 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Policy Optimization in RL with Variance Regularizaton
Dec 29, 2022



Learning policies from fixed offline datasets is a key challenge to scale up reinforcement learning (RL) algorithms towards practical applications. This is often because off-policy RL algorithms suffer from distributional shift, due to mismatch between dataset and the target policy, leading to high variance and over-estimation of value functions. In this work, we propose variance regularization for offline RL algorithms, using stationary distribution corrections. We show that by using Fenchel duality, we can avoid double sampling issues for computing the gradient of the variance regularizer. The proposed algorithm for offline variance regularization (OVAR) can be used to augment any existing offline policy optimization algorithms. We show that the regularizer leads to a lower bound to the offline policy optimization objective, which can help avoid over-estimation errors, and explains the benefits of our approach across a range of continuous control domains when compared to existing state-of-the-art algorithms.
Representation Learning in Deep RL via Discrete Information Bottleneck
Dec 28, 2022


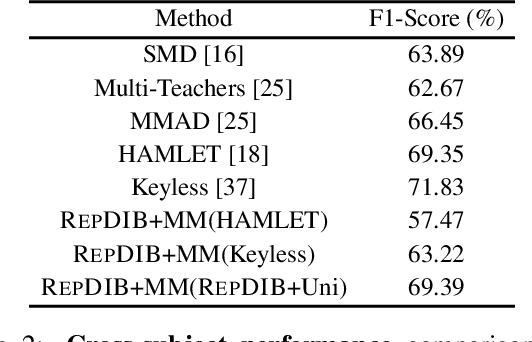
Several self-supervised representation learning methods have been proposed for reinforcement learning (RL) with rich observations. For real-world applications of RL, recovering underlying latent states is crucial, particularly when sensory inputs contain irrelevant and exogenous information. In this work, we study how information bottlenecks can be used to construct latent states efficiently in the presence of task-irrelevant information. We propose architectures that utilize variational and discrete information bottlenecks, coined as RepDIB, to learn structured factorized representations. Exploiting the expressiveness bought by factorized representations, we introduce a simple, yet effective, bottleneck that can be integrated with any existing self-supervised objective for RL. We demonstrate this across several online and offline RL benchmarks, along with a real robot arm task, where we find that compressed representations with RepDIB can lead to strong performance improvements, as the learned bottlenecks help predict only the relevant state while ignoring irrelevant information.
