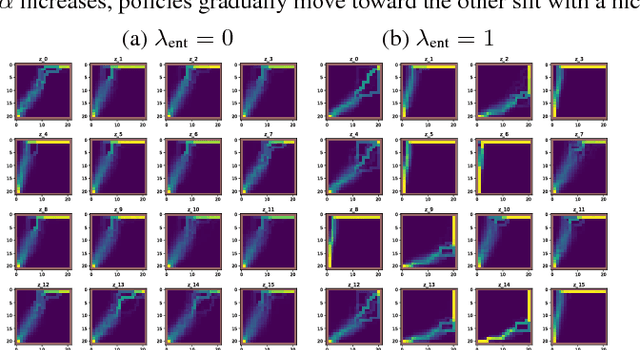
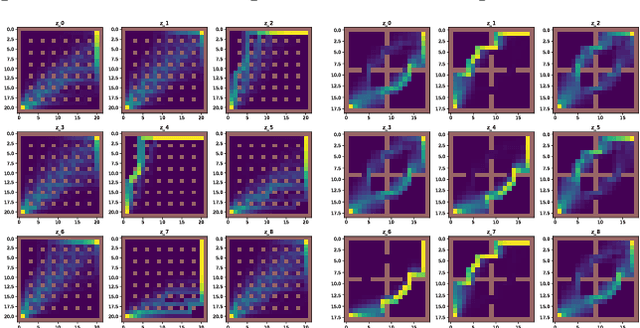
Informational parsimony -- i.e., using the minimal information required for a task, -- provides a useful inductive bias for learning representations that achieve better generalization by being robust to noise and spurious correlations. We propose information gating in the pixel space as a way to learn more parsimonious representations. Information gating works by learning masks that capture only the minimal information required to solve a given task. Intuitively, our models learn to identify which visual cues actually matter for a given task. We gate information using a differentiable parameterization of the signal-to-noise ratio, which can be applied to arbitrary values in a network, e.g.~masking out pixels at the input layer. We apply our approach, which we call InfoGating, to various objectives such as: multi-step forward and inverse dynamics, Q-learning, behavior cloning, and standard self-supervised tasks. Our experiments show that learning to identify and use minimal information can improve generalization in downstream tasks -- e.g., policies based on info-gated images are considerably more robust to distracting/irrelevant visual features.
Pretraining Representations for Data-Efficient Reinforcement Learning
Jun 09, 2021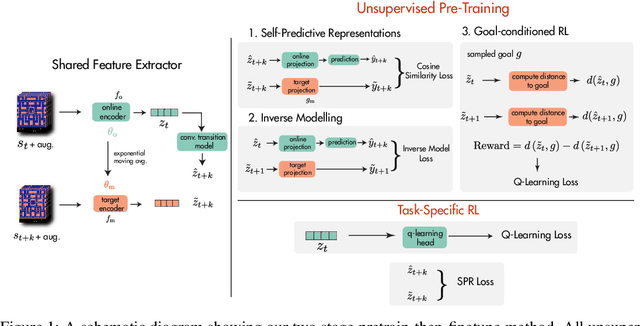
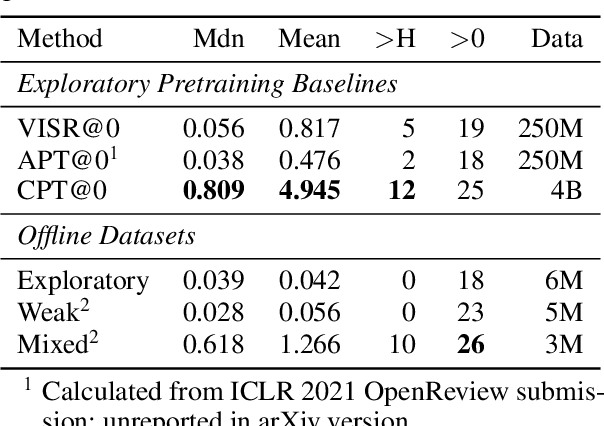
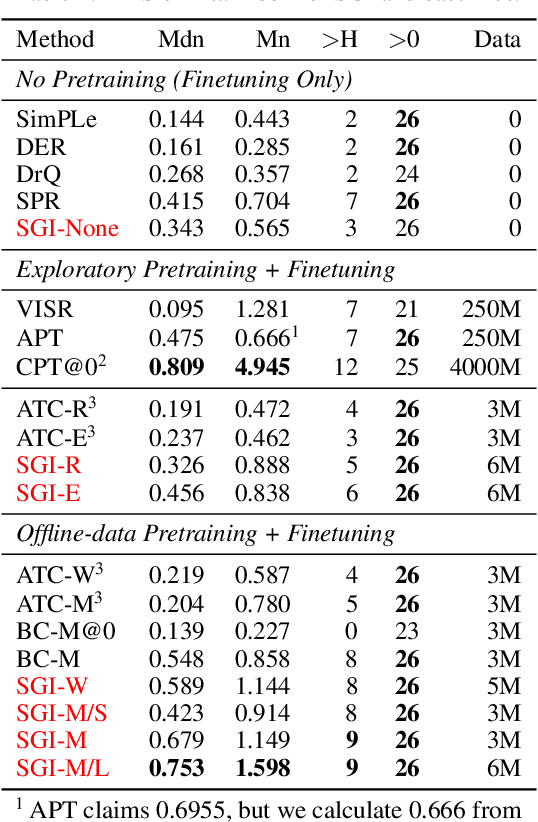
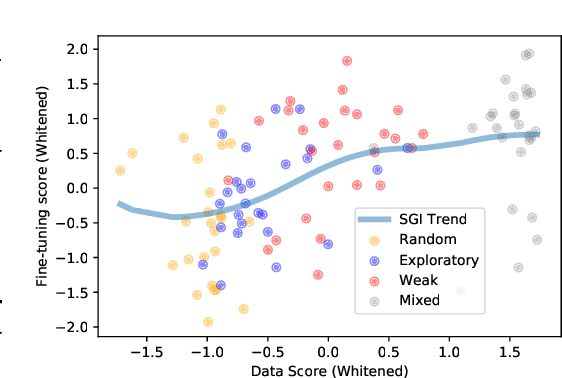
Data efficiency is a key challenge for deep reinforcement learning. We address this problem by using unlabeled data to pretrain an encoder which is then finetuned on a small amount of task-specific data. To encourage learning representations which capture diverse aspects of the underlying MDP, we employ a combination of latent dynamics