 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
Compositional Discrete Latent Code for High Fidelity, Productive Diffusion Models
Jul 16, 2025We argue that diffusion models' success in modeling complex distributions is, for the most part, coming from their input conditioning. This paper investigates the representation used to condition diffusion models from the perspective that ideal representations should improve sample fidelity, be easy to generate, and be compositional to allow out-of-training samples generation. We introduce Discrete Latent Code (DLC), an image representation derived from Simplicial Embeddings trained with a self-supervised learning objective. DLCs are sequences of discrete tokens, as opposed to the standard continuous image embeddings. They are easy to generate and their compositionality enables sampling of novel images beyond the training distribution. Diffusion models trained with DLCs have improved generation fidelity, establishing a new state-of-the-art for unconditional image generation on ImageNet. Additionally, we show that composing DLCs allows the image generator to produce out-of-distribution samples that coherently combine the semantics of images in diverse ways. Finally, we showcase how DLCs can enable text-to-image generation by leveraging large-scale pretrained language models. We efficiently finetune a text diffusion language model to generate DLCs that produce novel samples outside of the image generator training distribution.
Asynchronous RLHF: Faster and More Efficient Off-Policy RL for Language Models
Oct 23, 2024



The dominant paradigm for RLHF is online and on-policy RL: synchronously generating from the large language model (LLM) policy, labelling with a reward model, and learning using feedback on the LLM's own outputs. While performant, this paradigm is computationally inefficient. Inspired by classical deep RL literature, we propose separating generation and learning in RLHF. This enables asynchronous generation of new samples while simultaneously training on old samples, leading to faster training and more compute-optimal scaling. However, asynchronous training relies on an underexplored regime, online but off-policy RLHF: learning on samples from previous iterations of our model. To understand the challenges in this regime, we investigate a fundamental question: how much off-policyness can we tolerate for asynchronous training to speed up learning but maintain performance? Among several RLHF algorithms we tested, we find that online DPO is most robust to off-policy data, and robustness increases with the scale of the policy model. We study further compute optimizations for asynchronous RLHF but find that they come at a performance cost, giving rise to a trade-off. Finally, we verify the scalability of asynchronous RLHF by training LLaMA 3.1 8B on an instruction-following task 40% faster than a synchronous run while matching final performance.
The N+ Implementation Details of RLHF with PPO: A Case Study on TL;DR Summarization
Mar 24, 2024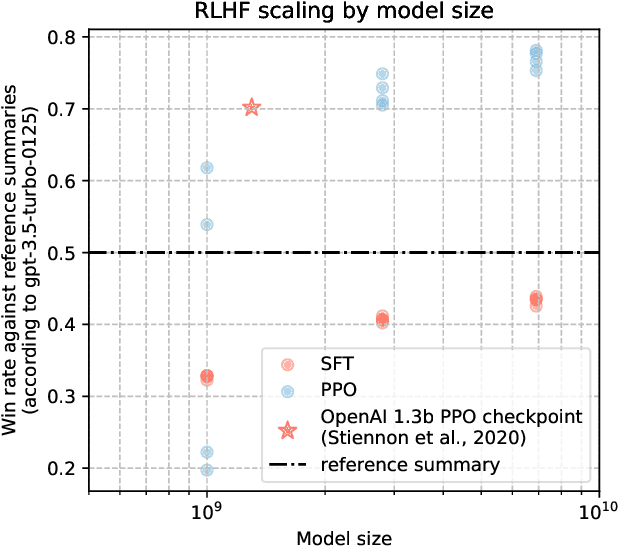
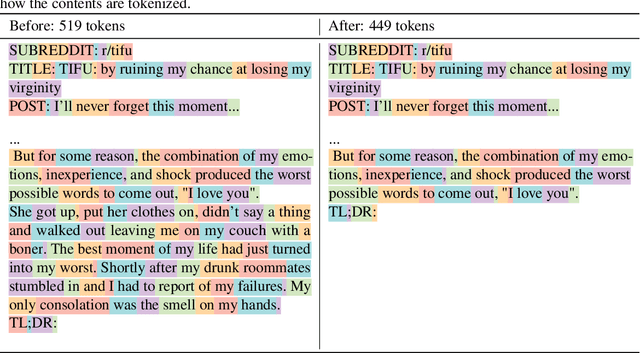
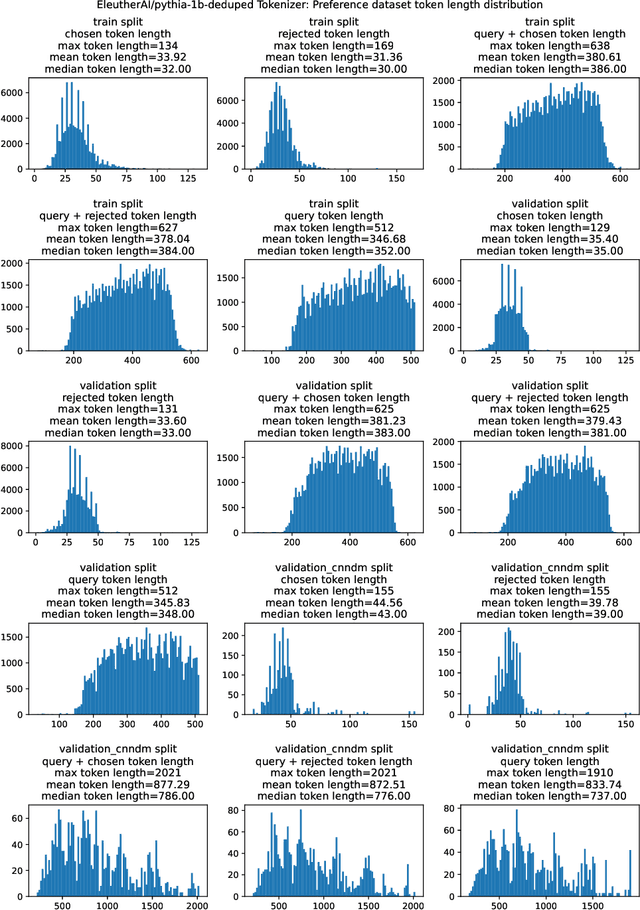

