 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Exposure Bias Matters: An Imitation Learning Perspective of Error Accumulation in Language Generation
Apr 03, 2022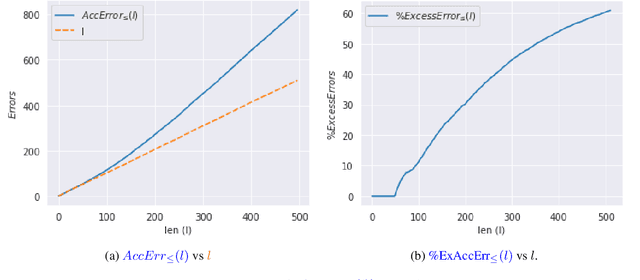
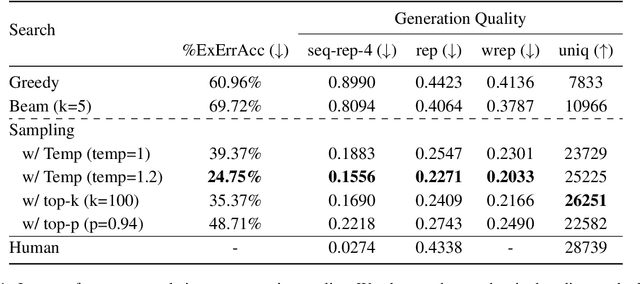
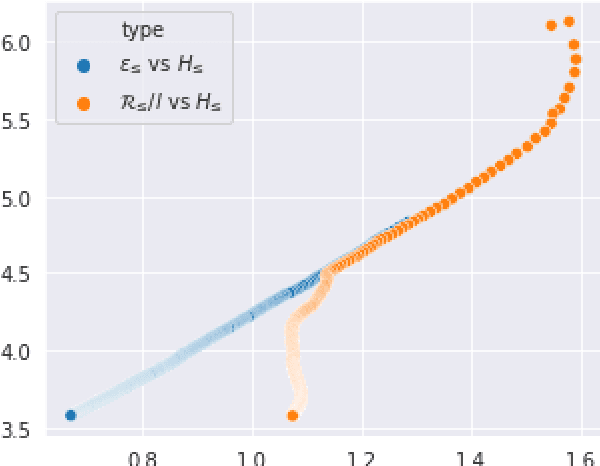
Current language generation models suffer from issues such as repetition, incoherence, and hallucinations. An often-repeated hypothesis is that this brittleness of generation models is caused by the training and the generation procedure mismatch, also referred to as exposure bias. In this paper, we verify this hypothesis by analyzing exposure bias from an imitation learning perspective. We show that exposure bias leads to an accumulation of errors, analyze why perplexity fails to capture this accumulation, and empirically show that this accumulation results in poor generation quality. Source code to reproduce these experiments is available at https://github.com/kushalarora/quantifying_exposure_bias
SLAPS: Self-Supervision Improves Structure Learning for Graph Neural Networks
Feb 09, 2021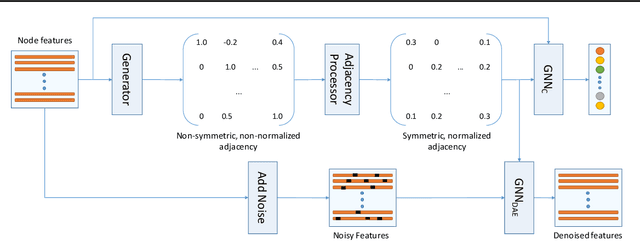
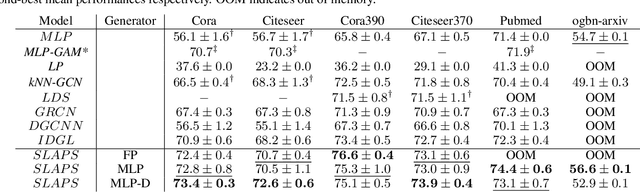
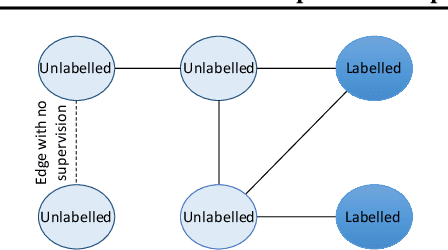
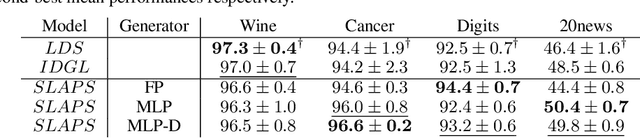
Graph neural networks (GNNs) work well when the graph structure is provided. However, this structure may not always be available in real-world applications. One solution to this problem is to infer a task-specific latent structure and then apply a GNN to the inferred graph. Unfortunately, the space of possible graph structures grows super-exponentially with the number of nodes and so the task-specific supervision may be insufficient for learning both the structure and the GNN parameters. In this work, we propose the Simultaneous Learning of Adjacency and GNN Parameters with Self-supervision, or