modelling and unsupervised goal-conditioned RL. When limited to 100k steps of interaction on Atari games (equivalent to two hours of human experience), our approach significantly surpasses prior work combining offline representation pretraining with task-specific finetuning, and compares favourably with other pretraining methods that require orders of magnitude more data. Our approach shows particular promise when combined with larger models as well as more diverse, task-aligned observational data -- approaching human-level performance and data-efficiency on Atari in our best setting. We provide code associated with this work at https://github.com/mila-iqia/SGI.
Representation Learning with Video Deep InfoMax
Jul 28, 2020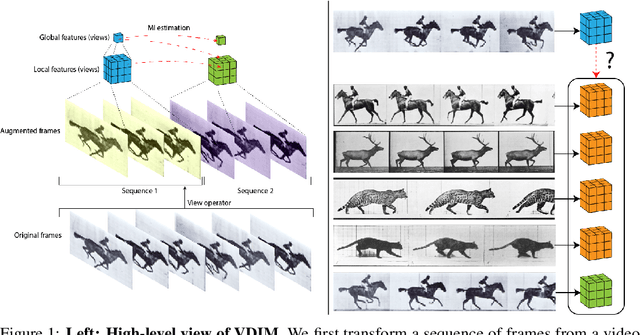
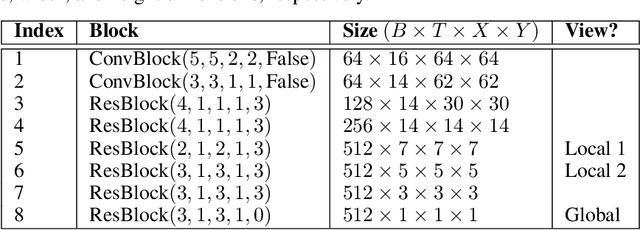
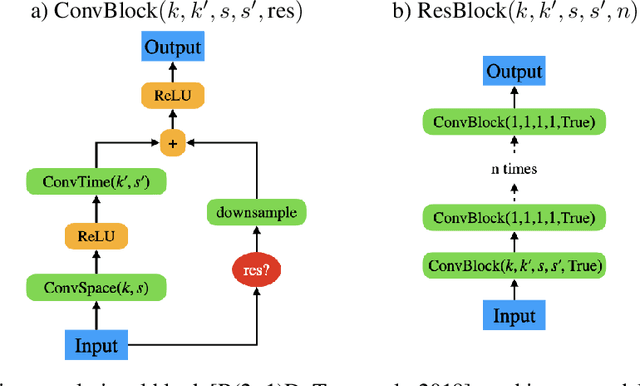
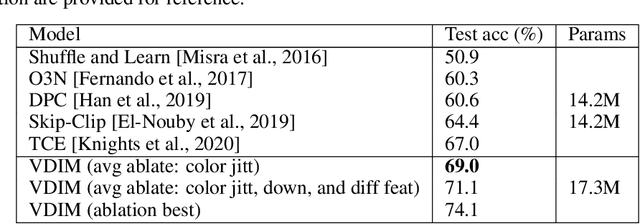
Self-supervised learning has made unsupervised pretraining relevant again for difficult computer vision tasks. The most effective self-supervised methods involve prediction tasks based on features extracted from diverse views of the data. DeepInfoMax (DIM) is a self-supervised method which leverages the internal structure of deep networks to construct such views, forming prediction tasks between local features which depend on small patches in an image and global features which depend on the whole image. In this paper, we extend DIM to the video domain by leveraging similar structure in spatio-temporal networks, producing a method we call Video Deep InfoMax(VDIM). We find that drawing views from both natural-rate sequences and temporally-downsampled sequences yields results on Kinetics-pretrained action recognition tasks which match or outperform prior state-of-the-art methods that use more costly large-time-scale transformer models. We also examine the effects of data augmentation and fine-tuning methods, accomplishingSoTA by a large margin when training only on the UCF-101 dataset.
