Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe N+ Implementation Details of RLHF with PPO: A Case Study on TL;DR Summarization
Paper and Code
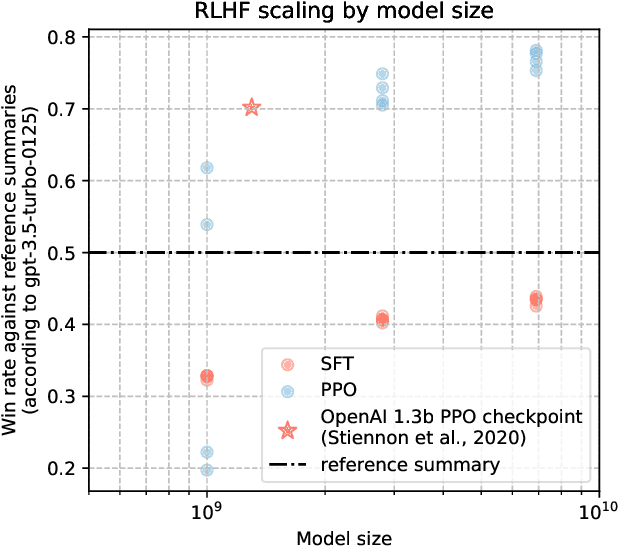
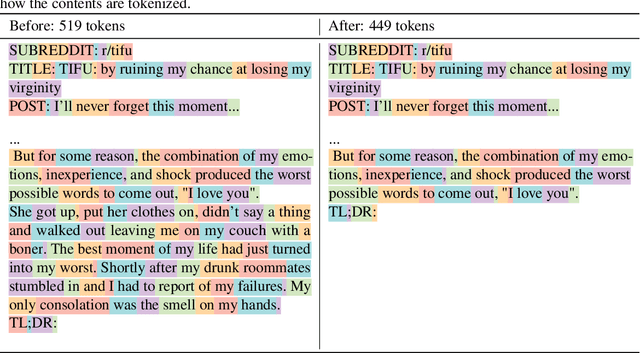
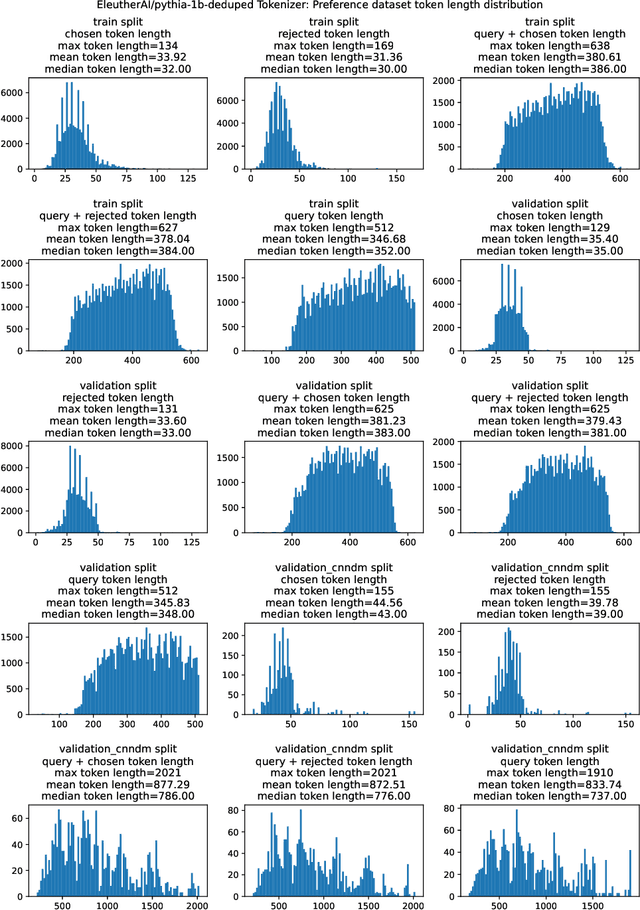

This work is the first to openly reproduce the Reinforcement Learning from Human Feedback (RLHF) scaling behaviors reported in OpenAI's seminal TL;DR summarization work. We create an RLHF pipeline from scratch, enumerate over 20 key implementation details, and share key insights during the reproduction. Our RLHF-trained Pythia models demonstrate significant gains in response quality that scale with model size, with our 2.8B, 6.9B models outperforming OpenAI's released 1.3B checkpoint. We publicly release the trained model checkpoints and code to facilitate further research and accelerate progress in the field (\url{https://github.com/vwxyzjn/summarize_from_feedback_details}).
View paper on