SLAPS, a method that provides more supervision for inferring a graph structure through self-supervision. A comprehensive experimental study demonstrates that SLAPS scales to large graphs with hundreds of thousands of nodes and outperforms several models that have been proposed to learn a task-specific graph structure on established benchmarks.
Diverse Keyphrase Generation with Neural Unlikelihood Training
Oct 15, 2020
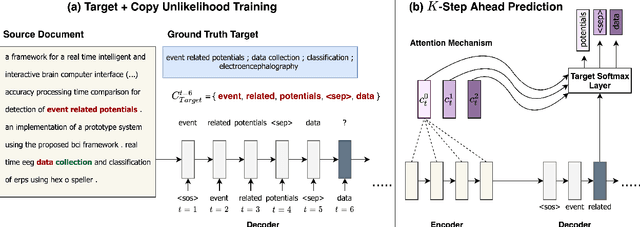

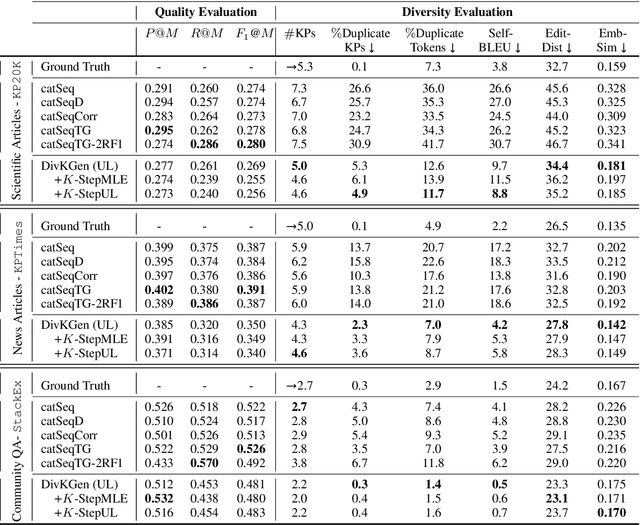
In this paper, we study sequence-to-sequence (S2S) keyphrase generation models from the perspective of diversity. Recent advances in neural natural language generation have made possible remarkable progress on the task of keyphrase generation, demonstrated through improvements on quality metrics such as F1-score. However, the importance of diversity in keyphrase generation has been largely ignored. We first analyze the extent of information redundancy present in the outputs generated by a baseline model trained using maximum likelihood estimation (MLE). Our findings show that repetition of keyphrases is a major issue with MLE training. To alleviate this issue, we adopt neural unlikelihood (UL) objective for training the S2S model. Our version of UL training operates at (1) the target token level to discourage the generation of repeating tokens; (2) the copy token level to avoid copying repetitive tokens from the source text. Further, to encourage better model planning during the decoding process, we incorporate K-step ahead token prediction objective that computes both MLE and UL losses on future tokens as well. Through extensive experiments on datasets from three different domains we demonstrate that the proposed approach attains considerably large diversity gains, while maintaining competitive output quality.