Single-Shot Pruning for Offline Reinforcement Learning
Dec 31, 2021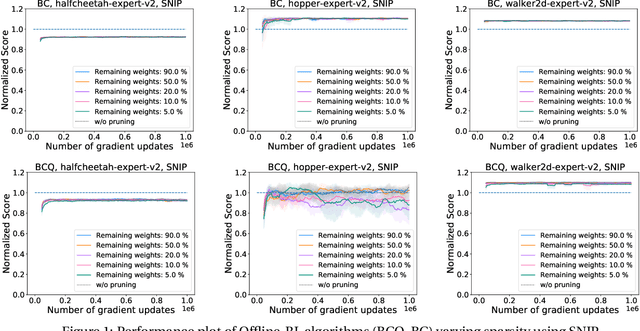
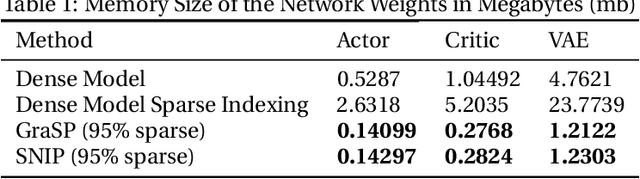
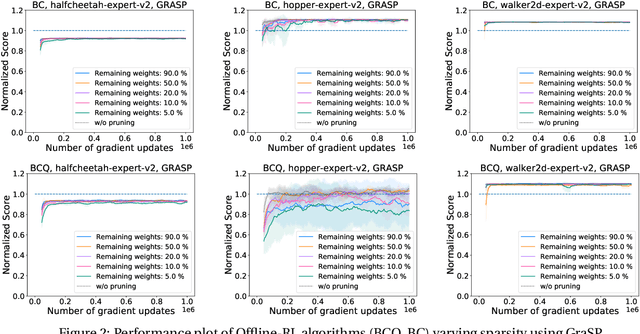
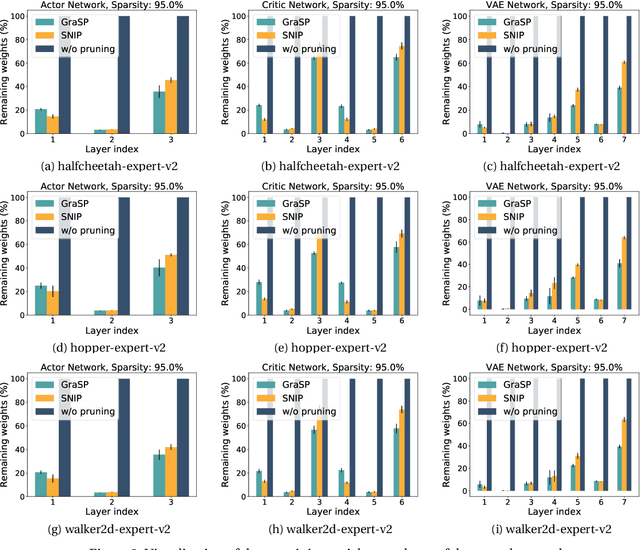
Deep Reinforcement Learning (RL) is a powerful framework for solving complex real-world problems. Large neural networks employed in the framework are traditionally associated with better generalization capabilities, but their increased size entails the drawbacks of extensive training duration, substantial hardware resources, and longer inference times. One way to tackle this problem is to prune neural networks leaving only the necessary parameters. State-of-the-art concurrent pruning techniques for imposing sparsity perform demonstrably well in applications where data distributions are fixed. However, they have not yet been substantially explored in the context of RL. We close the gap between RL and single-shot pruning techniques and present a general pruning approach to the Offline RL. We leverage a fixed dataset to prune neural networks before the start of RL training. We then run experiments varying the network sparsity level and evaluating the validity of pruning at initialization techniques in continuous control tasks. Our results show that with 95% of the network weights pruned, Offline-RL algorithms can still retain performance in the majority of our experiments. To the best of our knowledge, no prior work utilizing pruning in RL retained performance at such high levels of sparsity. Moreover, pruning at initialization techniques can be easily integrated into any existing Offline-RL algorithms without changing the learning objective.
Importance of Empirical Sample Complexity Analysis for Offline Reinforcement Learning
Dec 31, 2021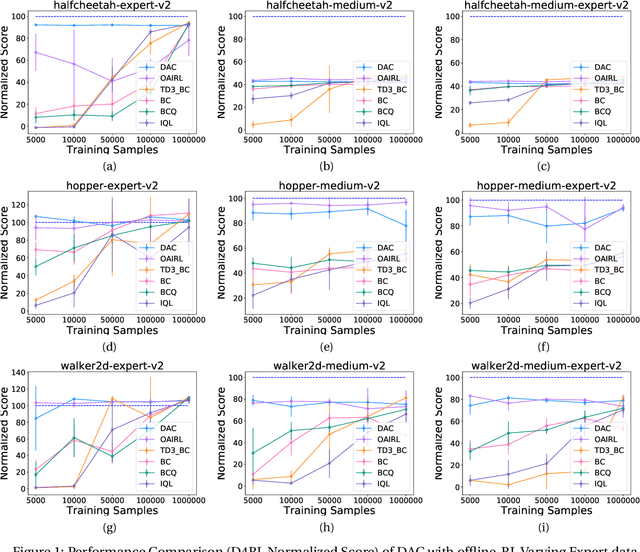