This work is the first to openly reproduce the Reinforcement Learning from Human Feedback (RLHF) scaling behaviors reported in OpenAI's seminal TL;DR summarization work. We create an RLHF pipeline from scratch, enumerate over 20 key implementation details, and share key insights during the reproduction. Our RLHF-trained Pythia models demonstrate significant gains in response quality that scale with model size, with our 2.8B, 6.9B models outperforming OpenAI's released 1.3B checkpoint. We publicly release the trained model checkpoints and code to facilitate further research and accelerate progress in the field (\url{https://github.com/vwxyzjn/summarize_from_feedback_details}).
Language Model Alignment with Elastic Reset
Dec 06, 2023Finetuning language models with reinforcement learning (RL), e.g. from human feedback (HF), is a prominent method for alignment. But optimizing against a reward model can improve on reward while degrading performance in other areas, a phenomenon known as reward hacking, alignment tax, or language drift. First, we argue that commonly-used test metrics are insufficient and instead measure how different algorithms tradeoff between reward and drift. The standard method modified the reward with a Kullback-Lieber (KL) penalty between the online and initial model. We propose Elastic Reset, a new algorithm that achieves higher reward with less drift without explicitly modifying the training objective. We periodically reset the online model to an exponentially moving average (EMA) of itself, then reset the EMA model to the initial model. Through the use of an EMA, our model recovers quickly after resets and achieves higher reward with less drift in the same number of steps. We demonstrate that fine-tuning language models with Elastic Reset leads to state-of-the-art performance on a small scale pivot-translation benchmark, outperforms all baselines in a medium-scale RLHF-like IMDB mock sentiment task and leads to a more performant and more aligned technical QA chatbot with LLaMA-7B. Code available at github.com/mnoukhov/elastic-reset.
Learning to Communicate using Contrastive Learning
Jul 03, 2023Communication is a powerful tool for coordination in multi-agent RL. But inducing an effective, common language is a difficult challenge, particularly in the decentralized setting. In this work, we introduce an alternative perspective where communicative messages sent between agents are considered as different incomplete views of the environment state. By examining the relationship between messages sent and received, we propose to learn to communicate using contrastive learning to maximize the mutual information between messages of a given trajectory. In communication-essential environments, our method outperforms previous work in both performance and learning speed. Using qualitative metrics and representation probing, we show that our method induces more symmetric communication and captures global state information from the environment. Overall, we show the power of contrastive learning and the importance of leveraging messages as encodings for effective communication.
