 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deeper Look at Discounting Mismatch in Actor-Critic Algorithms
Paper and Code

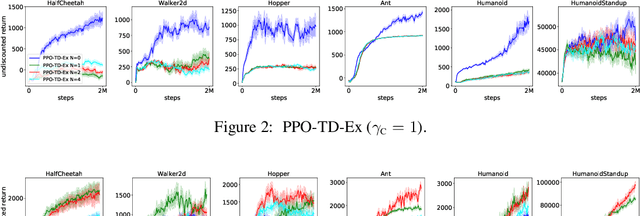
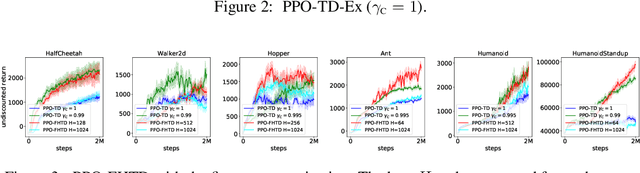

We investigate the discounting mismatch in actor-critic algorithm implementations from a representation learning perspective. Theoretically, actor-critic algorithms usually have discounting for both actor and critic, i.e., there is a $\gamma^t$ term in the actor update for the transition observed at time $t$ in a trajectory and the critic is a discounted value function. Practitioners, however, usually ignore the discounting ($\gamma^t$) for the actor while using a discounted critic. We investigate this mismatch in two scenarios. In the first scenario, we consider optimizing an undiscounted objective $(\gamma = 1)$ where $\gamma^t$ disappears naturally $(1^t = 1)$. We then propose to interpret the discounting in critic in terms of a bias-variance-representation trade-off and provide supporting empirical results. In the second scenario, we consider optimizing a discounted objective ($\gamma < 1$) and propose to interpret the omission of the discounting in the actor update from an auxiliary task perspective and provide supporting empirical results.