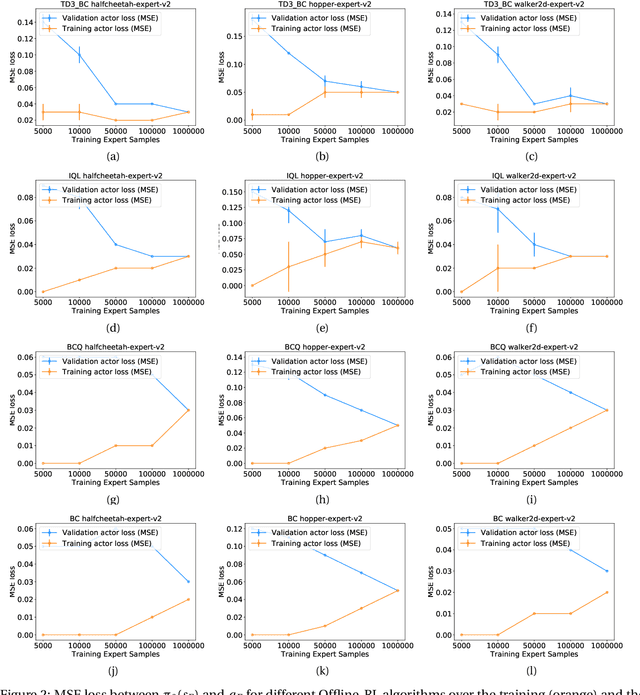
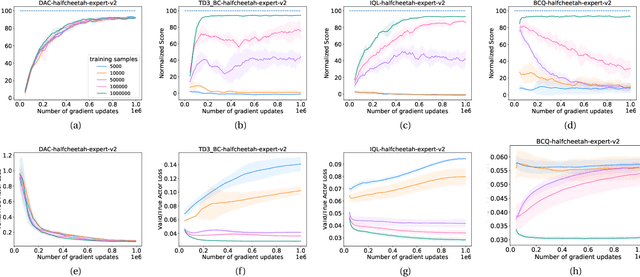
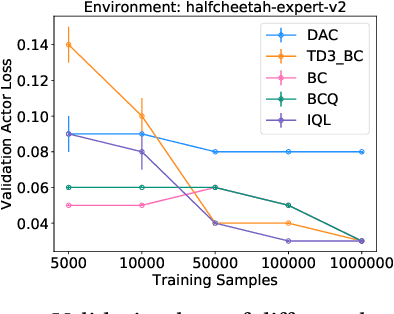
We hypothesize that empirically studying the sample complexity of offline reinforcement learning (RL) is crucial for the practical applications of RL in the real world. Several recent works have demonstrated the ability to learn policies directly from offline data. In this work, we ask the question of the dependency on the number of samples for learning from offline data. Our objective is to emphasize that studying sample complexity for offline RL is important, and is an indicator of the usefulness of existing offline algorithms. We propose an evaluation approach for sample complexity analysis of offline RL.
Off-Policy Adversarial Inverse Reinforcement Learning
May 03, 2020
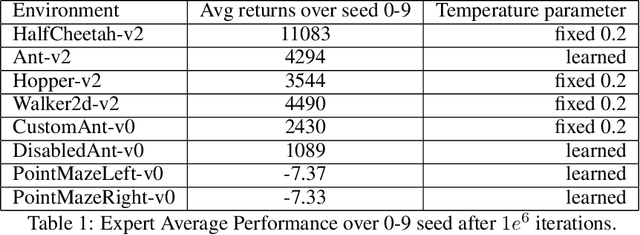
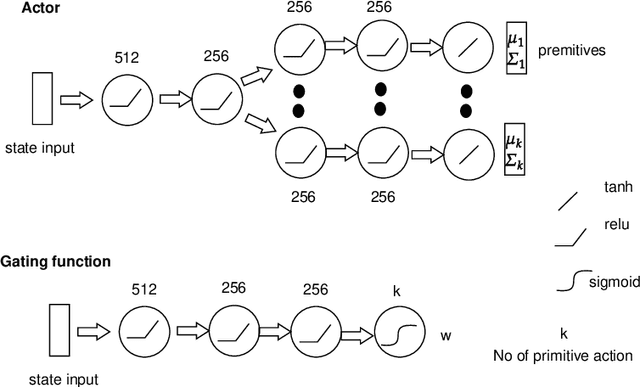
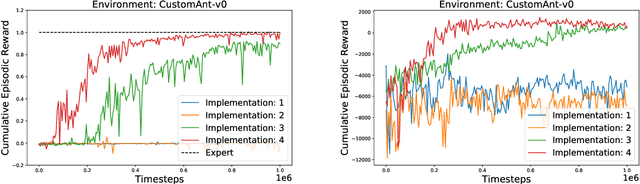
Adversarial Imitation Learning (AIL) is a class of algorithms in Reinforcement learning (RL), which tries to imitate an expert without taking any reward from the environment and does not provide expert behavior directly to the policy training. Rather, an agent learns a policy distribution that minimizes the difference from expert behavior in an adversarial setting. Adversarial Inverse Reinforcement Learning (AIRL) leverages the idea of AIL, integrates a reward function approximation along with learning the policy, and shows the utility of IRL in the transfer learning setting. But the reward function approximator that enables transfer learning does not perform well in imitation tasks. We propose an Off-Policy Adversarial Inverse Reinforcement Learning (Off-policy-AIRL) algorithm which is sample efficient as well as gives good imitation performance compared to the state-of-the-art AIL algorithm in the continuous control tasks. For the same reward function approximator, we show the utility of learning our algorithm over AIL by using the learned reward function to retrain the policy over a task under significant variation where expert demonstrations are absent.
