 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Voices: Generating A-Roll Video from Audio with Mirage
Jun 09, 2025



From professional filmmaking to user-generated content, creators and consumers have long recognized that the power of video depends on the harmonious integration of what we hear (the video's audio track) with what we see (the video's image sequence). Current approaches to video generation either ignore sound to focus on general-purpose but silent image sequence generation or address both visual and audio elements but focus on restricted application domains such as re-dubbing. We introduce Mirage, an audio-to-video foundation model that excels at generating realistic, expressive output imagery from scratch given an audio input. When integrated with existing methods for speech synthesis (text-to-speech, or TTS), Mirage results in compelling multimodal video. When trained on audio-video footage of people talking (A-roll) and conditioned on audio containing speech, Mirage generates video of people delivering a believable interpretation of the performance implicit in input audio. Our central technical contribution is a unified method for training self-attention-based audio-to-video generation models, either from scratch or given existing weights. This methodology allows Mirage to retain generality as an approach to audio-to-video generation while producing outputs of superior subjective quality to methods that incorporate audio-specific architectures or loss components specific to people, speech, or details of how images or audio are captured. We encourage readers to watch and listen to the results of Mirage for themselves (see paper and comments for links).
Learning Representations by Maximizing Mutual Information Across Views
Jun 03, 2019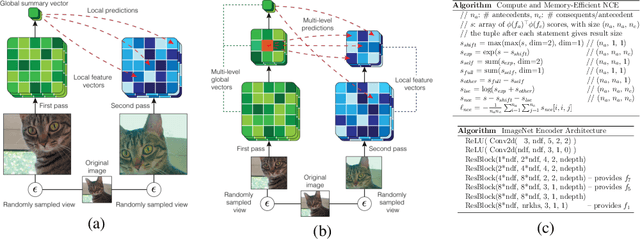


We propose an approach to self-supervised representation learning based on maximizing mutual information between features extracted from multiple views of a shared context. For example, a context could be an image from ImageNet, and multiple views of the context could be generated by repeatedly applying data augmentation to the image. Following this approach, we develop a new model which maximizes mutual information between features extracted at multiple scales from independently-augmented copies of each input. Our model significantly outperforms prior work on the tasks we consider. Most notably, it achieves over 60% accuracy on ImageNet using the standard linear evaluation protocol. This improves on prior results by over 4% (absolute). On Places205, using the representations learned on ImageNet, our model achieves 50% accuracy. This improves on prior results by 2% (absolute). When we extend our model to use mixture-based representations, segmentation behaviour emerges as a natural side-effect.