 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Reward Architecture for Reinforcement Learning
Nov 28, 2017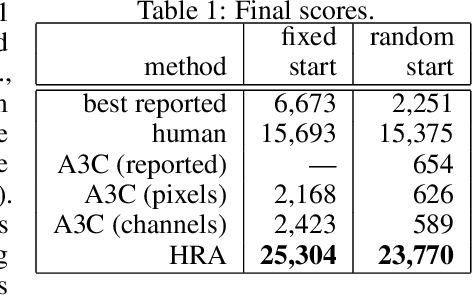
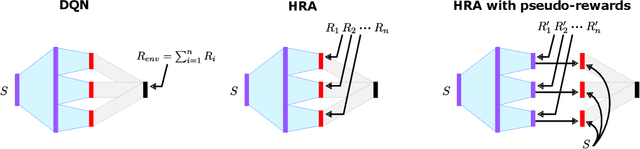
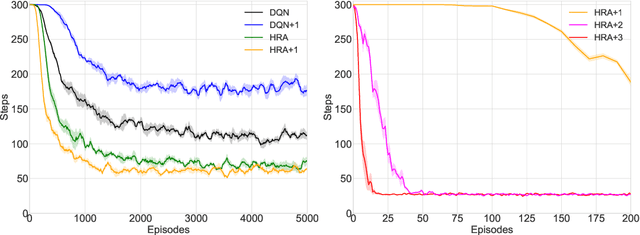
One of the main challenges in reinforcement learning (RL) is generalisation. In typical deep RL methods this is achieved by approximating the optimal value function with a low-dimensional representation using a deep network. While this approach works well in many domains, in domains where the optimal value function cannot easily be reduced to a low-dimensional representation, learning can be very slow and unstable. This paper contributes towards tackling such challenging domains, by proposing a new method, called Hybrid Reward Architecture (HRA). HRA takes as input a decomposed reward function and learns a separate value function for each component reward function. Because each component typically only depends on a subset of all features, the corresponding value function can be approximated more easily by a low-dimensional representation, enabling more effective learning. We demonstrate HRA on a toy-problem and the Atari game Ms. Pac-Man, where HRA achieves above-human performance.
The parametrized probabilistic finite-state transducer probe game player fingerprint model
Jan 29, 2014



Fingerprinting operators generate functional signatures of game players and are useful for their automated analysis independent of representation or encoding. The theory for a fingerprinting operator which returns the length-weighted probability of a given move pair occurring from playing the investigated agent against a general parametrized probabilistic finite-state transducer (PFT) is developed, applicable to arbitrary iterated games. Results for the distinguishing power of the 1-state opponent model, uniform approximability of fingerprints of arbitrary players, analyticity and Lipschitz continuity of fingerprints for logically possible players, and equicontinuity of the fingerprints of bounded-state probabilistic transducers are derived. Algorithms for the efficient computation of special instances are given; the shortcomings of a previous model, strictly generalized here from a simple projection of the new model, are explained in terms of regularity condition violations, and the extra power and functional niceness of the new fingerprints demonstrated. The 2-state deterministic finite-state transducers (DFTs) are fingerprinted and pairwise distances computed; using this the structure of DFTs in strategy space is elucidated.
* 17 pages, 35 figures