Doubly Robust Off-Policy Actor-Critic Algorithms for Reinforcement Learning
Dec 11, 2019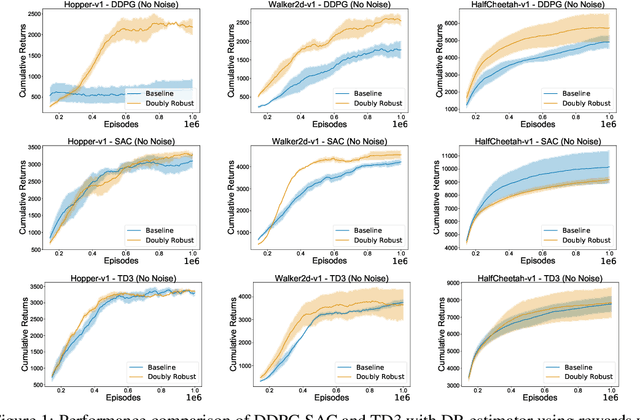
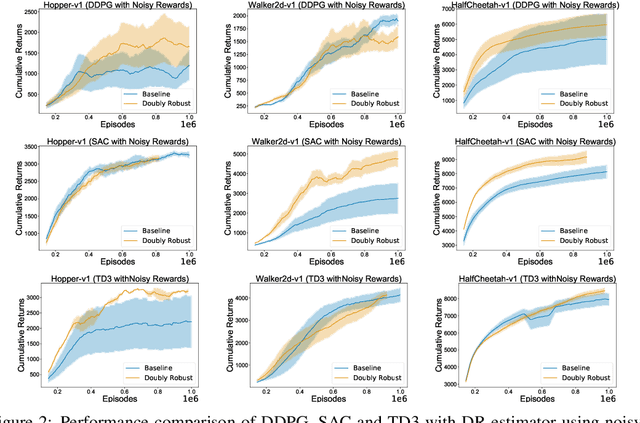
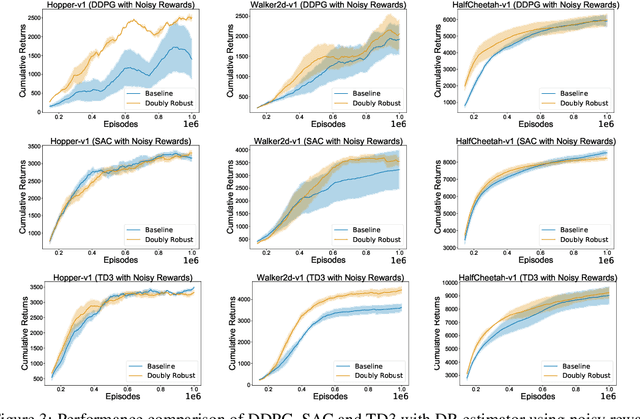
We study the problem of off-policy critic evaluation in several variants of value-based off-policy actor-critic algorithms. Off-policy actor-critic algorithms require an off-policy critic evaluation step, to estimate the value of the new policy after every policy gradient update. Despite enormous success of off-policy policy gradients on control tasks, existing general methods suffer from high variance and instability, partly because the policy improvement depends on gradient of the estimated value function. In this work, we present a new way of off-policy policy evaluation in actor-critic, based on the doubly robust estimators. We extend the doubly robust estimator from off-policy policy evaluation (OPE) to actor-critic algorithms that consist of a reward estimator performance model. We find that doubly robust estimation of the critic can significantly improve performance in continuous control tasks. Furthermore, in cases where the reward function is stochastic that can lead to high variance, doubly robust critic estimation can improve performance under corrupted, stochastic reward signals, indicating its usefulness for robust and safe reinforcement learning.