Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImportance of Empirical Sample Complexity Analysis for Offline Reinforcement Learning
Paper and Code
Dec 31, 2021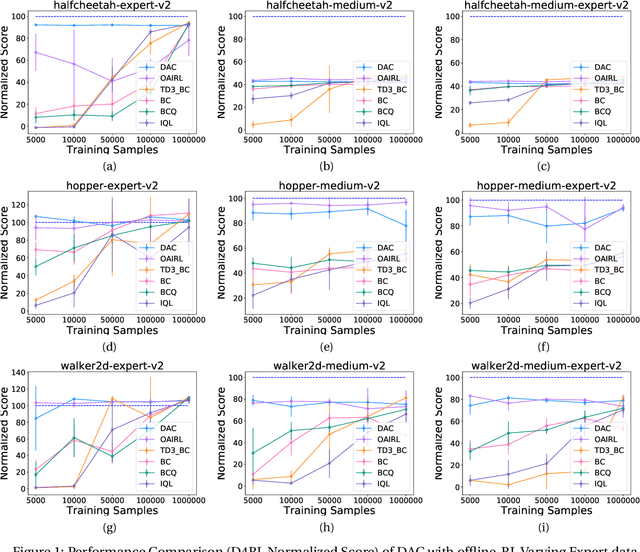
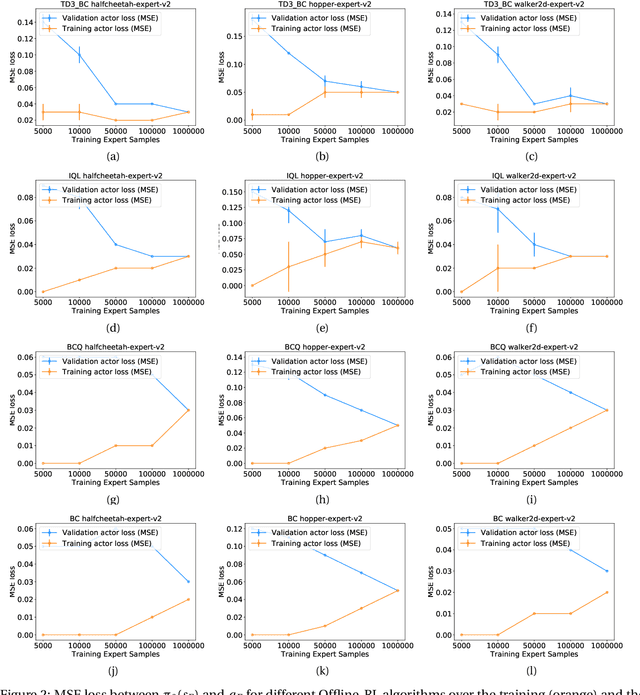
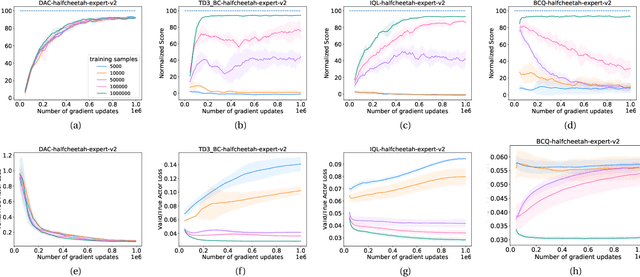
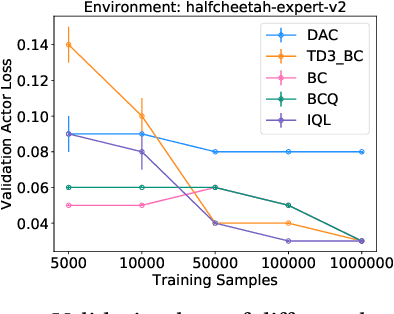
We hypothesize that empirically studying the sample complexity of offline reinforcement learning (RL) is crucial for the practical applications of RL in the real world. Several recent works have demonstrated the ability to learn policies directly from offline data. In this work, we ask the question of the dependency on the number of samples for learning from offline data. Our objective is to emphasize that studying sample complexity for offline RL is important, and is an indicator of the usefulness of existing offline algorithms. We propose an evaluation approach for sample complexity analysis of offline RL.
View paper on