 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Exposure Bias Matters: An Imitation Learning Perspective of Error Accumulation in Language Generation
Apr 03, 2022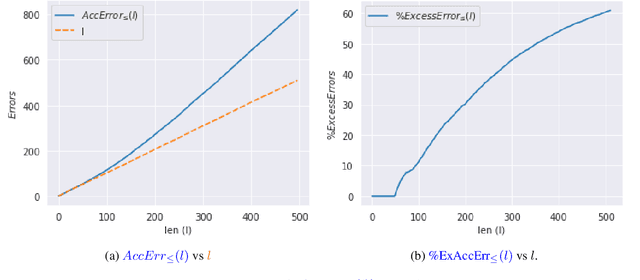
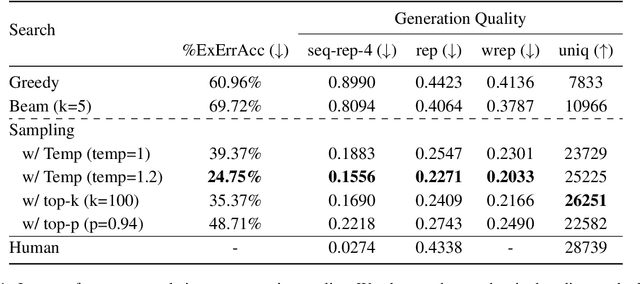
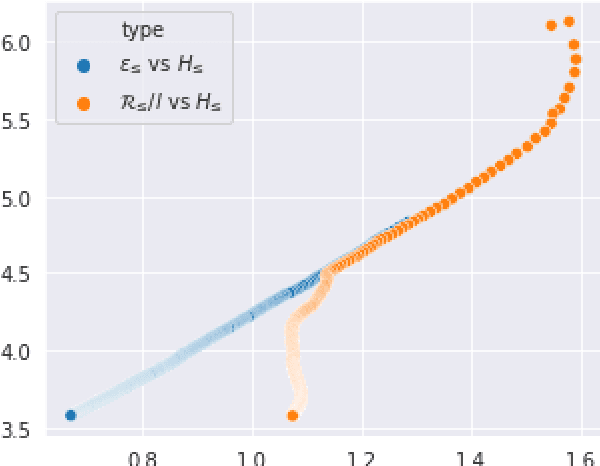
Current language generation models suffer from issues such as repetition, incoherence, and hallucinations. An often-repeated hypothesis is that this brittleness of generation models is caused by the training and the generation procedure mismatch, also referred to as exposure bias. In this paper, we verify this hypothesis by analyzing exposure bias from an imitation learning perspective. We show that exposure bias leads to an accumulation of errors, analyze why perplexity fails to capture this accumulation, and empirically show that this accumulation results in poor generation quality. Source code to reproduce these experiments is available at https://github.com/kushalarora/quantifying_exposure_bias
Diverse Keyphrase Generation with Neural Unlikelihood Training
Oct 15, 2020
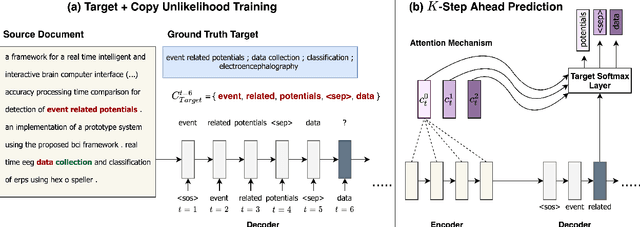

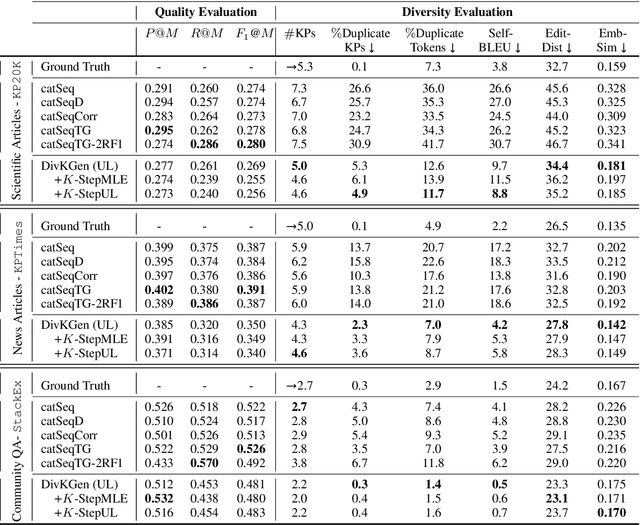
In this paper, we study sequence-to-sequence (S2S) keyphrase generation models from the perspective of diversity. Recent advances in neural natural language generation have made possible remarkable progress on the task of keyphrase generation, demonstrated through improvements on quality metrics such as F1-score. However, the importance of diversity in keyphrase generation has been largely ignored. We first analyze the extent of information redundancy present in the outputs generated by a baseline model trained using maximum likelihood estimation (MLE). Our findings show that repetition of keyphrases is a major issue with