Pretraining Representations for Data-Efficient Reinforcement Learning
Jun 09, 2021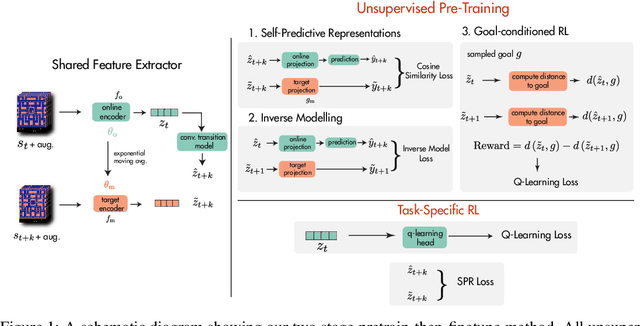
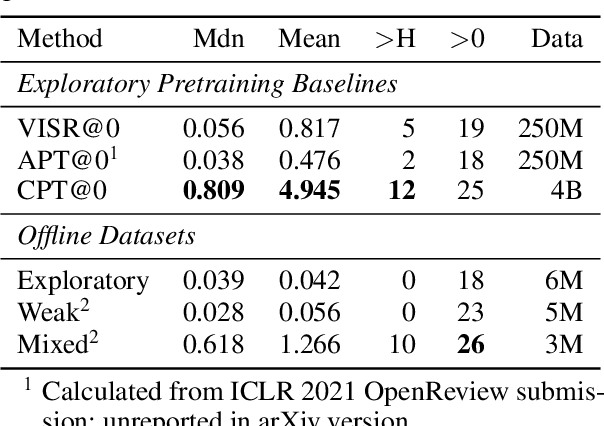
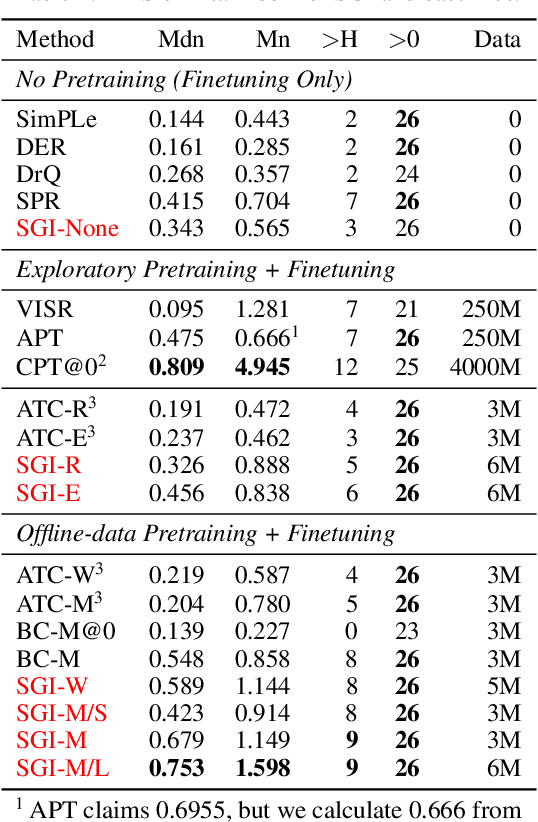
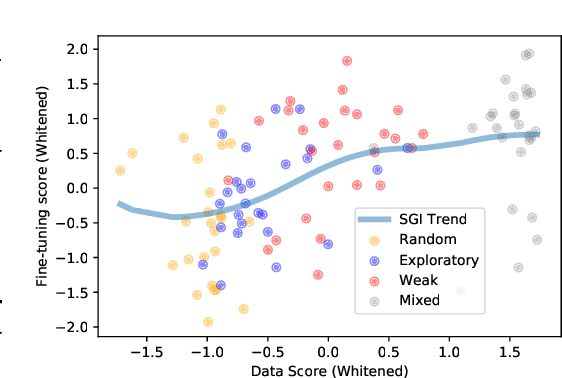
Data efficiency is a key challenge for deep reinforcement learning. We address this problem by using unlabeled data to pretrain an encoder which is then finetuned on a small amount of task-specific data. To encourage learning representations which capture diverse aspects of the underlying MDP, we employ a combination of latent dynamics modelling and unsupervised goal-conditioned RL. When limited to 100k steps of interaction on Atari games (equivalent to two hours of human experience), our approach significantly surpasses prior work combining offline representation pretraining with task-specific finetuning, and compares favourably with other pretraining methods that require orders of magnitude more data. Our approach shows particular promise when combined with larger models as well as more diverse, task-aligned observational data -- approaching human-level performance and data-efficiency on Atari in our best setting. We provide code associated with this work at https://github.com/mila-iqia/SGI.