A Study of State Aliasing in Structured Prediction with RNNs
Jun 21, 2019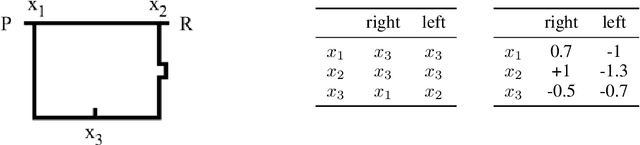
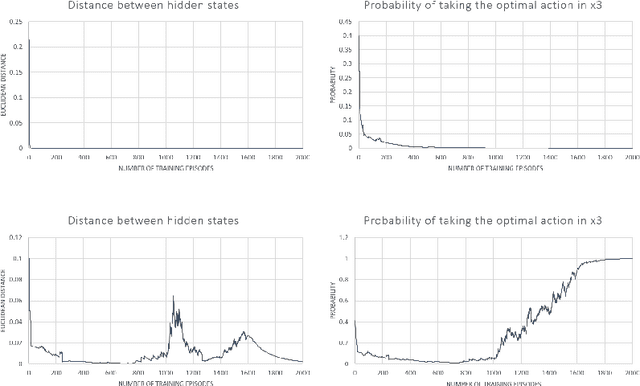
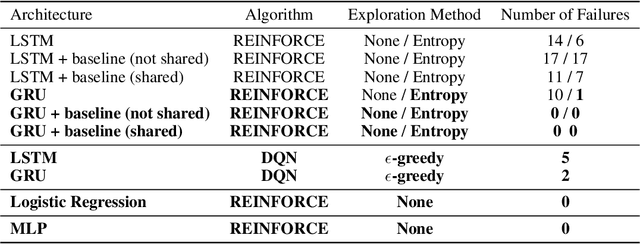
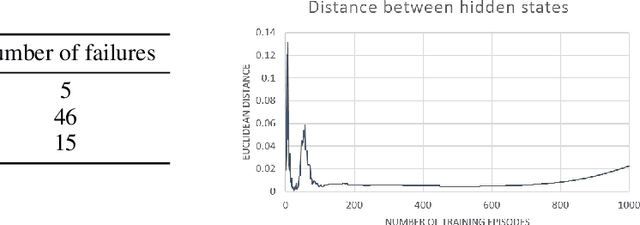
End-to-end reinforcement learning agents learn a state representation and a policy at the same time. Recurrent neural networks (RNNs) have been trained successfully as reinforcement learning agents in settings like dialogue that require structured prediction. In this paper, we investigate the representations learned by RNN-based agents when trained with both policy gradient and value-based methods. We show through extensive experiments and analysis that, when trained with policy gradient, recurrent neural networks often fail to learn a state representation that leads to an optimal policy in settings where the same action should be taken at different states. To explain this failure, we highlight the problem of state aliasing, which entails conflating two or more distinct states in the representation space. We demonstrate that state aliasing occurs when several states share the same optimal action and the agent is trained via policy gradient. We characterize this phenomenon through experiments on a simple maze setting and a more complex text-based game, and make recommendations for training RNNs with reinforcement learning.