Data-Efficient Reinforcement Learning with Momentum Predictive Representations
Jul 12, 2020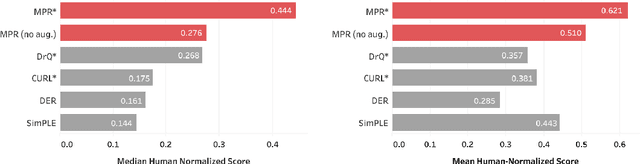
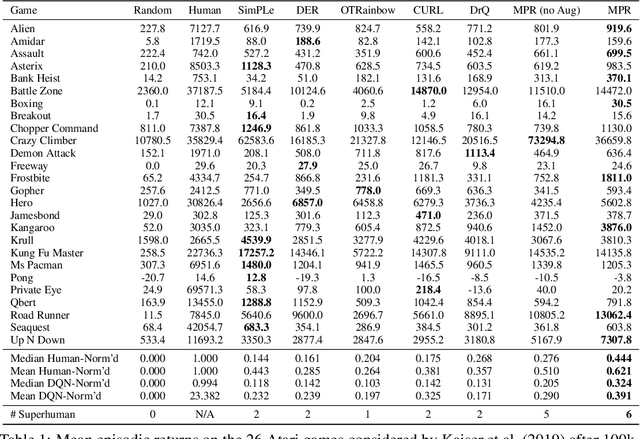
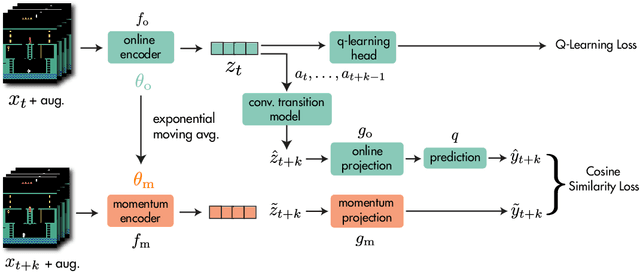

While deep reinforcement learning excels at solving tasks where large amounts of data can be collected through virtually unlimited interaction with the environment, learning from limited interaction remains a key challenge. We posit that an agent can learn more efficiently if we augment reward maximization with self-supervised objectives based on structure in its visual input and sequential interaction with the environment. Our method, Momentum Predictive Representations (MPR), trains an agent to predict its own latent state representations multiple steps into the future. We compute target representations for future states using an encoder which is an exponential moving average of the agent's parameters, and we make predictions using a learned transition model. On its own, this future prediction objective outperforms prior methods for sample-efficient deep RL from pixels. We further improve performance by adding data augmentation to the future prediction loss, which forces the agent's representations to be consistent across multiple views of an observation. Our full self-supervised objective, which combines future prediction and data augmentation, achieves a median human-normalized score of 0.444 on Atari in a setting limited to 100K steps of environment interaction, which is a 66% relative improvement over the previous state-of-the-art. Moreover, even in this limited data regime, MPR exceeds expert human scores on 6 out of 26 games.