MLE training. To alleviate this issue, we adopt neural unlikelihood (UL) objective for training the S2S model. Our version of UL training operates at (1) the target token level to discourage the generation of repeating tokens; (2) the copy token level to avoid copying repetitive tokens from the source text. Further, to encourage better model planning during the decoding process, we incorporate K-step ahead token prediction objective that computes both MLE and UL losses on future tokens as well. Through extensive experiments on datasets from three different domains we demonstrate that the proposed approach attains considerably large diversity gains, while maintaining competitive output quality.
Polarized-VAE: Proximity Based Disentangled Representation Learning for Text Generation
Apr 22, 2020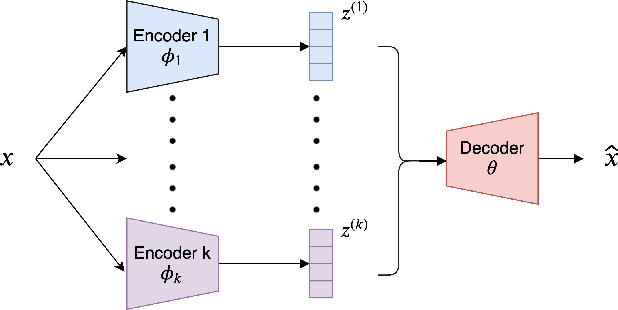
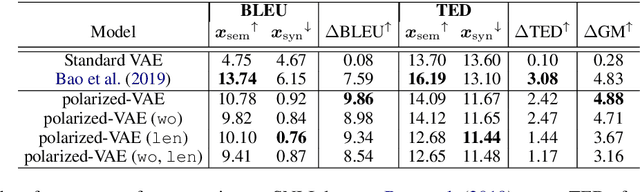


Learning disentangled representations of real world data is a challenging open problem. Most previous methods have focused on either fully supervised approaches which use attribute labels or unsupervised approaches that manipulate the factorization in the latent space of models such as the variational autoencoder (VAE), by training with task-specific losses. In this work we propose polarized-VAE, a novel approach that disentangles selected attributes in the latent space based on proximity measures reflecting the similarity between data points with respect to these attributes. We apply our method to disentangle the semantics and syntax of a sentence and carry out transfer experiments. Polarized-VAE significantly outperforms the VAE baseline and is competitive with the state-of-the-art approaches, while being more a general framework that is applicable to other attribute disentanglement tasks.