Emergent Communication under Competition
Jan 25, 2021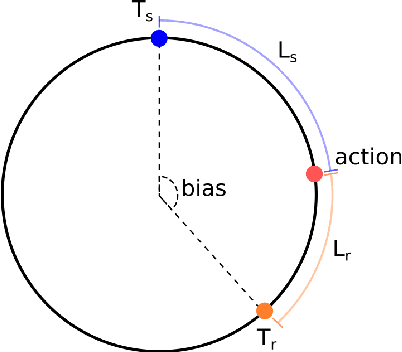
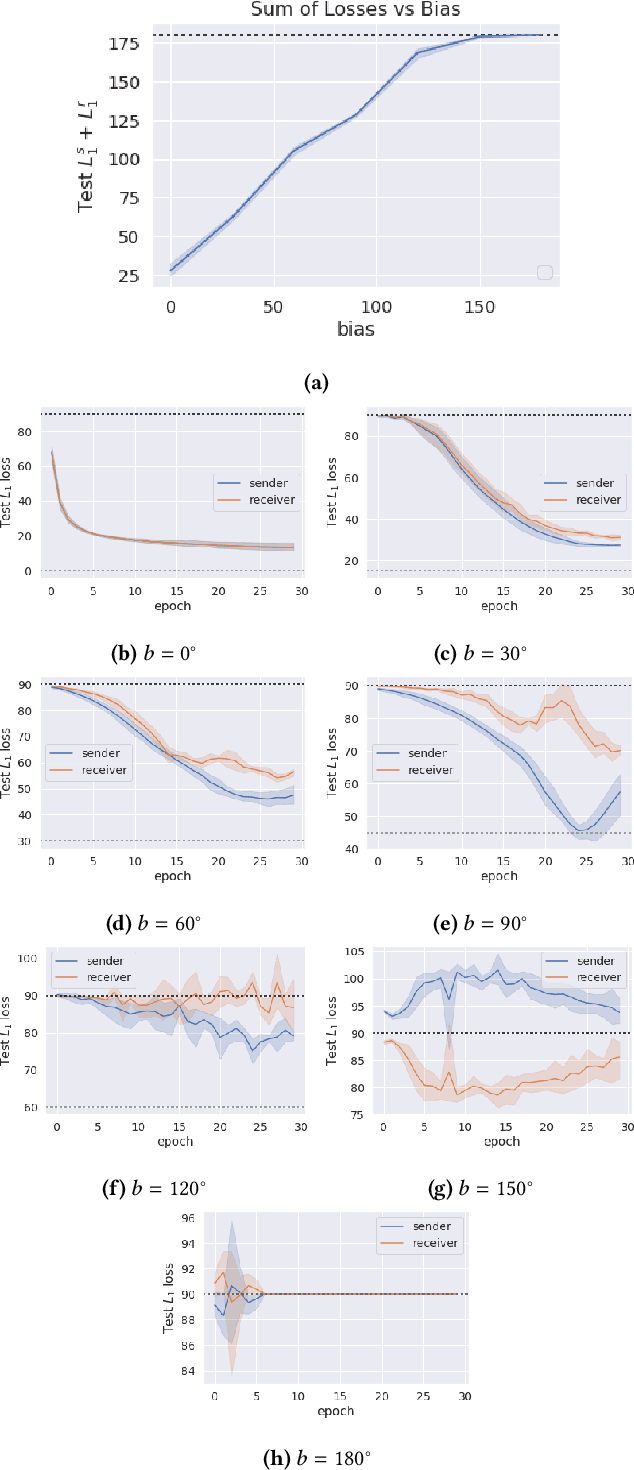
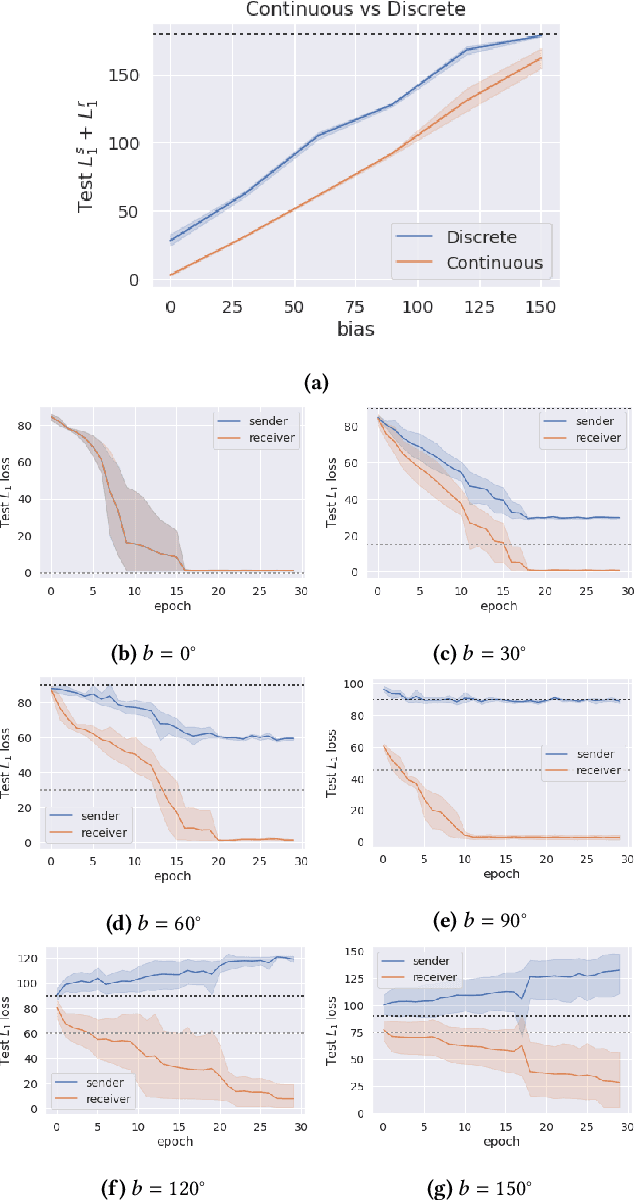
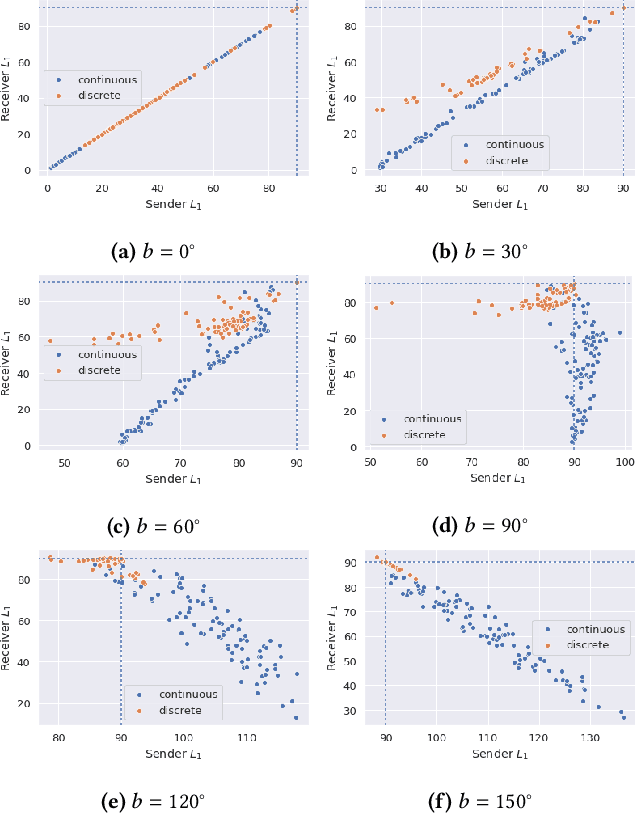
The literature in modern machine learning has only negative results for learning to communicate between competitive agents using standard RL. We introduce a modified sender-receiver game to study the spectrum of partially-competitive scenarios and show communication can indeed emerge in a competitive setting. We empirically demonstrate three key takeaways for future research. First, we show that communication is proportional to cooperation, and it can occur for partially competitive scenarios using standard learning algorithms. Second, we highlight the difference between communication and manipulation and extend previous metrics of communication to the competitive case. Third, we investigate the negotiation game where previous work failed to learn communication between independent agents (Cao et al., 2018). We show that, in this setting, both agents must benefit from communication for it to emerge; and, with a slight modification to the game, we demonstrate successful communication between competitive agents. We hope this work overturns misconceptions and inspires more research in competitive emergent communication.