Deep Reinforcement and InfoMax Learning
Jun 12, 2020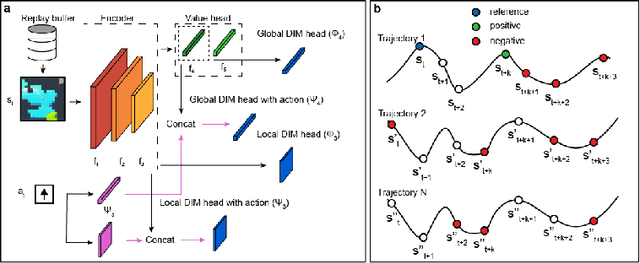
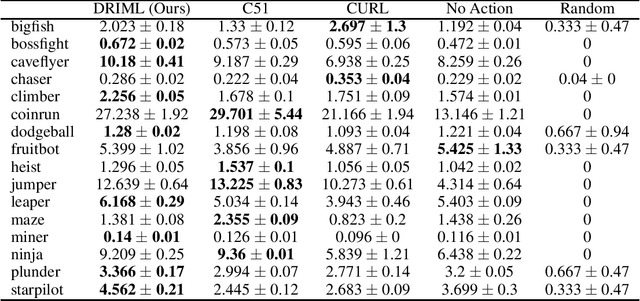
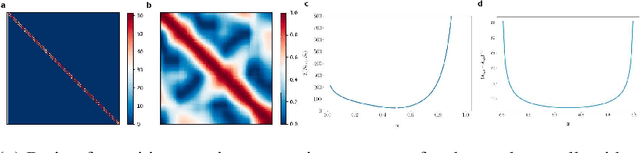

Our work is based on the hypothesis that a model-free agent whose representations are predictive of properties of future states (beyond expected rewards) will be more capable of solving and adapting to new RL problems. To test that hypothesis, we introduce an objective based on Deep InfoMax (DIM) which trains the agent to predict the future by maximizing the mutual information between its internal representation of successive timesteps. We provide an intuitive analysis of the convergence properties of our approach from the perspective of Markov chain mixing times and argue that convergence of the lower bound on mutual information is related to the inverse absolute spectral gap of the transition model. We test our approach in several synthetic settings, where it successfully learns representations that are predictive of the future. Finally, we augment C51, a strong RL baseline, with our temporal DIM objective and demonstrate improved performance on a continual learning task and on the recently introduced Procgen environment.
Learning Representations by Maximizing Mutual Information Across Views
Jun 03, 2019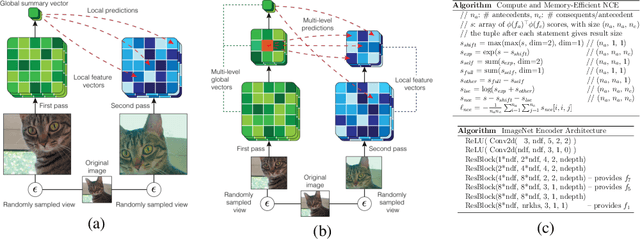


We propose an approach to self-supervised representation learning based on maximizing mutual information between features extracted from multiple views of a shared context. For example, a context could be an image from ImageNet, and multiple views of the context could be generated by repeatedly applying data augmentation to the image. Following this approach, we develop a new model which maximizes mutual information between features extracted at multiple scales from independently-augmented copies of each input. Our model significantly outperforms prior work on the tasks we consider. Most notably, it achieves over 60% accuracy on ImageNet using the standard linear evaluation protocol. This improves on prior results by over 4% (absolute). On Places205, using the representations learned on ImageNet, our model achieves 50% accuracy. This improves on prior results by 2% (absolute). When we extend our model to use mixture-based representations, segmentation behaviour emerges as a natural side-effect.
Learning Invariances for Policy Generalization
Sep 07, 2018
While recent progress has spawned very powerful machine learning systems, those agents remain extremely specialized and fail to transfer the knowledge they gain to similar yet unseen tasks. In this paper, we study a simple reinforcement learning problem and focus on learning policies that encode the proper invariances for generalization to different settings. We evaluate three potential methods for policy generalization: data augmentation, meta-learning and adversarial training. We find our data augmentation method to be effective, and study the potential of meta-learning and adversarial learning as alternative task-agnostic approaches. Keywords: reinforcement learning, generalization, data augmentation, meta-learning, adversarial learning.