Generating lyrics with variational autoencoder and multi-modal artist embeddings
Dec 20, 2018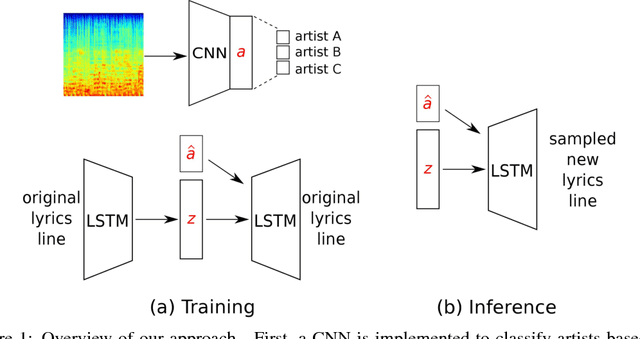
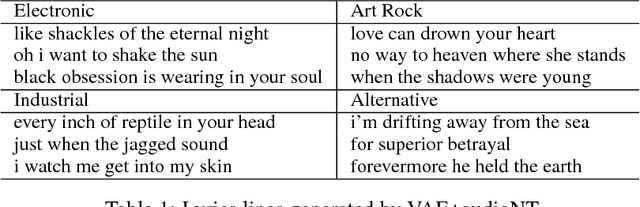
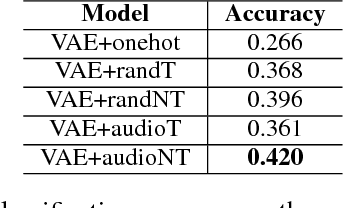
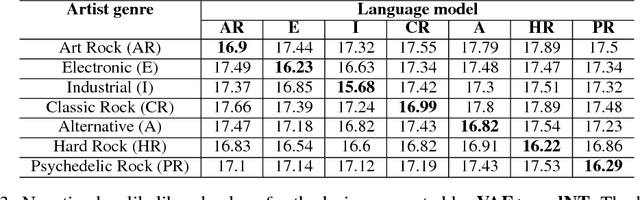
We present a system for generating song lyrics lines conditioned on the style of a specified artist. The system uses a variational autoencoder with artist embeddings. We propose the pre-training of artist embeddings with the representations learned by a CNN classifier, which is trained to predict artists based on MEL spectrograms of their song clips. This work is the first step towards combining audio and text modalities of songs for generating lyrics conditioned on the artist's style. Our preliminary results suggest that there is a benefit in initializing artists' embeddings with the representations learned by a spectrogram classifier.
Disentangled Representation Learning for Non-Parallel Text Style Transfer
Sep 11, 2018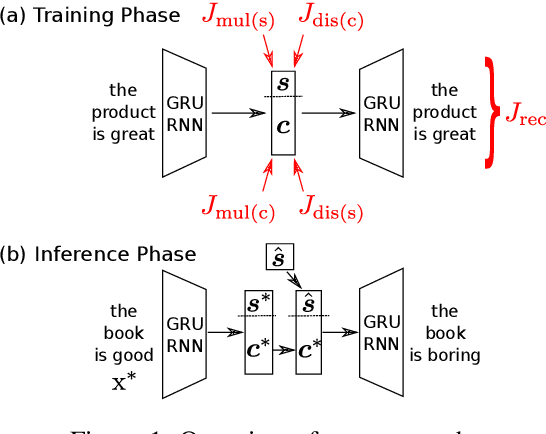
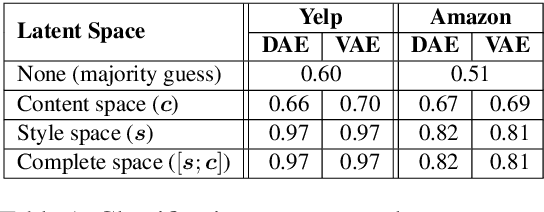
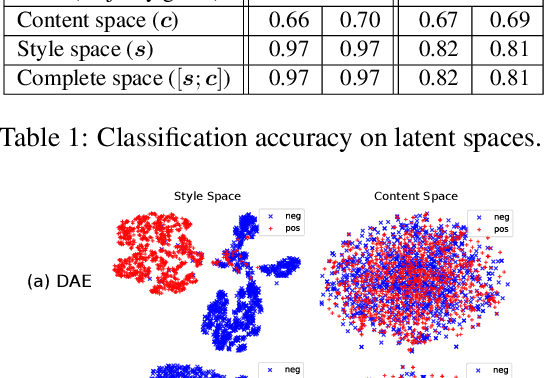
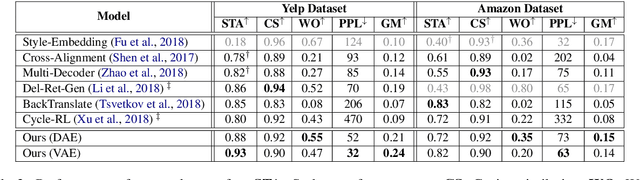
This paper tackles the problem of disentangling the latent variables of style and content in language models. We propose a simple yet effective approach, which incorporates auxiliary multi-task and adversarial objectives, for label prediction and bag-of-words prediction, respectively. We show, both qualitatively and quantitatively, that the style and content are indeed disentangled in the latent space. This disentangled latent representation learning method is applied to style transfer on non-parallel corpora. We achieve substantially better results in terms of transfer accuracy, content preservation and language fluency, in comparison to previous state-of-the-art approaches.