Systematic Generalization: What Is Required and Can It Be Learned?
Nov 30, 2018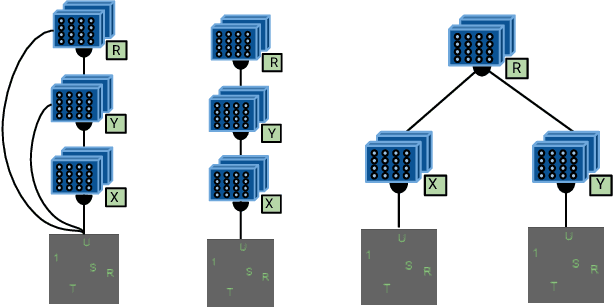
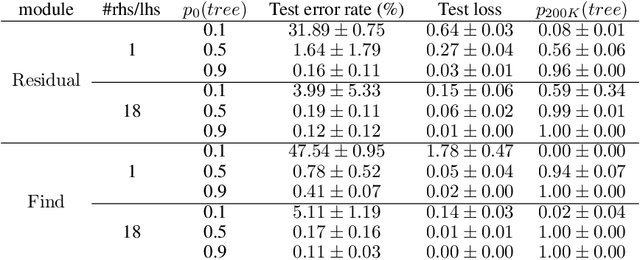

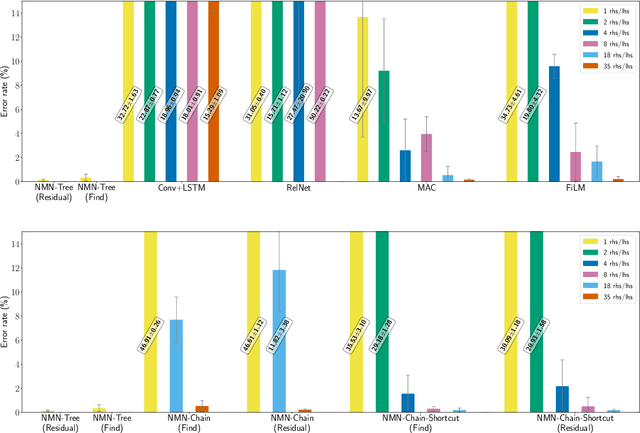
Numerous models for grounded language understanding have been recently proposed, including (i) generic models that can be easily adapted to any given task with little adaptation and (ii) intuitively appealing modular models that require background knowledge to be instantiated. We compare both types of models in how much they lend themselves to a particular form of systematic generalization. Using a synthetic VQA test, we evaluate which models are capable of reasoning about all possible object pairs after training on only a small subset of them. Our findings show that the generalization of modular models is much more systematic and that it is highly sensitive to the module layout, i.e. to how exactly the modules are connected. We furthermore investigate if modular models that generalize well could be made more end-to-end by learning their layout and parametrization. We find that end-to-end methods from prior work often learn a wrong layout and a spurious parametrization that do not facilitate systematic generalization. Our results suggest that, in addition to modularity, systematic generalization in language understanding may require explicit regularizers or priors.
Commonsense mining as knowledge base completion? A study on the impact of novelty
Apr 24, 2018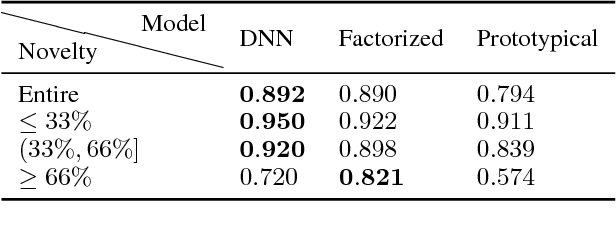
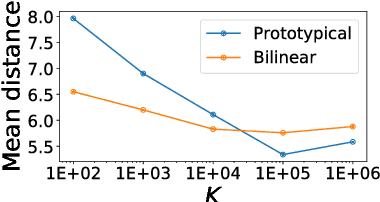


Commonsense knowledge bases such as ConceptNet represent knowledge in the form of relational triples. Inspired by the recent work by Li et al., we analyse if knowledge base completion models can be used to mine commonsense knowledge from raw text. We propose novelty of predicted triples with respect to the training set as an important factor in interpreting results. We critically analyse the difficulty of mining novel commonsense knowledge, and show that a simple baseline method outperforms the previous state of the art on predicting more novel.