VFunc: a Deep Generative Model for Functions
Jul 11, 2018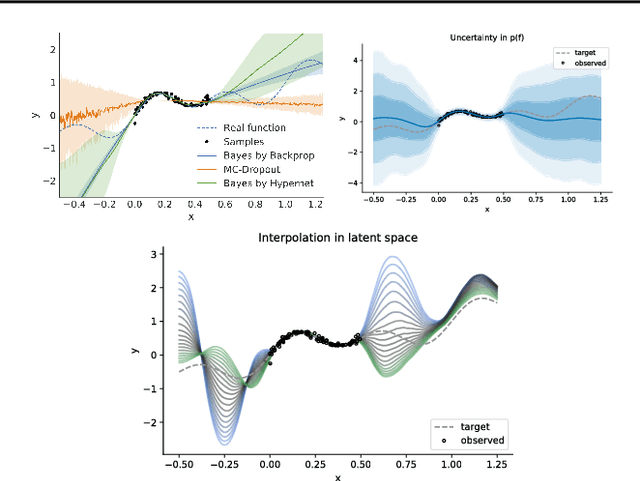

We introduce a deep generative model for functions. Our model provides a joint distribution p(f, z) over functions f and latent variables z which lets us efficiently sample from the marginal p(f) and maximize a variational lower bound on the entropy H(f). We can thus maximize objectives of the form E_{f~p(f)}[R(f)] + c*H(f), where R(f) denotes, e.g., a data log-likelihood term or an expected reward. Such objectives encompass Bayesian deep learning in function space, rather than parameter space, and Bayesian deep RL with representations of uncertainty that offer benefits over bootstrapping and parameter noise. In this short paper we describe our model, situate it in the context of prior work, and present proof-of-concept experiments for regression and RL.
Augmented CycleGAN: Learning Many-to-Many Mappings from Unpaired Data
Jun 18, 2018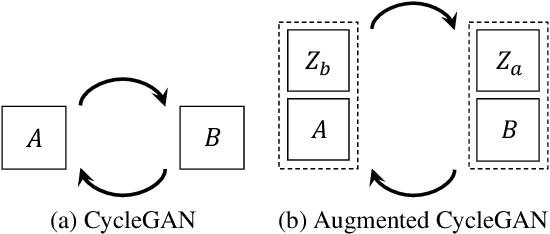

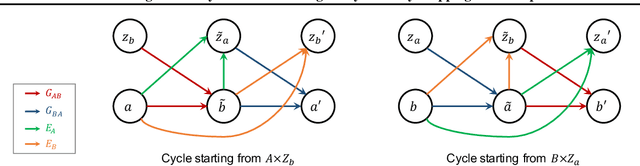

Learning inter-domain mappings from unpaired data can improve performance in structured prediction tasks, such as image segmentation, by reducing the need for paired data. CycleGAN was recently proposed for this problem, but critically assumes the underlying inter-domain mapping is approximately deterministic and one-to-one. This assumption renders the model ineffective for tasks requiring flexible, many-to-many mappings. We propose a new model, called Augmented CycleGAN, which learns many-to-many mappings between domains. We examine Augmented CycleGAN qualitatively and quantitatively on several image datasets.
Deep Reinforcement Learning that Matters
Nov 24, 2017
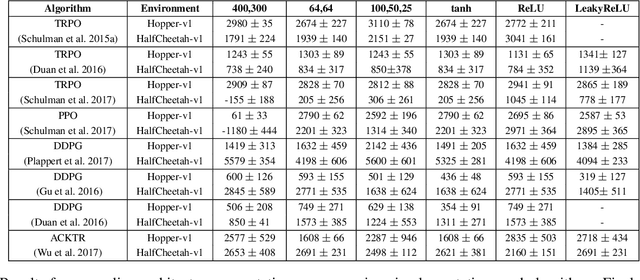


In recent years, significant progress has been made in solving challenging problems across various domains using deep reinforcement learning (RL). Reproducing existing work and accurately judging the improvements offered by novel methods is vital to sustaining this progress. Unfortunately, reproducing results for state-of-the-art deep RL methods is seldom straightforward. In particular, non-determinism in standard benchmark environments, combined with variance intrinsic to the methods, can make reported results tough to interpret. Without significance metrics and tighter standardization of experimental reporting, it is difficult to determine whether improvements over the prior state-of-the-art are meaningful. In this paper, we investigate challenges posed by reproducibility, proper experimental techniques, and reporting procedures. We illustrate the variability in reported metrics and results when comparing against common baselines and suggest guidelines to make future results in deep RL more reproducible. We aim to spur discussion about how to ensure continued progress in the field by minimizing wasted effort stemming from results that are non-reproducible and easily misinterpreted.