 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Generation with Neural Variational Models
Paper and Code

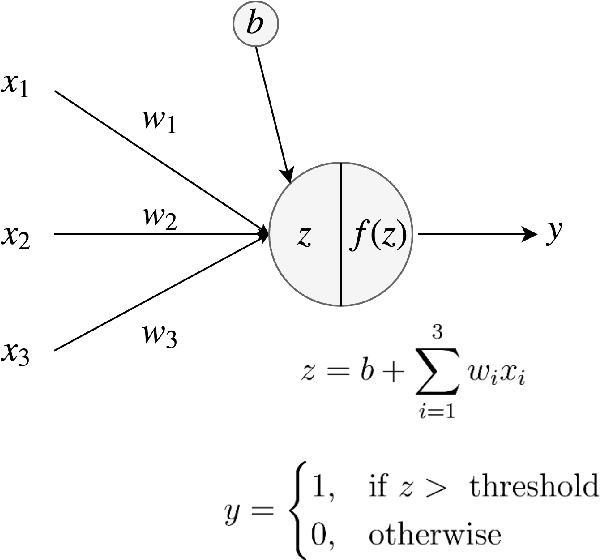
In this thesis, we explore the use of deep neural networks for generation of natural language. Specifically, we implement two sequence-to-sequence neural variational models - variational autoencoders (VAE) and variational encoder-decoders (VED). VAEs for text generation are difficult to train due to issues associated with the Kullback-Leibler (KL) divergence term of the loss function vanishing to zero. We successfully train VAEs by implementing optimization heuristics such as KL weight annealing and word dropout. We also demonstrate the effectiveness of this continuous latent space through experiments such as random sampling, linear interpolation and sampling from the neighborhood of the input. We argue that if VAEs are not designed appropriately, it may lead to bypassing connections which results in the latent space being ignored during training. We show experimentally with the example of decoder hidden state initialization that such bypassing connections degrade the VAE into a deterministic model, thereby reducing the diversity of generated sentences. We discover that the traditional attention mechanism used in sequence-to-sequence VED models serves as a bypassing connection, thereby deteriorating the model's latent space. In order to circumvent this issue, we propose the variational attention mechanism where the attention context vector is modeled as a random variable that can be sampled from a distribution. We show empirically using automatic evaluation metrics, namely entropy and distinct measures, that our variational attention model generates more diverse output sentences than the deterministic attention model. A qualitative analysis with human evaluation study proves that our model simultaneously produces sentences that are of high quality and equally fluent as the ones generated by the deterministic attention counterpart.