Natural Language Generation with Neural Variational Models
Aug 27, 2018
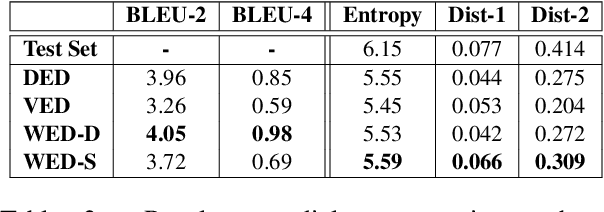
In this thesis, we explore the use of deep neural networks for generation of natural language. Specifically, we implement two sequence-to-sequence neural variational models - variational autoencoders (VAE) and variational encoder-decoders (VED). VAEs for text generation are difficult to train due to issues associated with the Kullback-Leibler (KL) divergence term of the loss function vanishing to zero. We successfully train VAEs by implementing optimization heuristics such as KL weight annealing and word dropout. We also demonstrate the effectiveness of this continuous latent space through experiments such as random sampling, linear interpolation and sampling from the neighborhood of the input. We argue that if VAEs are not designed appropriately, it may lead to bypassing connections which results in the latent space being ignored during training. We show experimentally with the example of decoder hidden state initialization that such bypassing connections degrade the VAE into a deterministic model, thereby reducing the diversity of generated sentences. We discover that the traditional attention mechanism used in sequence-to-sequence VED models serves as a bypassing connection, thereby deteriorating the model's latent space. In order to circumvent this issue, we propose the variational attention mechanism where the attention context vector is modeled as a random variable that can be sampled from a distribution. We show empirically using automatic evaluation metrics, namely entropy and distinct measures, that our variational attention model generates more diverse output sentences than the deterministic attention model. A qualitative analysis with human evaluation study proves that our model simultaneously produces sentences that are of high quality and equally fluent as the ones generated by the deterministic attention counterpart.
Probabilistic Natural Language Generation with Wasserstein Autoencoders