From FiLM to Video: Multi-turn Question Answering with Multi-modal Context
Dec 17, 2018

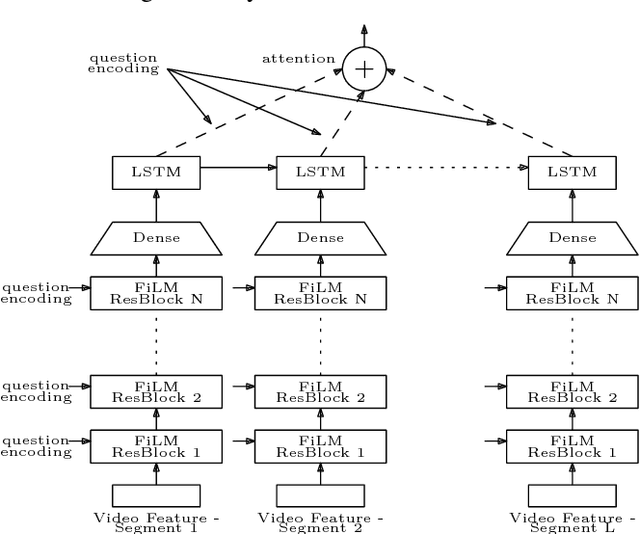
Understanding audio-visual content and the ability to have an informative conversation about it have both been challenging areas for intelligent systems. The Audio Visual Scene-aware Dialog (AVSD) challenge, organized as a track of the Dialog System Technology Challenge 7 (DSTC7), proposes a combined task, where a system has to answer questions pertaining to a video given a dialogue with previous question-answer pairs and the video itself. We propose for this task a hierarchical encoder-decoder model which computes a multi-modal embedding of the dialogue context. It first embeds the dialogue history using two LSTMs. We extract video and audio frames at regular intervals and compute semantic features using pre-trained I3D and VGGish models, respectively. Before summarizing both modalities into fixed-length vectors using LSTMs, we use FiLM blocks to condition them on the embeddings of the current question, which allows us to reduce the dimensionality considerably. Finally, we use an LSTM decoder that we train with scheduled sampling and evaluate using beam search. Compared to the modality-fusing baseline model released by the AVSD challenge organizers, our model achieves a relative improvements of more than 16%, scoring 0.36 BLEU-4 and more than 33%, scoring 0.997 CIDEr.
Towards Solving Text-based Games by Producing Adaptive Action Spaces
Dec 03, 2018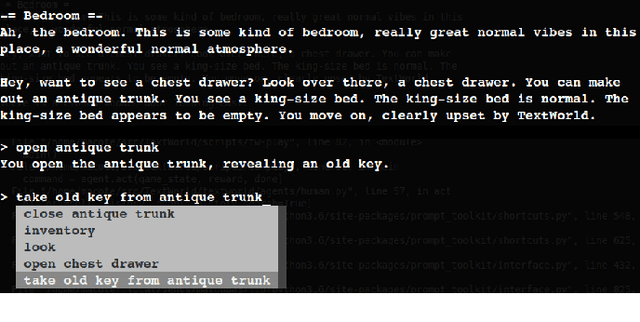


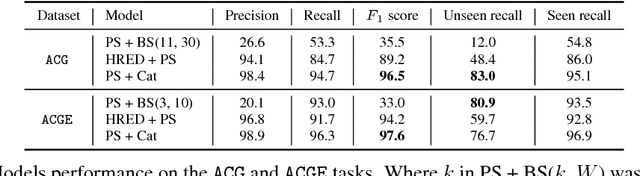
To solve a text-based game, an agent needs to formulate valid text commands for a given context and find the ones that lead to success. Recent attempts at solving text-based games with deep reinforcement learning have focused on the latter, i.e., learning to act optimally when valid actions are known in advance. In this work, we propose to tackle the first task and train a model that generates the set of all valid commands for a given context. We try three generative models on a dataset generated with Textworld. The best model can generate valid commands which were unseen at training and achieve high $F_1$ score on the test set.
Keep Drawing It: Iterative language-based image generation and editing
Nov 24, 2018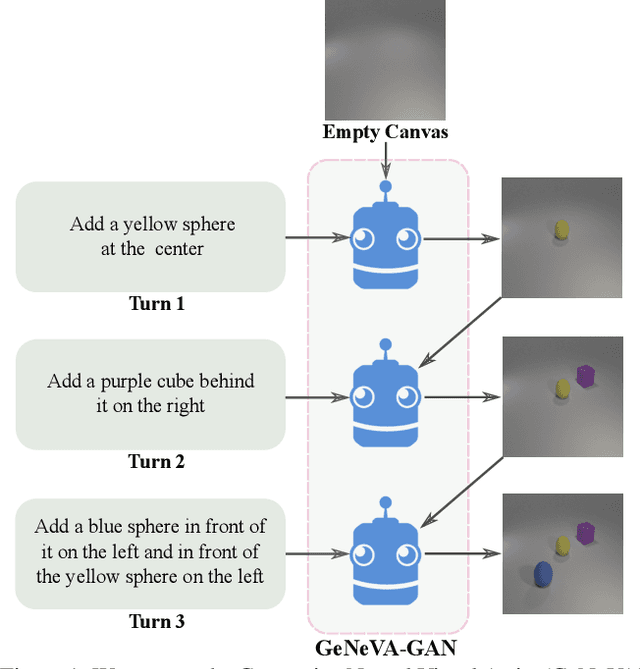


Conditional text-to-image generation approaches commonly focus on generating a single image in a single step. One practical extension beyond one-step generation is an interactive system that generates an image iteratively, conditioned on ongoing linguistic input / feedback. This is significantly more challenging as such a system must understand and keep track of the ongoing context and history. In this work, we present a recurrent image generation model which takes into account both the generated output up to the current step as well as all past instructions for generation. We show that our model is able to generate the background, add new objects, apply simple transformations to existing objects, and correct previous mistakes. We believe our approach is an important step toward interactive generation.
TextWorld: A Learning Environment for Text-based Games
Jun 29, 2018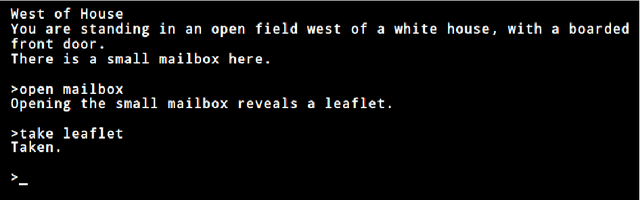
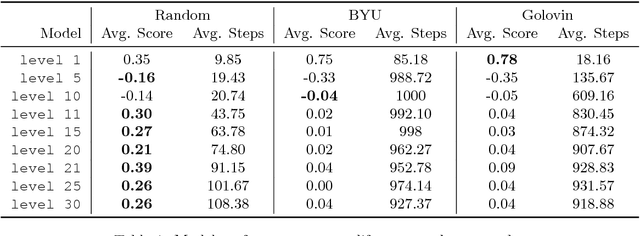

We introduce TextWorld, a sandbox learning environment for the training and evaluation of RL agents on text-based games. TextWorld is a Python library that handles interactive play-through of text games, as well as backend functions like state tracking and reward assignment. It comes with a curated list of games whose features and challenges we have analyzed. More significantly, it enables users to handcraft or automatically generate new games. Its generative mechanisms give precise control over the difficulty, scope, and language of constructed games, and can be used to relax challenges inherent to commercial text games like partial observability and sparse rewards. By generating sets of varied but similar games, TextWorld can also be used to study generalization and transfer learning. We cast text-based games in the Reinforcement Learning formalism, use our framework to develop a set of benchmark games, and evaluate several baseline agents on this set and the curated list.