Jun 22, 2018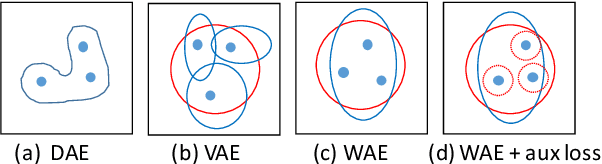
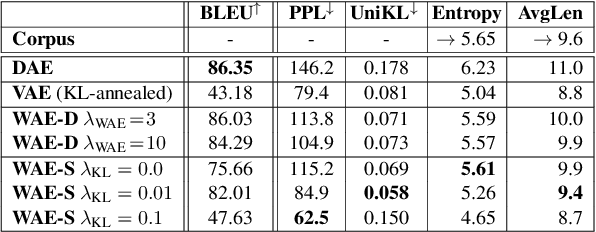
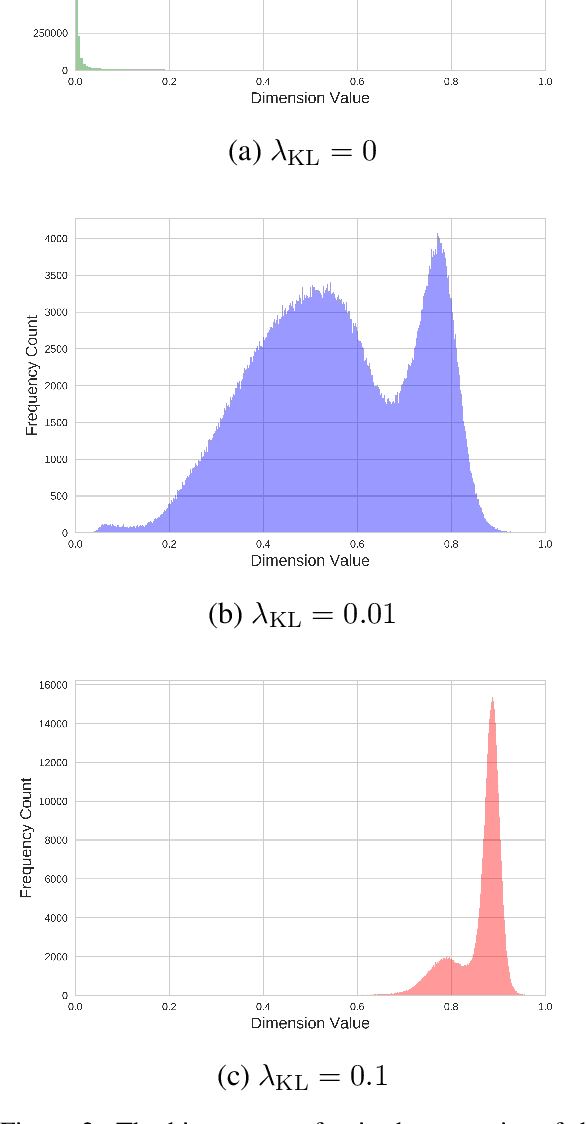
Probabilistic generation of natural language sentences is an important task in NLP. Existing models such as variational autoencoders (VAE) for sequence generation are extremely difficult to train due to the issues associated with the Kullback-Leibler (KL) loss collapsing to zero. One has to implement various heuristics such as KL weight annealing and word dropout in a carefully engineered manner to successfully train a text VAE. In this paper, we propose the use of Wasserstein autoencoders (WAE) for probabilistic natural language sentence generation. We show that sequence-to-sequence WAEs are more robust towards hyperparameters and can be trained in a straightforward manner without the need for any weight annealing. Empirical evidence shows that the latent space learned by WAEs exhibits properties of continuity and smoothness as in VAEs, while simultaneously achieving much higher BLEU scores for sentence reconstruction.
Variational Attention for Sequence-to-Sequence Models
Jun 21, 2018

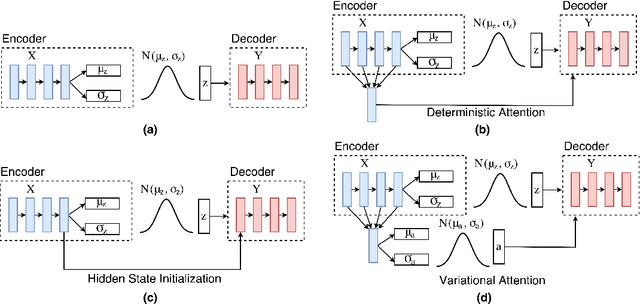
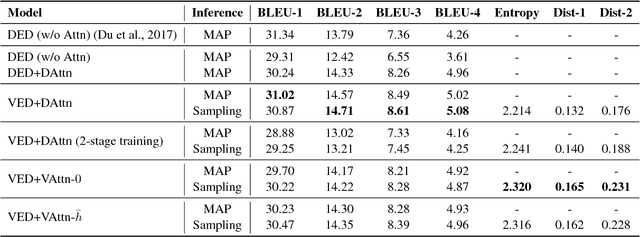
The variational encoder-decoder (VED) encodes source information as a set of random variables using a neural network, which in turn is decoded into target data using another neural network. In natural language processing, sequence-to-sequence (Seq2Seq) models typically serve as encoder-decoder networks. When combined with a traditional (deterministic) attention mechanism, the variational latent space may be bypassed by the attention model, and thus becomes ineffective. In this paper, we propose a variational attention mechanism for VED, where the attention vector is also modeled as Gaussian distributed random variables. Results on two experiments show that, without loss of quality, our proposed method alleviates the bypassing phenomenon as it increases the diversity of generated sentences.