Relevance of Unsupervised Metrics in Task-Oriented Dialogue for Evaluating Natural Language Generation
Jun 29, 2017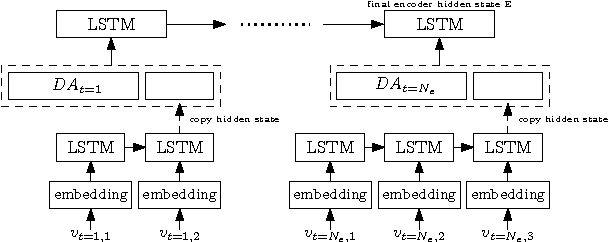

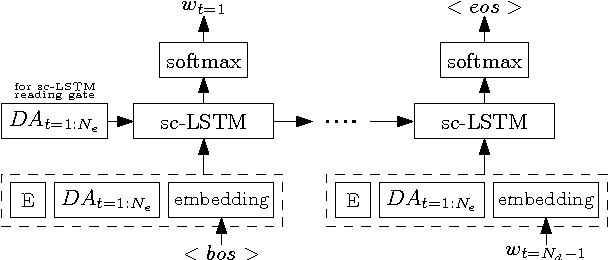
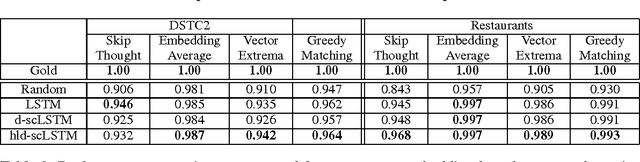
Automated metrics such as BLEU are widely used in the machine translation literature. They have also been used recently in the dialogue community for evaluating dialogue response generation. However, previous work in dialogue response generation has shown that these metrics do not correlate strongly with human judgment in the non task-oriented dialogue setting. Task-oriented dialogue responses are expressed on narrower domains and exhibit lower diversity. It is thus reasonable to think that these automated metrics would correlate well with human judgment in the task-oriented setting where the generation task consists of translating dialogue acts into a sentence. We conduct an empirical study to confirm whether this is the case. Our findings indicate that these automated metrics have stronger correlation with human judgments in the task-oriented setting compared to what has been observed in the non task-oriented setting. We also observe that these metrics correlate even better for datasets which provide multiple ground truth reference sentences. In addition, we show that some of the currently available corpora for task-oriented language generation can be solved with simple models and advocate for more challenging datasets.
A Frame Tracking Model for Memory-Enhanced Dialogue Systems
Jun 06, 2017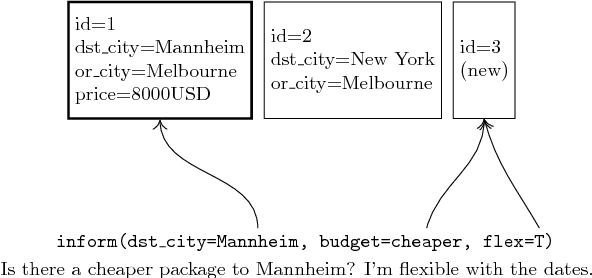

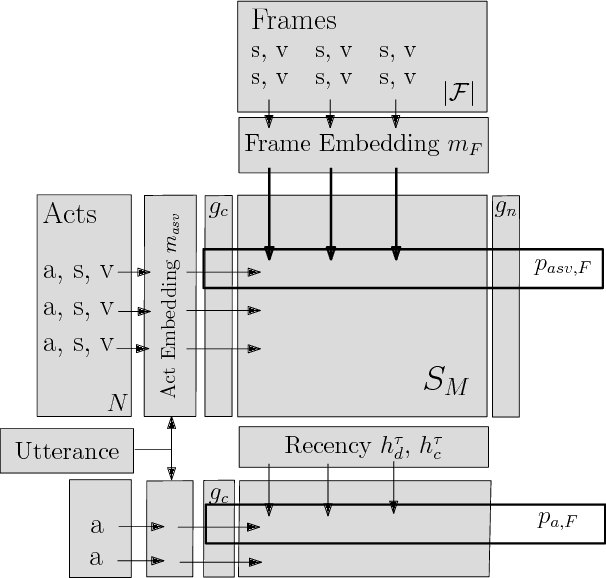

Recently, resources and tasks were proposed to go beyond state tracking in dialogue systems. An example is the frame tracking task, which requires recording multiple frames, one for each user goal set during the dialogue. This allows a user, for instance, to compare items corresponding to different goals. This paper proposes a model which takes as input the list of frames created so far during the dialogue, the current user utterance as well as the dialogue acts, slot types, and slot values associated with this utterance. The model then outputs the frame being referenced by each triple of dialogue act, slot type, and slot value. We show that on the recently published Frames dataset, this model significantly outperforms a previously proposed rule-based baseline. In addition, we propose an extensive analysis of the frame tracking task by dividing it into sub-tasks and assessing their difficulty with respect to our model.